 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKen Goldberg
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023
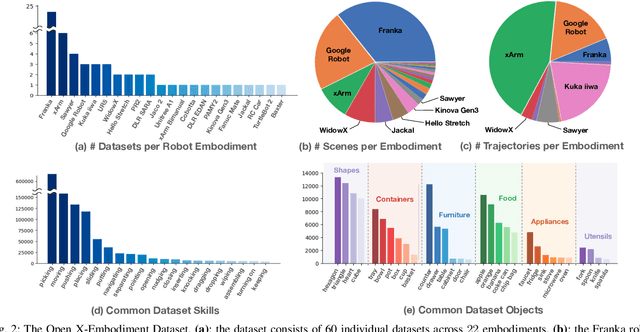
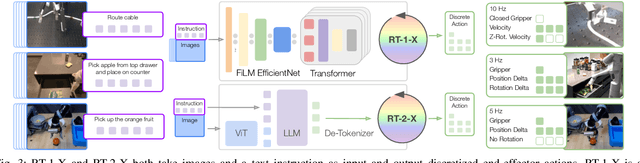
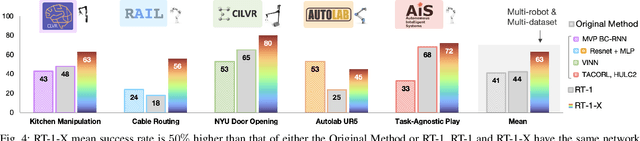

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping
Sep 18, 2023
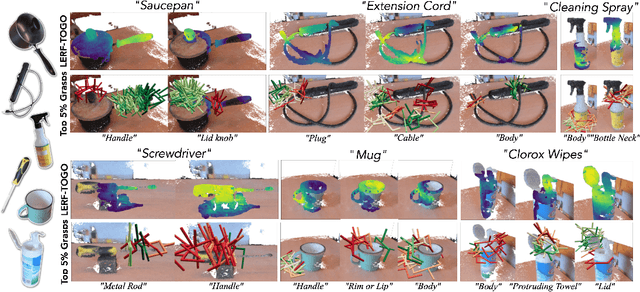

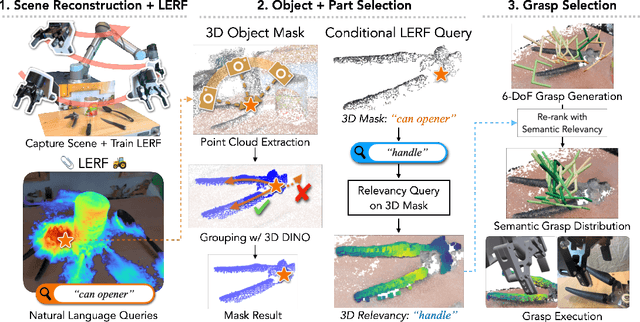
Grasping objects by a specific part is often crucial for safety and for executing downstream tasks. Yet, learning-based grasp planners lack this behavior unless they are trained on specific object part data, making it a significant challenge to scale object diversity. Instead, we propose LERF-TOGO, Language Embedded Radiance Fields for Task-Oriented Grasping of Objects, which uses vision-language models zero-shot to output a grasp distribution over an object given a natural language query. To accomplish this, we first reconstruct a LERF of the scene, which distills CLIP embeddings into a multi-scale 3D language field queryable with text. However, LERF has no sense of objectness, meaning its relevancy outputs often return incomplete activations over an object which are insufficient for subsequent part queries. LERF-TOGO mitigates this lack of spatial grouping by extracting a 3D object mask via DINO features and then conditionally querying LERF on this mask to obtain a semantic distribution over the object with which to rank grasps from an off-the-shelf grasp planner. We evaluate LERF-TOGO's ability to grasp task-oriented object parts on 31 different physical objects, and find it selects grasps on the correct part in 81% of all trials and grasps successfully in 69%. See the project website at: lerftogo.github.io
Self-Supervised Learning for Interactive Perception of Surgical Thread for Autonomous Suture Tail-Shortening
Jul 13, 2023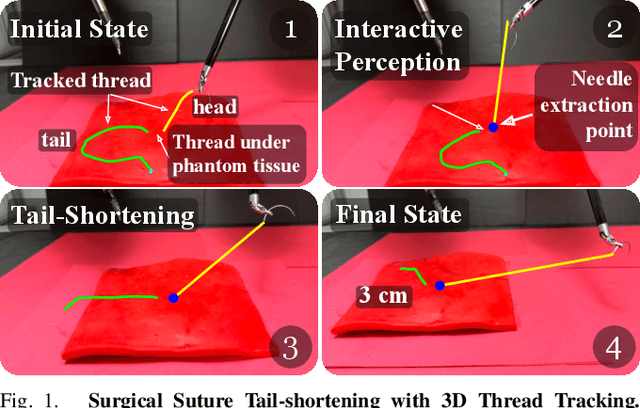
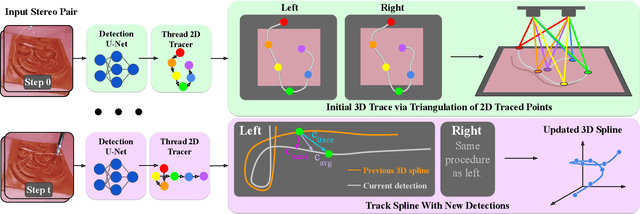

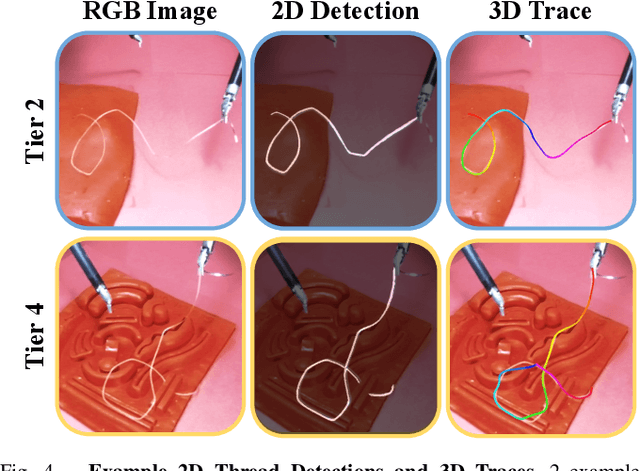
Accurate 3D sensing of suturing thread is a challenging problem in automated surgical suturing because of the high state-space complexity, thinness and deformability of the thread, and possibility of occlusion by the grippers and tissue. In this work we present a method for tracking surgical thread in 3D which is robust to occlusions and complex thread configurations, and apply it to autonomously perform the surgical suture "tail-shortening" task: pulling thread through tissue until a desired "tail" length remains exposed. The method utilizes a learned 2D surgical thread detection network to segment suturing thread in RGB images. It then identifies the thread path in 2D and reconstructs the thread in 3D as a NURBS spline by triangulating the detections from two stereo cameras. Once a 3D thread model is initialized, the method tracks the thread across subsequent frames. Experiments suggest the method achieves a 1.33 pixel average reprojection error on challenging single-frame 3D thread reconstructions, and an 0.84 pixel average reprojection error on two tracking sequences. On the tail-shortening task, it accomplishes a 90% success rate across 20 trials. Supplemental materials are available at https://sites.google.com/berkeley.edu/autolab-surgical-thread/ .
The Busboy Problem: Efficient Tableware Decluttering Using Consolidation and Multi-Object Grasps
Jul 08, 2023

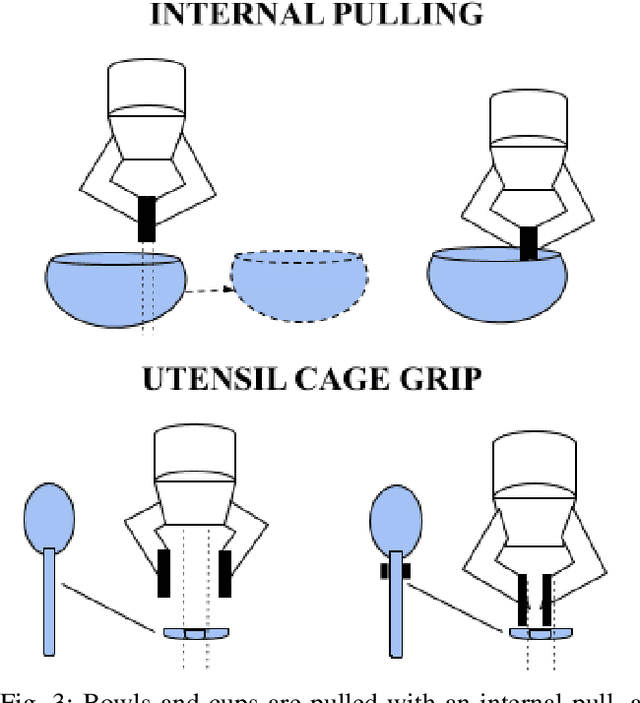
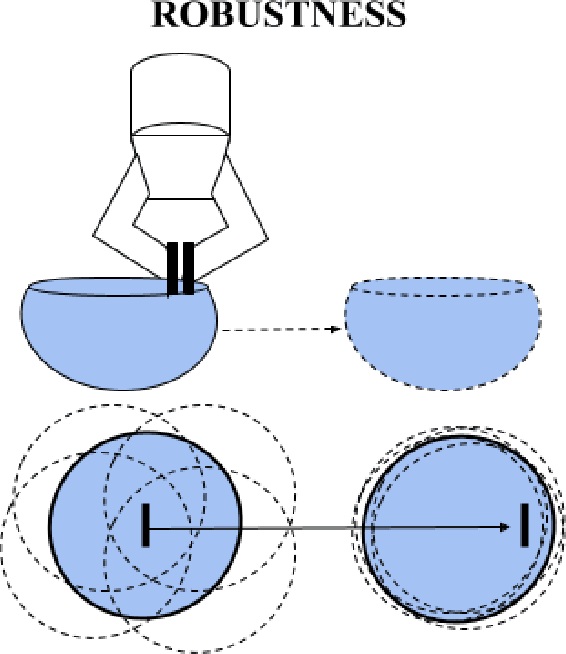
We present the "Busboy Problem": automating an efficient decluttering of cups, bowls, and silverware from a planar surface. As grasping and transporting individual items is highly inefficient, we propose policies to generate grasps for multiple items. We introduce the metric of Objects per Trip (OpT) carried by the robot to the collection bin to analyze the improvement seen as a result of our policies. In physical experiments with singulated items, we find that consolidation and multi-object grasps resulted in an 1.8x improvement in OpT, compared to methods without multi-object grasps. See https://sites.google.com/berkeley.edu/busboyproblem for code and supplemental materials.
Can Machines Garden? Systematically Comparing the AlphaGarden vs. Professional Horticulturalists
Jun 29, 2023

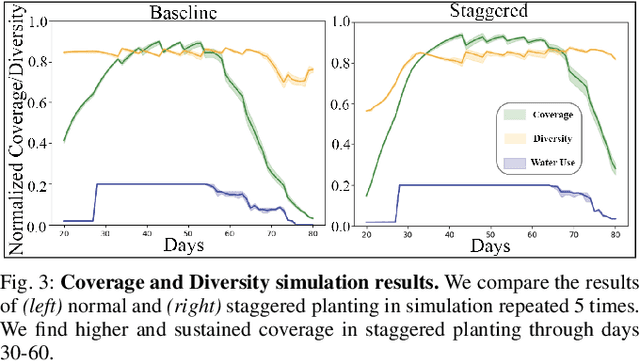
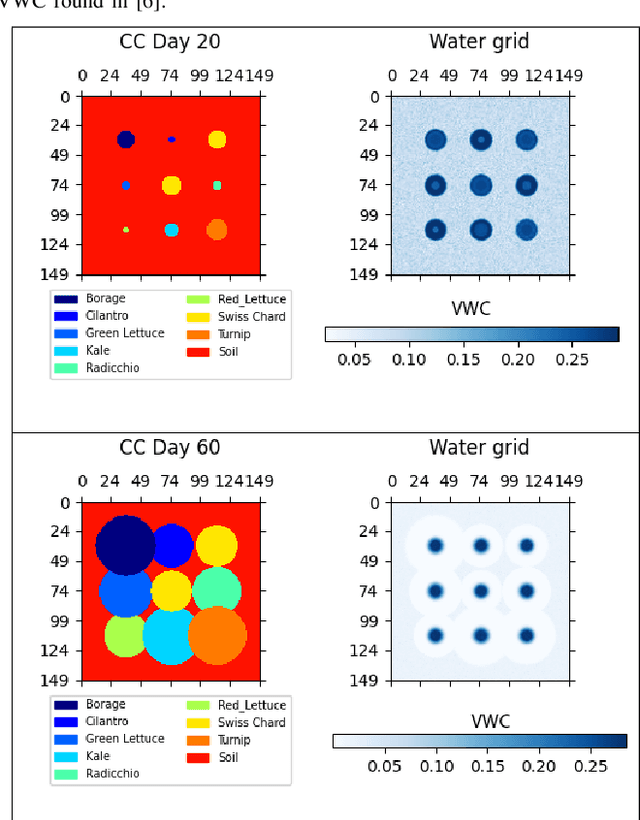
The AlphaGarden is an automated testbed for indoor polyculture farming which combines a first-order plant simulator, a gantry robot, a seed planting algorithm, plant phenotyping and tracking algorithms, irrigation sensors and algorithms, and custom pruning tools and algorithms. In this paper, we systematically compare the performance of the AlphaGarden to professional horticulturalists on the staff of the UC Berkeley Oxford Tract Greenhouse. The humans and the machine tend side-by-side polyculture gardens with the same seed arrangement. We compare performance in terms of canopy coverage, plant diversity, and water consumption. Results from two 60-day cycles suggest that the automated AlphaGarden performs comparably to professional horticulturalists in terms of coverage and diversity, and reduces water consumption by as much as 44%. Code, videos, and datasets are available at https://sites.google.com/berkeley.edu/systematiccomparison.
FogROS2-SGC: A ROS2 Cloud Robotics Platform for Secure Global Connectivity
Jun 29, 2023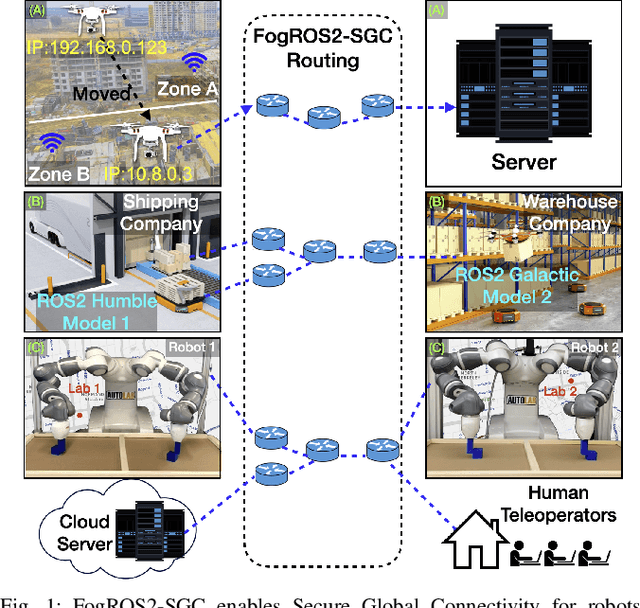

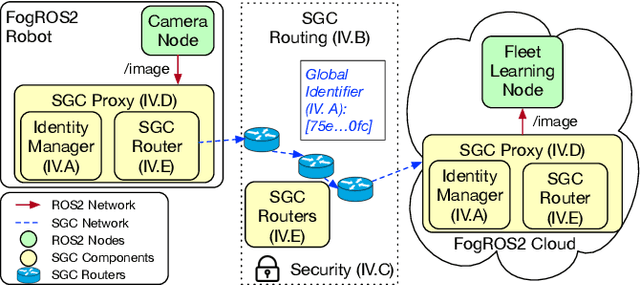
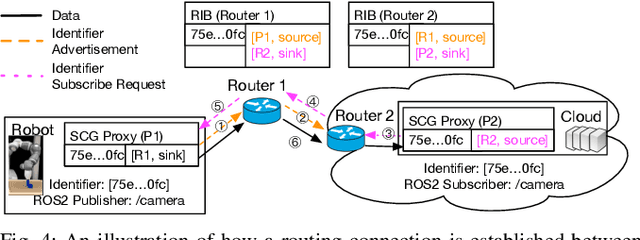
The Robot Operating System (ROS2) is the most widely used software platform for building robotics applications. FogROS2 extends ROS2 to allow robots to access cloud computing on demand. However, ROS2 and FogROS2 assume that all robots are locally connected and that each robot has full access and control of the other robots. With applications like distributed multi-robot systems, remote robot control, and mobile robots, robotics increasingly involves the global Internet and complex trust management. Existing approaches for connecting disjoint ROS2 networks lack key features such as security, compatibility, efficiency, and ease of use. We introduce FogROS2-SGC, an extension of FogROS2 that can effectively connect robot systems across different physical locations, networks, and Data Distribution Services (DDS). With globally unique and location-independent identifiers, FogROS2-SGC securely and efficiently routes data between robotics components around the globe. FogROS2-SGC is agnostic to the ROS2 distribution and configuration, is compatible with non-ROS2 software, and seamlessly extends existing ROS2 applications without any code modification. Experiments suggest FogROS2-SGC is 19x faster than rosbridge (a ROS2 package with comparable features, but lacking security). We also apply FogROS2-SGC to 4 robots and compute nodes that are 3600km apart. Videos and code are available on the project website https://sites.google.com/view/fogros2-sgc.
IIFL: Implicit Interactive Fleet Learning from Heterogeneous Human Supervisors
Jun 27, 2023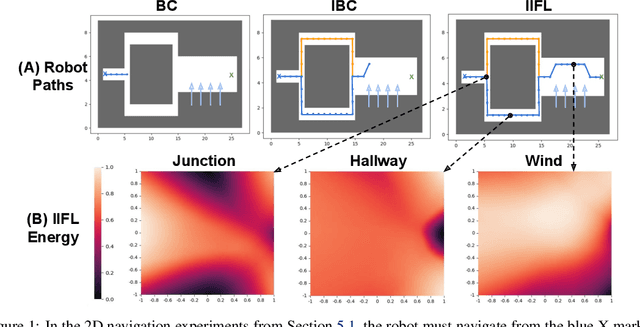
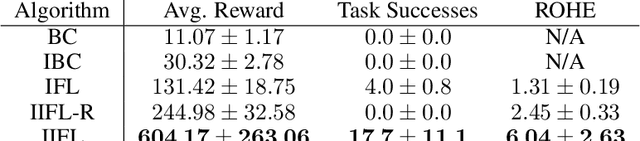
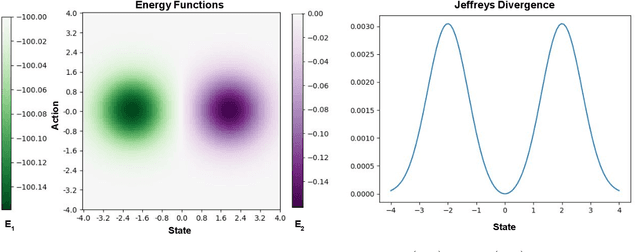
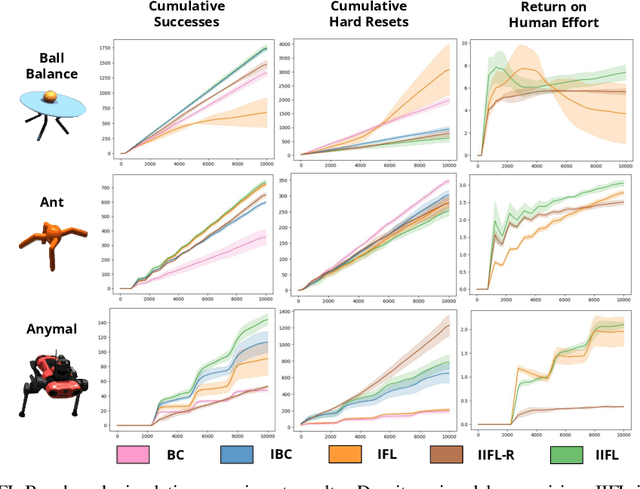
Imitation learning has been applied to a range of robotic tasks, but can struggle when (1) robots encounter edge cases that are not represented in the training data (distribution shift) or (2) the human demonstrations are heterogeneous: taking different paths around an obstacle, for instance (multimodality). Interactive fleet learning (IFL) mitigates distribution shift by allowing robots to access remote human teleoperators during task execution and learn from them over time, but is not equipped to handle multimodality. Recent work proposes Implicit Behavior Cloning (IBC), which is able to represent multimodal demonstrations using energy-based models (EBMs). In this work, we propose addressing both multimodality and distribution shift with Implicit Interactive Fleet Learning (IIFL), the first extension of implicit policies to interactive imitation learning (including the single-robot, single-human setting). IIFL quantifies uncertainty using a novel application of Jeffreys divergence to EBMs. While IIFL is more computationally expensive than explicit methods, results suggest that IIFL achieves 4.5x higher return on human effort in simulation experiments and an 80% higher success rate in a physical block pushing task over (Explicit) IFL, IBC, and other baselines when human supervision is heterogeneous.
Push-MOG: Efficient Pushing to Consolidate Polygonal Objects for Multi-Object Grasping
Jun 24, 2023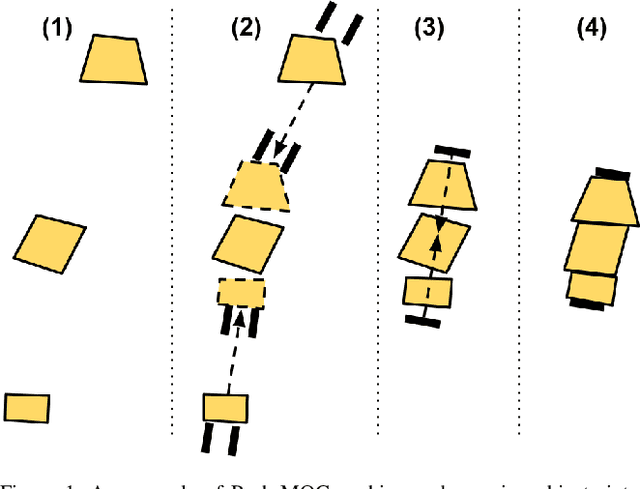

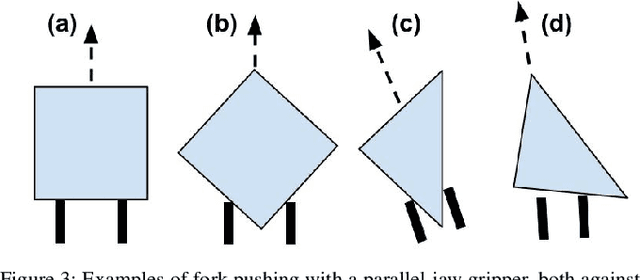

Recently, robots have seen rapidly increasing use in homes and warehouses to declutter by collecting objects from a planar surface and placing them into a container. While current techniques grasp objects individually, Multi-Object Grasping (MOG) can improve efficiency by increasing the average number of objects grasped per trip (OpT). However, grasping multiple objects requires the objects to be aligned and in close proximity. In this work, we propose Push-MOG, an algorithm that computes "fork pushing" actions using a parallel-jaw gripper to create graspable object clusters. In physical decluttering experiments, we find that Push-MOG enables multi-object grasps, increasing the average OpT by 34%. Code and videos will be available at https://sites.google.com/berkeley.edu/push-mog.