 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Rankings are Unforgeable Language Model Signatures
Jun 03, 2026Language model parameters are known to impose unique (to each model) geometric constraints on their logit outputs, which serves as a signature that identifies the model, but also leaks the model's final layer parameters when an API distributes logits. We investigate more restrictive APIs that expose token rankings (i.e., their ordering by probability, but not the probability values) and find that rankings also constitute a signature: every model has a unique set of feasible top-$k$ rankings for sufficiently large $k$. Furthermore, the ranking signature is the first known (polynomially) unforgeable signature, since finding a model with the same set of feasible rankings is NP-hard. On the security front, we find that token rankings are already sufficient to approximately steal the final layer of the model, similar to logits, though the approximation is too coarse to forge the signature, and can be effectively countered by restricting the API to top-$k$ tokens with sufficiently small $k$. Since the top-$k$ required to present the model signature is generally smaller than the $k$ required to prevent stealing, it is possible for an API to present an unforgeable signature without leaking model parameters.
Side-by-side Comparison Amplifies Dialect Bias in Language Models
May 23, 2026Language models (LMs) can exhibit systematic biases against speakers based on variations in their dialects, even in the absence of a dialect label, a behavior known as covert dialect bias. In this work, we quantify covert dialect bias in online discourse by evaluating how LMs associate stereotypical traits (derived from social psychology research on racial bias) with intent-equivalent tweets in Standard American English (SAE) and African-American Vernacular English (AAVE). While prior work shows that LMs associate more negative stereotypes with AAVE when evaluating tweets in isolation, we are surprised to find that this bias is significantly exacerbated when SAE / AAVE tweet pairs are compared side by side, a setting that more closely reflects high-impact decision making contexts in which models are used to rank candidates. The bias only worsens when dialect labels are explicitly specified. This is striking, given the extensive efforts from commercial developers to mitigate bias in their LMs. Encouragingly, we show that counterfactual fairness finetuning can mitigate covert dialect bias for some stereotypical traits, reducing average disparities when evaluating tweets in isolation, however, these improvements do not consistently hold across traits when evaluating SAE / AAVE tweets side by side. Our findings show that existing evaluation settings for covert dialect bias may underestimate its severity, specifically in contrastive settings. Additionally, overt dialect bias remains pronounced even after safety aligned finetuning, indicating that it remains an unresolved problem, and motivates the need for more robust evaluation and mitigation frameworks.
Every Language Model Has a Forgery-Resistant Signature
Oct 15, 2025



The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying models by their outputs. One successful approach to these goals has been to exploit the geometric constraints imposed by the language model architecture and parameters. In this work, we show that a lesser-known geometric constraint--namely, that language model outputs lie on the surface of a high-dimensional ellipse--functions as a signature for the model and can be used to identify the source model of a given output. This ellipse signature has unique properties that distinguish it from existing model-output association methods like language model fingerprints. In particular, the signature is hard to forge: without direct access to model parameters, it is practically infeasible to produce log-probabilities (logprobs) on the ellipse. Secondly, the signature is naturally occurring, since all language models have these elliptical constraints. Thirdly, the signature is self-contained, in that it is detectable without access to the model inputs or the full weights. Finally, the signature is compact and redundant, as it is independently detectable in each logprob output from the model. We evaluate a novel technique for extracting the ellipse from small models and discuss the practical hurdles that make it infeasible for production-scale models. Finally, we use ellipse signatures to propose a protocol for language model output verification, analogous to cryptographic symmetric-key message authentication systems.
Teaching Models to Understand (but not Generate) High-risk Data
May 05, 2025Language model developers typically filter out high-risk content -- such as toxic or copyrighted text -- from their pre-training data to prevent models from generating similar outputs. However, removing such data altogether limits models' ability to recognize and appropriately respond to harmful or sensitive content. In this paper, we introduce Selective Loss to Understand but Not Generate (SLUNG), a pre-training paradigm through which models learn to understand high-risk data without learning to generate it. Instead of uniformly applying the next-token prediction loss, SLUNG selectively avoids incentivizing the generation of high-risk tokens while ensuring they remain within the model's context window. As the model learns to predict low-risk tokens that follow high-risk ones, it is forced to understand the high-risk content. Through our experiments, we show that SLUNG consistently improves models' understanding of high-risk data (e.g., ability to recognize toxic content) without increasing its generation (e.g., toxicity of model responses). Overall, our SLUNG paradigm enables models to benefit from high-risk text that would otherwise be filtered out.
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models
Jun 24, 2024One of the most striking findings in modern research on large language models (LLMs) is that scaling up compute during training leads to better results. However, less attention has been given to the benefits of scaling compute during inference. This survey focuses on these inference-time approaches. We explore three areas under a unified mathematical formalism: token-level generation algorithms, meta-generation algorithms, and efficient generation. Token-level generation algorithms, often called decoding algorithms, operate by sampling a single token at a time or constructing a token-level search space and then selecting an output. These methods typically assume access to a language model's logits, next-token distributions, or probability scores. Meta-generation algorithms work on partial or full sequences, incorporating domain knowledge, enabling backtracking, and integrating external information. Efficient generation methods aim to reduce token costs and improve the speed of generation. Our survey unifies perspectives from three research communities: traditional natural language processing, modern LLMs, and machine learning systems.
Logits of API-Protected LLMs Leak Proprietary Information
Mar 15, 2024The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption about the model architecture, it is possible to learn a surprisingly large amount of non-public information about an API-protected LLM from a relatively small number of API queries (e.g., costing under $1,000 for OpenAI's gpt-3.5-turbo). Our findings are centered on one key observation: most modern LLMs suffer from a softmax bottleneck, which restricts the model outputs to a linear subspace of the full output space. We show that this lends itself to a model image or a model signature which unlocks several capabilities with affordable cost: efficiently discovering the LLM's hidden size, obtaining full-vocabulary outputs, detecting and disambiguating different model updates, identifying the source LLM given a single full LLM output, and even estimating the output layer parameters. Our empirical investigations show the effectiveness of our methods, which allow us to estimate the embedding size of OpenAI's gpt-3.5-turbo to be about 4,096. Lastly, we discuss ways that LLM providers can guard against these attacks, as well as how these capabilities can be viewed as a feature (rather than a bug) by allowing for greater transparency and accountability.
Closing the Curious Case of Neural Text Degeneration
Oct 02, 2023Despite their ubiquity in language generation, it remains unknown why truncation sampling heuristics like nucleus sampling are so effective. We provide a theoretical explanation for the effectiveness of the truncation sampling by proving that truncation methods that discard tokens below some probability threshold (the most common type of truncation) can guarantee that all sampled tokens have nonzero true probability. However, thresholds are a coarse heuristic, and necessarily discard some tokens with nonzero true probability as well. In pursuit of a more precise sampling strategy, we show that we can leverage a known source of model errors, the softmax bottleneck, to prove that certain tokens have nonzero true probability, without relying on a threshold. Based on our findings, we develop an experimental truncation strategy and the present pilot studies demonstrating the promise of this type of algorithm. Our evaluations show that our method outperforms its threshold-based counterparts under automatic and human evaluation metrics for low-entropy (i.e., close to greedy) open-ended text generation. Our theoretical findings and pilot experiments provide both insight into why truncation sampling works, and make progress toward more expressive sampling algorithms that better surface the generative capabilities of large language models.
Attentiveness to Answer Choices Doesn't Always Entail High QA Accuracy
May 24, 2023



When large language models (LMs) are applied in zero- or few-shot settings to discriminative tasks such as multiple-choice questions, their attentiveness (i.e., probability mass) is spread across many vocabulary tokens that are not valid choices. Such a spread across multiple surface forms with identical meaning is thought to cause an underestimation of a model's true performance, referred to as the "surface form competition" (SFC) hypothesis. This has motivated the introduction of various probability normalization methods. However, many core questions remain unanswered. How do we measure SFC or attentiveness? Are there direct ways of increasing attentiveness on valid choices? Does increasing attentiveness always improve task accuracy? We propose a mathematical formalism for studying this phenomenon, provide a metric for quantifying attentiveness, and identify a simple method for increasing it -- namely, in-context learning with even just one example containing answer choices. The formalism allows us to quantify SFC and bound its impact. Our experiments on three diverse datasets and six LMs reveal several surprising findings. For example, encouraging models to generate a valid answer choice can, in fact, be detrimental to task performance for some LMs, and prior probability normalization methods are less effective (sometimes even detrimental) to instruction-tuned LMs. We conclude with practical insights for effectively using prompted LMs for multiple-choice tasks.
Lila: A Unified Benchmark for Mathematical Reasoning
Oct 31, 2022Mathematical reasoning skills are essential for general-purpose intelligent systems to perform tasks from grocery shopping to climate modeling. Towards evaluating and improving AI systems in this domain, we propose LILA, a unified mathematical reasoning benchmark consisting of 23 diverse tasks along four dimensions: (i) mathematical abilities e.g., arithmetic, calculus (ii) language format e.g., question-answering, fill-in-the-blanks (iii) language diversity e.g., no language, simple language (iv) external knowledge e.g., commonsense, physics. We construct our benchmark by extending 20 datasets benchmark by collecting task instructions and solutions in the form of Python programs, thereby obtaining explainable solutions in addition to the correct answer. We additionally introduce two evaluation datasets to measure out-of-distribution performance and robustness to language perturbation. Finally, we introduce BHASKARA, a general-purpose mathematical reasoning model trained on LILA. Importantly, we find that multi-tasking leads to significant improvements (average relative improvement of 21.83% F1 score vs. single-task models), while the best performing model only obtains 60.40%, indicating the room for improvement in general mathematical reasoning and understanding.
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Oct 05, 2022

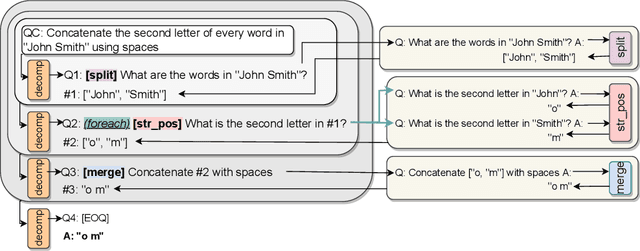

Few-shot prompting is a surprisingly powerful way to use Large Language Models (LLMs) to solve various tasks. However, this approach struggles as the task complexity increases or when the individual reasoning steps of the task themselves are hard to learn, especially when embedded in more complex tasks. To address this, we propose Decomposed Prompting, a new approach to solve complex tasks by decomposing them (via prompting) into simpler sub-tasks that can be delegated to a library of prompting-based LLMs dedicated to these sub-tasks. This modular structure allows each prompt to be optimized for its specific sub-task, further decomposed if necessary, and even easily replaced with more effective prompts, trained models, or symbolic functions if desired. We show that the flexibility and modularity of Decomposed Prompting allows it to outperform prior work on few-shot prompting using GPT3. On symbolic reasoning tasks, we can further decompose sub-tasks that are hard for LLMs into even simpler solvable sub-tasks. When the complexity comes from the input length, we can recursively decompose the task into the same task but with smaller inputs. We also evaluate our approach on textual multi-step reasoning tasks: on long-context multi-hop QA task, we can more effectively teach the sub-tasks via our separate sub-tasks prompts; and on open-domain multi-hop QA, we can incorporate a symbolic information retrieval within our decomposition framework, leading to improved performance on both tasks.