 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models on Computer Science University Exams in Data Structures
Apr 25, 2026We present a comprehensive evaluation of Large Language Models (LLMs) on Computer Science (CS) Data Structure examination questions. Our work introduces a new benchmark dataset comprising exam questions from Tel Aviv University (TAU), curated to assess LLMs' abilities in handling closed and multiple-choice questions. We evaluated the performance of OpenAI's GPT 4o and Anthropic's Claude 3.5, popular LLMs, alongside two smaller LLMs, Mathstral 7B and LLaMA 3 8B, across the TAU exams benchmark. Our findings provide insight into the current capabilities of LLMs in CS education.
We Should Separate Memorization from Copyright
Feb 09, 2026The widespread use of foundation models has introduced a new risk factor of copyright issue. This issue is leading to an active, lively and on-going debate amongst the data-science community as well as amongst legal scholars. Where claims and results across both sides are often interpreted in different ways and leading to different implications. Our position is that much of the technical literature relies on traditional reconstruction techniques that are not designed for copyright analysis. As a result, memorization and copying have been conflated across both technical and legal communities and in multiple contexts. We argue that memorization, as commonly studied in data science, should not be equated with copying and should not be used as a proxy for copyright infringement. We distinguish technical signals that meaningfully indicate infringement risk from those that instead reflect lawful generalization or high-frequency content. Based on this analysis, we advocate for an output-level, risk-based evaluation process that aligns technical assessments with established copyright standards and provides a more principled foundation for research, auditing, and policy.
CARLoS: Retrieval via Concise Assessment Representation of LoRAs at Scale
Dec 09, 2025



The rapid proliferation of generative components, such as LoRAs, has created a vast but unstructured ecosystem. Existing discovery methods depend on unreliable user descriptions or biased popularity metrics, hindering usability. We present CARLoS, a large-scale framework for characterizing LoRAs without requiring additional metadata. Analyzing over 650 LoRAs, we employ them in image generation over a variety of prompts and seeds, as a credible way to assess their behavior. Using CLIP embeddings and their difference to a base-model generation, we concisely define a three-part representation: Directions, defining semantic shift; Strength, quantifying the significance of the effect; and Consistency, quantifying how stable the effect is. Using these representations, we develop an efficient retrieval framework that semantically matches textual queries to relevant LoRAs while filtering overly strong or unstable ones, outperforming textual baselines in automated and human evaluations. While retrieval is our primary focus, the same representation also supports analyses linking Strength and Consistency to legal notions of substantiality and volition, key considerations in copyright, positioning CARLoS as a practical system with broader relevance for LoRA analysis.
ComfyGen: Prompt-Adaptive Workflows for Text-to-Image Generation
Oct 02, 2024



The practical use of text-to-image generation has evolved from simple, monolithic models to complex workflows that combine multiple specialized components. While workflow-based approaches can lead to improved image quality, crafting effective workflows requires significant expertise, owing to the large number of available components, their complex inter-dependence, and their dependence on the generation prompt. Here, we introduce the novel task of prompt-adaptive workflow generation, where the goal is to automatically tailor a workflow to each user prompt. We propose two LLM-based approaches to tackle this task: a tuning-based method that learns from user-preference data, and a training-free method that uses the LLM to select existing flows. Both approaches lead to improved image quality when compared to monolithic models or generic, prompt-independent workflows. Our work shows that prompt-dependent flow prediction offers a new pathway to improving text-to-image generation quality, complementing existing research directions in the field.
Not Every Image is Worth a Thousand Words: Quantifying Originality in Stable Diffusion
Aug 15, 2024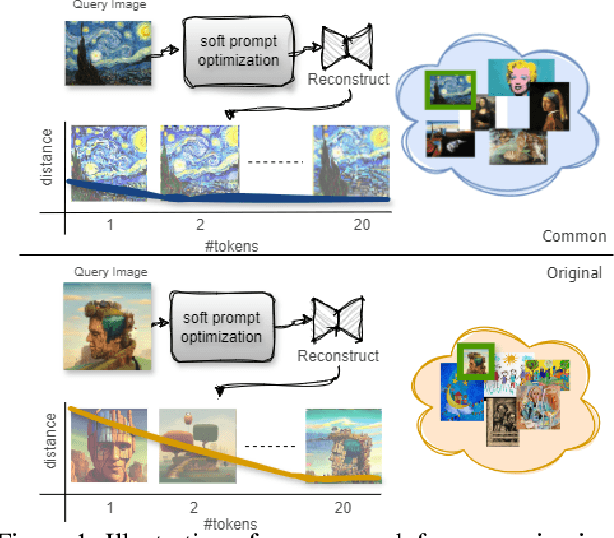

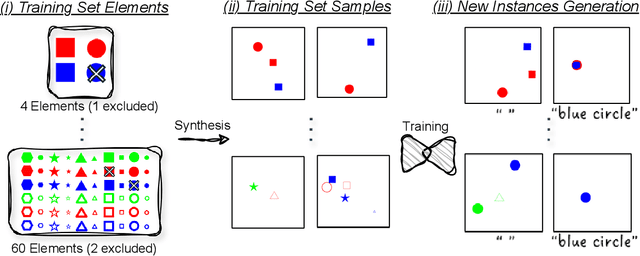
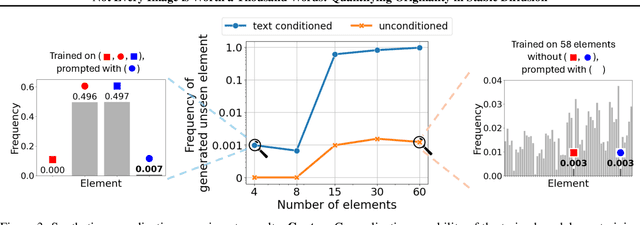
This work addresses the challenge of quantifying originality in text-to-image (T2I) generative diffusion models, with a focus on copyright originality. We begin by evaluating T2I models' ability to innovate and generalize through controlled experiments, revealing that stable diffusion models can effectively recreate unseen elements with sufficiently diverse training data. Then, our key insight is that concepts and combinations of image elements the model is familiar with, and saw more during training, are more concisly represented in the model's latent space. We hence propose a method that leverages textual inversion to measure the originality of an image based on the number of tokens required for its reconstruction by the model. Our approach is inspired by legal definitions of originality and aims to assess whether a model can produce original content without relying on specific prompts or having the training data of the model. We demonstrate our method using both a pre-trained stable diffusion model and a synthetic dataset, showing a correlation between the number of tokens and image originality. This work contributes to the understanding of originality in generative models and has implications for copyright infringement cases.
Not All Similarities Are Created Equal: Leveraging Data-Driven Biases to Inform GenAI Copyright Disputes
Mar 26, 2024

The advent of Generative Artificial Intelligence (GenAI) models, including GitHub Copilot, OpenAI GPT, and Stable Diffusion, has revolutionized content creation, enabling non-professionals to produce high-quality content across various domains. This transformative technology has led to a surge of synthetic content and sparked legal disputes over copyright infringement. To address these challenges, this paper introduces a novel approach that leverages the learning capacity of GenAI models for copyright legal analysis, demonstrated with GPT2 and Stable Diffusion models. Copyright law distinguishes between original expressions and generic ones (Sc\`enes \`a faire), protecting the former and permitting reproduction of the latter. However, this distinction has historically been challenging to make consistently, leading to over-protection of copyrighted works. GenAI offers an unprecedented opportunity to enhance this legal analysis by revealing shared patterns in preexisting works. We propose a data-driven approach to identify the genericity of works created by GenAI, employing "data-driven bias" to assess the genericity of expressive compositions. This approach aids in copyright scope determination by utilizing the capabilities of GenAI to identify and prioritize expressive elements and rank them according to their frequency in the model's dataset. The potential implications of measuring expressive genericity for copyright law are profound. Such scoring could assist courts in determining copyright scope during litigation, inform the registration practices of Copyright Offices, allowing registration of only highly original synthetic works, and help copyright owners signal the value of their works and facilitate fairer licensing deals. More generally, this approach offers valuable insights to policymakers grappling with adapting copyright law to the challenges posed by the era of GenAI.
OMG-ATTACK: Self-Supervised On-Manifold Generation of Transferable Evasion Attacks
Oct 05, 2023



Evasion Attacks (EA) are used to test the robustness of trained neural networks by distorting input data to misguide the model into incorrect classifications. Creating these attacks is a challenging task, especially with the ever-increasing complexity of models and datasets. In this work, we introduce a self-supervised, computationally economical method for generating adversarial examples, designed for the unseen black-box setting. Adapting techniques from representation learning, our method generates on-manifold EAs that are encouraged to resemble the data distribution. These attacks are comparable in effectiveness compared to the state-of-the-art when attacking the model trained on, but are significantly more effective when attacking unseen models, as the attacks are more related to the data rather than the model itself. Our experiments consistently demonstrate the method is effective across various models, unseen data categories, and even defended models, suggesting a significant role for on-manifold EAs when targeting unseen models.
Understanding Transformer Memorization Recall Through Idioms
Oct 11, 2022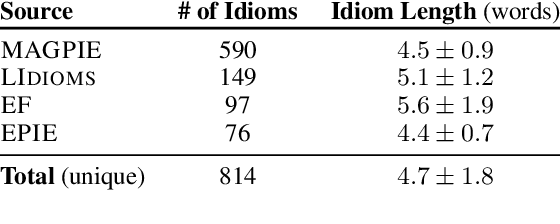
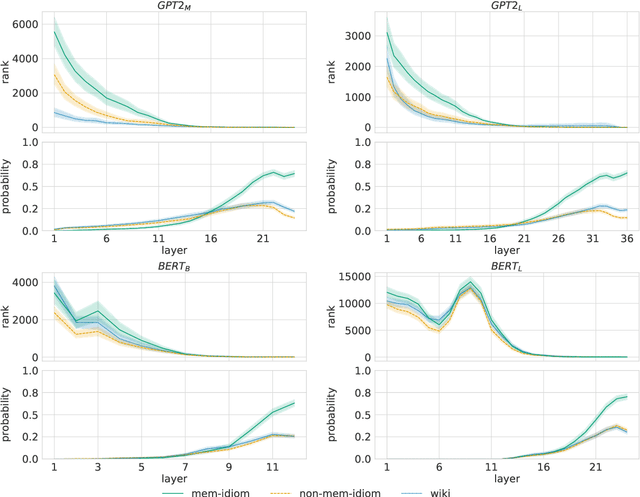
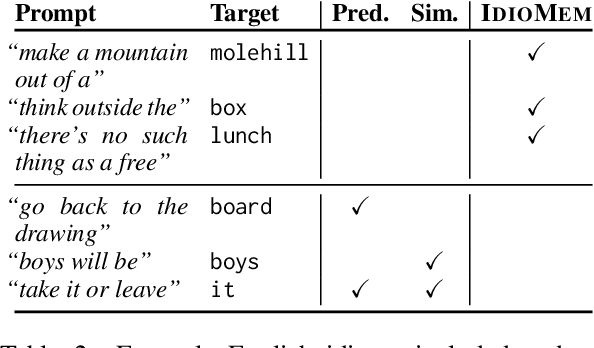
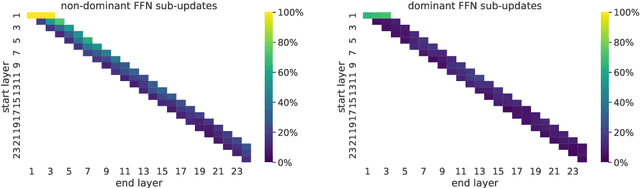
To produce accurate predictions, language models (LMs) must balance between generalization and memorization. Yet, little is known about the mechanism by which transformer LMs employ their memorization capacity. When does a model decide to output a memorized phrase, and how is this phrase then retrieved from memory? In this work, we offer the first methodological framework for probing and characterizing recall of memorized sequences in transformer LMs. First, we lay out criteria for detecting model inputs that trigger memory recall, and propose idioms as inputs that fulfill these criteria. Next, we construct a dataset of English idioms and use it to compare model behavior on memorized vs. non-memorized inputs. Specifically, we analyze the internal prediction construction process by interpreting the model's hidden representations as a gradual refinement of the output probability distribution. We find that across different model sizes and architectures, memorized predictions are a two-step process: early layers promote the predicted token to the top of the output distribution, and upper layers increase model confidence. This suggests that memorized information is stored and retrieved in the early layers of the network. Last, we demonstrate the utility of our methodology beyond idioms in memorized factual statements. Overall, our work makes a first step towards understanding memory recall, and provides a methodological basis for future studies of transformer memorization.
Transformer Language Models without Positional Encodings Still Learn Positional Information
Mar 30, 2022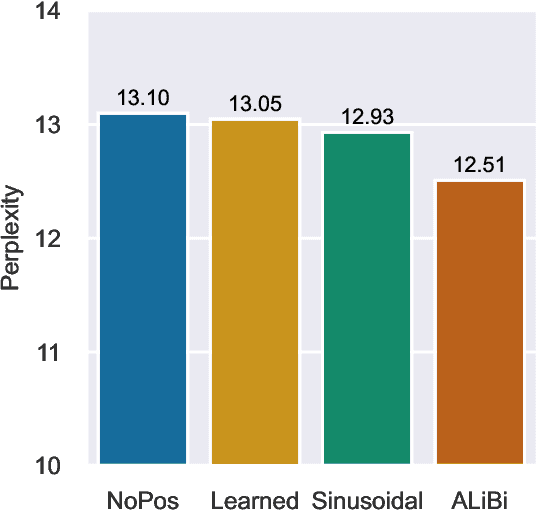
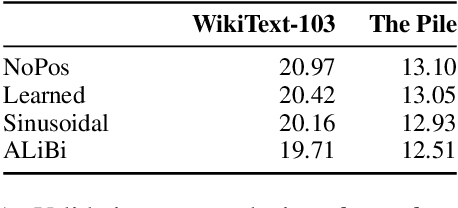
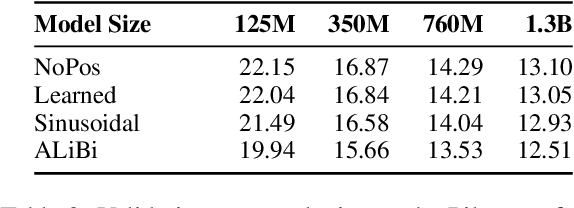
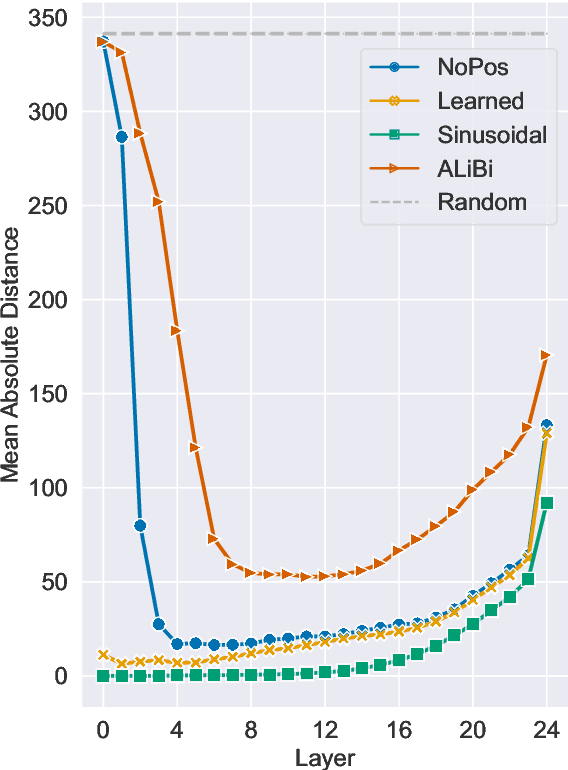
Transformers typically require some form of positional encoding, such as positional embeddings, to process natural language sequences. Surprisingly, we find that transformer language models without any explicit positional encoding are still competitive with standard models, and that this phenomenon is robust across different datasets, model sizes, and sequence lengths. Probing experiments reveal that such models acquire an implicit notion of absolute positions throughout the network, effectively compensating for the missing information. We conjecture that causal attention enables the model to infer the number of predecessors that each token can attend to, thereby approximating its absolute position.
SCROLLS: Standardized CompaRison Over Long Language Sequences
Jan 10, 2022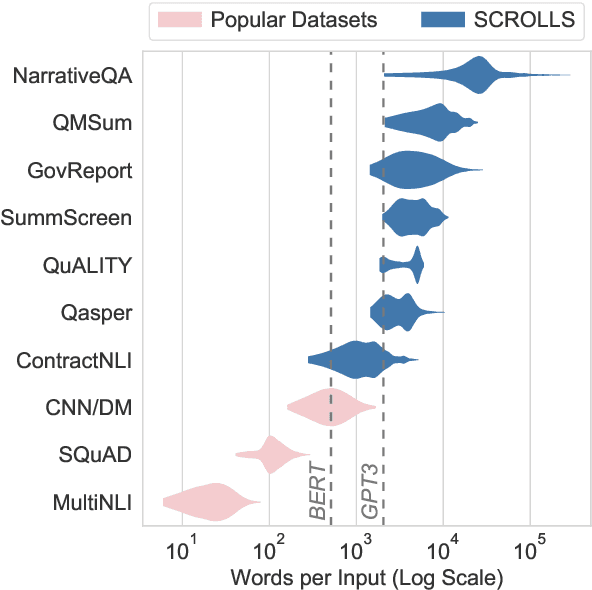
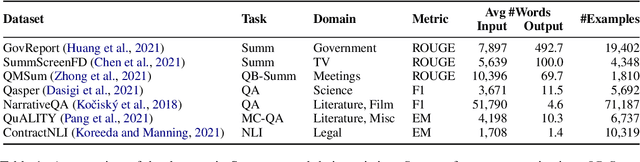

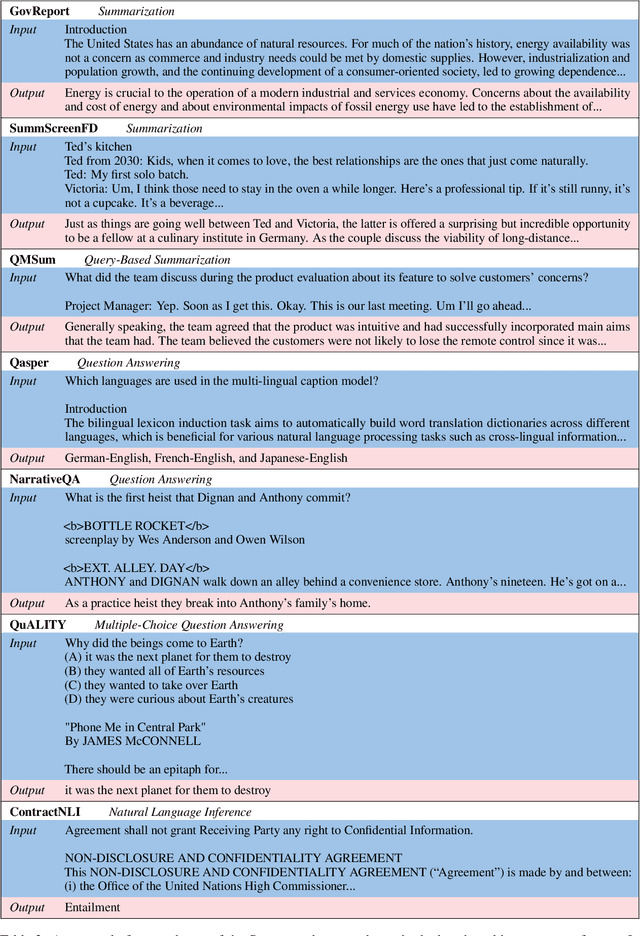
NLP benchmarks have largely focused on short texts, such as sentences and paragraphs, even though long texts comprise a considerable amount of natural language in the wild. We introduce SCROLLS, a suite of tasks that require reasoning over long texts. We examine existing long-text datasets, and handpick ones where the text is naturally long, while prioritizing tasks that involve synthesizing information across the input. SCROLLS contains summarization, question answering, and natural language inference tasks, covering multiple domains, including literature, science, business, and entertainment. Initial baselines, including Longformer Encoder-Decoder, indicate that there is ample room for improvement on SCROLLS. We make all datasets available in a unified text-to-text format and host a live leaderboard to facilitate research on model architecture and pretraining methods.