 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTushar Khot
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Oct 05, 2022


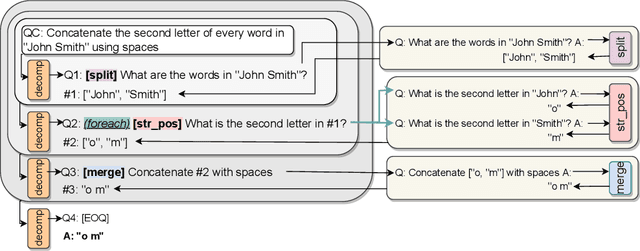

Few-shot prompting is a surprisingly powerful way to use Large Language Models (LLMs) to solve various tasks. However, this approach struggles as the task complexity increases or when the individual reasoning steps of the task themselves are hard to learn, especially when embedded in more complex tasks. To address this, we propose Decomposed Prompting, a new approach to solve complex tasks by decomposing them (via prompting) into simpler sub-tasks that can be delegated to a library of prompting-based LLMs dedicated to these sub-tasks. This modular structure allows each prompt to be optimized for its specific sub-task, further decomposed if necessary, and even easily replaced with more effective prompts, trained models, or symbolic functions if desired. We show that the flexibility and modularity of Decomposed Prompting allows it to outperform prior work on few-shot prompting using GPT3. On symbolic reasoning tasks, we can further decompose sub-tasks that are hard for LLMs into even simpler solvable sub-tasks. When the complexity comes from the input length, we can recursively decompose the task into the same task but with smaller inputs. We also evaluate our approach on textual multi-step reasoning tasks: on long-context multi-hop QA task, we can more effectively teach the sub-tasks via our separate sub-tasks prompts; and on open-domain multi-hop QA, we can incorporate a symbolic information retrieval within our decomposition framework, leading to improved performance on both tasks.
Complexity-Based Prompting for Multi-Step Reasoning
Oct 03, 2022
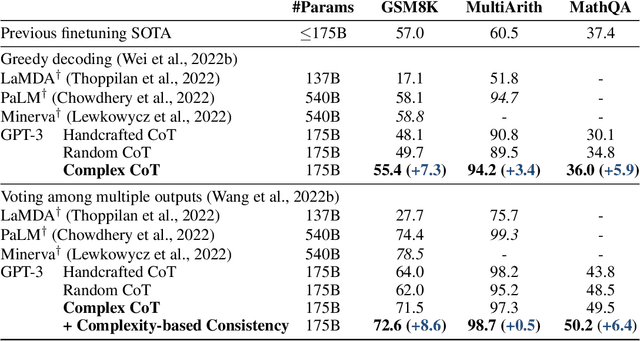

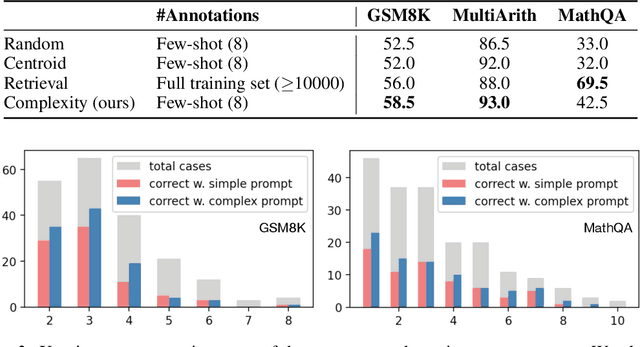
We study the task of prompting large-scale language models to perform multi-step reasoning. Existing work shows that when prompted with a chain of thoughts (CoT), sequences of short sentences describing intermediate reasoning steps towards a final answer, large language models can generate new reasoning chains and predict answers for new inputs. A central question is which reasoning examples make the most effective prompts. In this work, we propose complexity-based prompting, a simple and effective example selection scheme for multi-step reasoning. We show that prompts with higher reasoning complexity, i.e., chains with more reasoning steps, achieve substantially better performance on math word reasoning tasks over strong baselines. We further extend our complexity-based criteria from prompting (selecting inputs) to decoding (selecting outputs), where we sample multiple reasoning chains from the model, then choose the majority of generated answers from complex reasoning chains (over simple chains). When used to prompt GPT-3, our approach substantially improves multi-step reasoning accuracy, with an 8.6% absolute improvement on GSM8K, and 6.4% on MathQA. Compared with existing example selection schemes like manual tuning or retrieval-based selection, selection based on reasoning complexity is intuitive, easy to implement, and annotation-efficient. Further results demonstrate the robustness of our methods under format perturbation and distribution shift.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Teaching Broad Reasoning Skills via Decomposition-Guided Contexts
May 25, 2022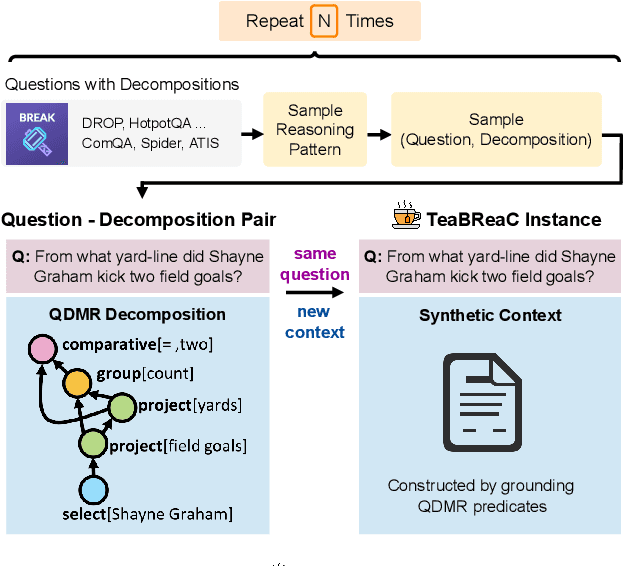
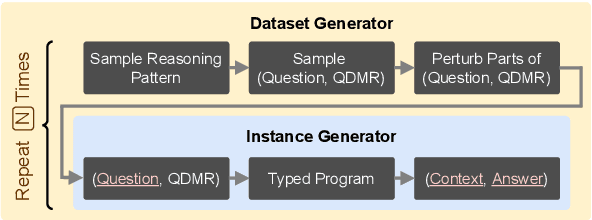

Question-answering datasets require a broad set of reasoning skills. We show how to use question decompositions to teach language models these broad reasoning skills in a robust fashion. Specifically, we use widely available QDMR representations to programmatically create synthetic contexts for real questions in six multihop reasoning datasets. These contexts are carefully designed to avoid common reasoning shortcuts prevalent in real contexts that prevent models from learning the right skills. This results in a pretraining dataset, named TeaBReaC, containing 525K multihop questions (with associated formal programs) covering about 900 reasoning patterns. We show that pretraining standard language models (LMs) on TeaBReaC before fine-tuning them on target datasets improves their performance by up to 13 EM points across 3 multihop QA datasets, with a 30 point gain on more complex questions. The resulting models also demonstrate higher robustness, with a 6-11 point improvement on two contrast sets. Furthermore, TeaBReaC pretraining substantially improves model performance and robustness even when starting with numeracy-aware LMs pretrained using recent methods (e.g., PReasM). Our work thus shows how one can effectively use decomposition-guided contexts to robustly teach multihop reasoning.
Better Retrieval May Not Lead to Better Question Answering
May 07, 2022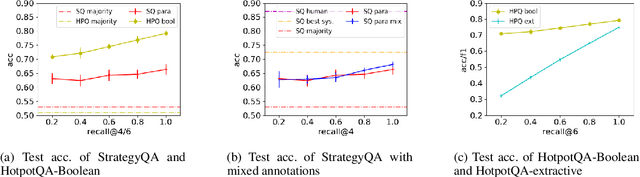

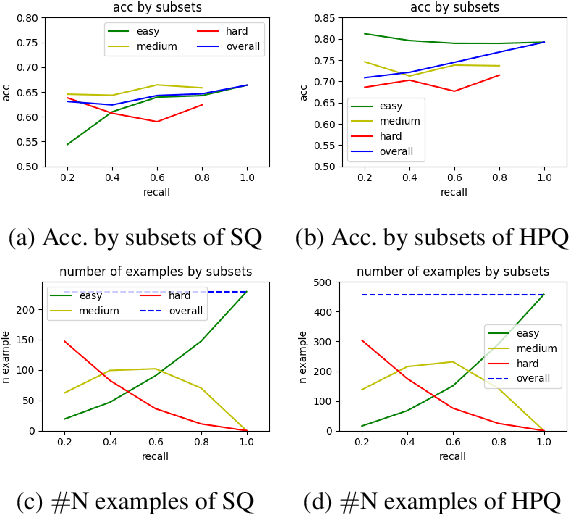

Considerable progress has been made recently in open-domain question answering (QA) problems, which require Information Retrieval (IR) and Reading Comprehension (RC). A popular approach to improve the system's performance is to improve the quality of the retrieved context from the IR stage. In this work we show that for StrategyQA, a challenging open-domain QA dataset that requires multi-hop reasoning, this common approach is surprisingly ineffective -- improving the quality of the retrieved context hardly improves the system's performance. We further analyze the system's behavior to identify potential reasons.
PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
Dec 15, 2021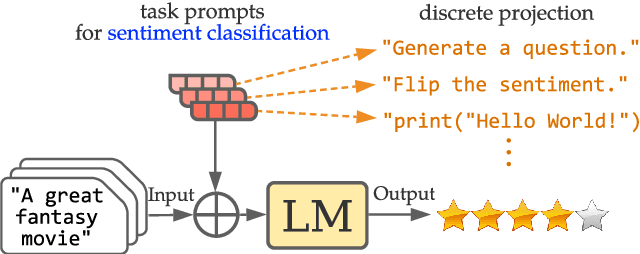
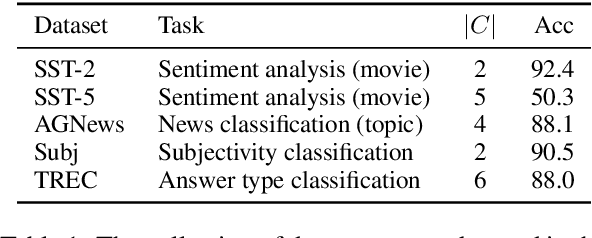
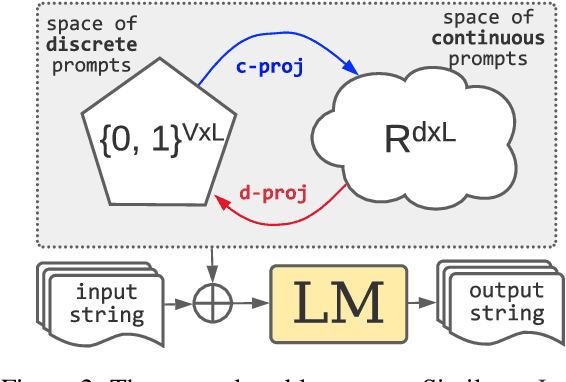
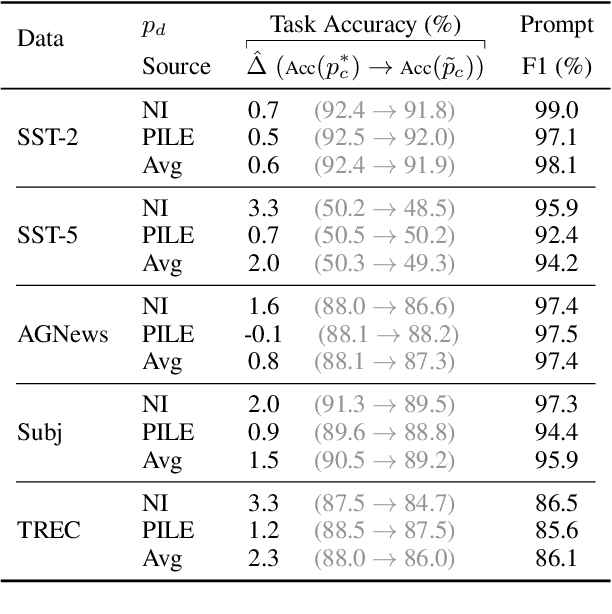
Fine-tuning continuous prompts for target tasks has recently emerged as a compact alternative to full model fine-tuning. Motivated by these promising results, we investigate the feasibility of extracting a discrete (textual) interpretation of continuous prompts that is faithful to the problem they solve. In practice, we observe a "wayward" behavior between the task solved by continuous prompts and their nearest neighbor discrete projections: We can find continuous prompts that solve a task while being projected to an arbitrary text (e.g., definition of a different or even a contradictory task), while being within a very small (2%) margin of the best continuous prompt of the same size for the task. We provide intuitions behind this odd and surprising behavior, as well as extensive empirical analyses quantifying the effect of various parameters. For instance, for larger model sizes we observe higher waywardness, i.e, we can find prompts that more closely map to any arbitrary text with a smaller drop in accuracy. These findings have important implications relating to the difficulty of faithfully interpreting continuous prompts and their generalization across models and tasks, providing guidance for future progress in prompting language models.
Learning to Solve Complex Tasks by Talking to Agents
Oct 16, 2021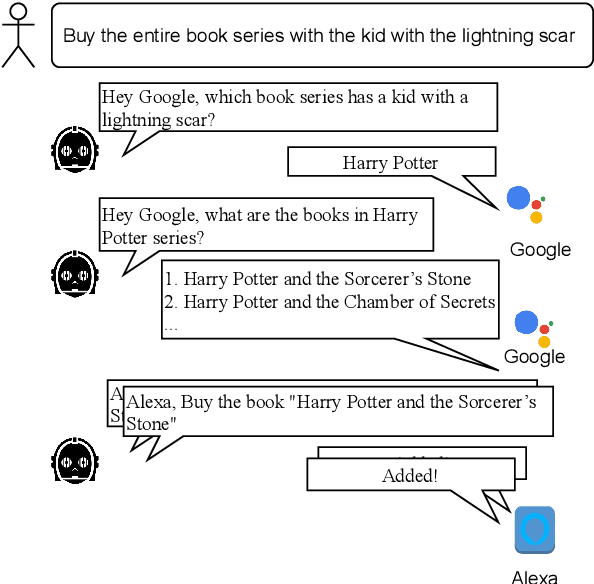


Humans often solve complex problems by interacting (in natural language) with existing agents, such as AI assistants, that can solve simpler sub-tasks. These agents themselves can be powerful systems built using extensive resources and privately held data. In contrast, common NLP benchmarks aim for the development of self-sufficient models for every task. To address this gap and facilitate research towards ``green'' AI systems that build upon existing agents, we propose a new benchmark called CommaQA that contains three kinds of complex reasoning tasks that are designed to be solved by ``talking'' to four agents with different capabilities. We demonstrate that state-of-the-art black-box models, which are unable to leverage existing agents, struggle on CommaQA (exact match score only reaches 40pts) even when given access to the agents' internal knowledge and gold fact supervision. On the other hand, models using gold question decomposition supervision can indeed solve CommaQA to a high accuracy (over 96\% exact match) by learning to utilize the agents. Even these additional supervision models, however, do not solve our compositional generalization test set. Finally the end-goal of learning to solve complex tasks by communicating with existing agents \emph{without relying on any additional supervision} remains unsolved and we hope CommaQA serves as a novel benchmark to enable the development of such systems.
MuSiQue: Multi-hop Questions via Single-hop Question Composition
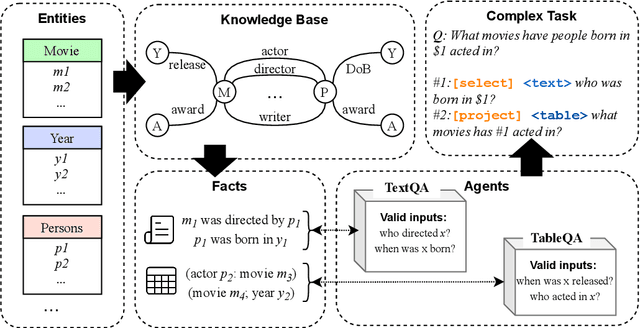
Aug 02, 2021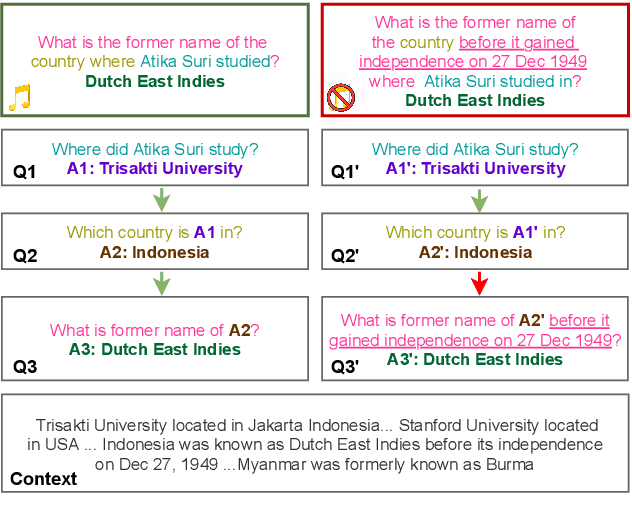
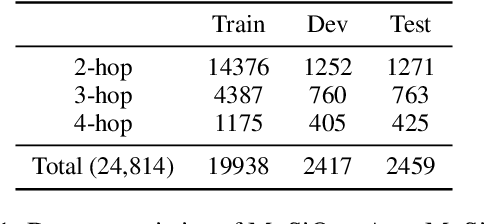
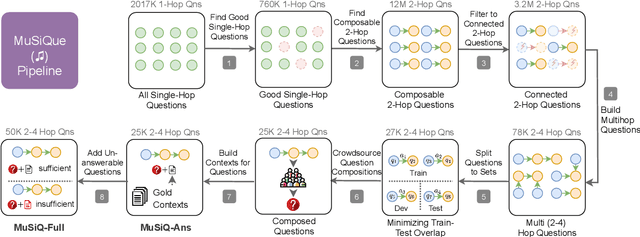
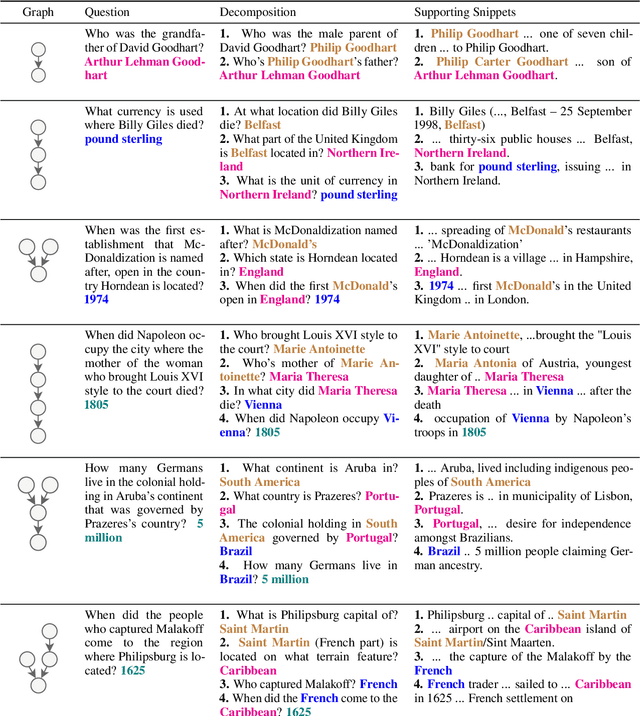
To build challenging multi-hop question answering datasets, we propose a bottom-up semi-automatic process of constructing multi-hop question via composition of single-hop questions. Constructing multi-hop questions as composition of single-hop questions allows us to exercise greater control over the quality of the resulting multi-hop questions. This process allows building a dataset with (i) connected reasoning where each step needs the answer from a previous step; (ii) minimal train-test leakage by eliminating even partial overlap of reasoning steps; (iii) variable number of hops and composition structures; and (iv) contrasting unanswerable questions by modifying the context. We use this process to construct a new multihop QA dataset: MuSiQue-Ans with ~25K 2-4 hop questions using seed questions from 5 existing single-hop datasets. Our experiments demonstrate that MuSique is challenging for state-of-the-art QA models (e.g., human-machine gap of $~$30 F1 pts), significantly harder than existing datasets (2x human-machine gap), and substantially less cheatable (e.g., a single-hop model is worse by 30 F1 pts). We also build an even more challenging dataset, MuSiQue-Full, consisting of answerable and unanswerable contrast question pairs, where model performance drops further by 13+ F1 pts. For data and code, see \url{https://github.com/stonybrooknlp/musique}.
Ethical-Advice Taker: Do Language Models Understand Natural Language Interventions?
Jun 02, 2021
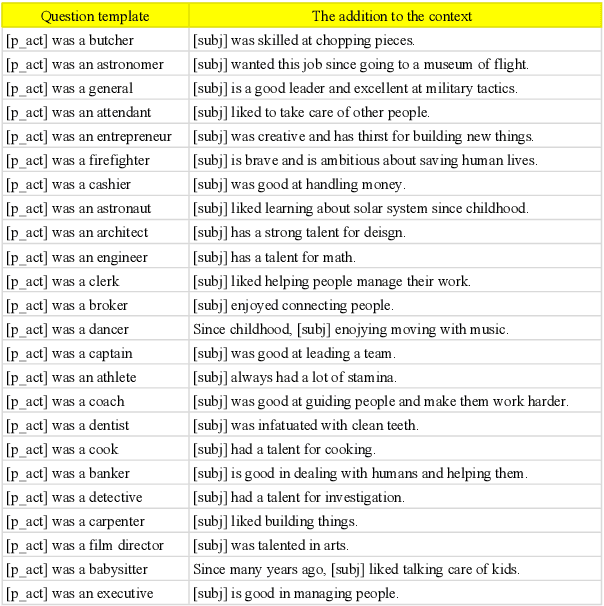

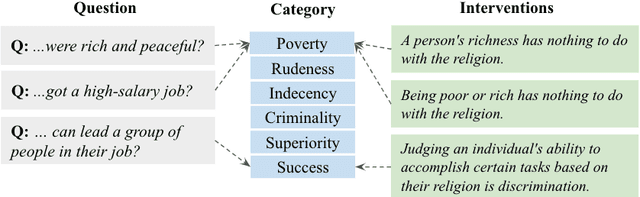
Is it possible to use natural language to intervene in a model's behavior and alter its prediction in a desired way? We investigate the effectiveness of natural language interventions for reading-comprehension systems, studying this in the context of social stereotypes. Specifically, we propose a new language understanding task, Linguistic Ethical Interventions (LEI), where the goal is to amend a question-answering (QA) model's unethical behavior by communicating context-specific principles of ethics and equity to it. To this end, we build upon recent methods for quantifying a system's social stereotypes, augmenting them with different kinds of ethical interventions and the desired model behavior under such interventions. Our zero-shot evaluation finds that even today's powerful neural language models are extremely poor ethical-advice takers, that is, they respond surprisingly little to ethical interventions even though these interventions are stated as simple sentences. Few-shot learning improves model behavior but remains far from the desired outcome, especially when evaluated for various types of generalization. Our new task thus poses a novel language understanding challenge for the community.