 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
A Simple Open-Loop Baseline for Reinforcement Learning Locomotion Tasks
Oct 09, 2023



In search of the simplest baseline capable of competing with Deep Reinforcement Learning on locomotion tasks, we propose a biologically inspired model-free open-loop strategy. Drawing upon prior knowledge and harnessing the elegance of simple oscillators to generate periodic joint motions, it achieves respectable performance in five different locomotion environments, with a number of tunable parameters that is a tiny fraction of the thousands typically required by RL algorithms. Unlike RL methods, which are prone to performance degradation when exposed to sensor noise or failure, our open-loop oscillators exhibit remarkable robustness due to their lack of reliance on sensors. Furthermore, we showcase a successful transfer from simulation to reality using an elastic quadruped, all without the need for randomization or reward engineering.
Two-Stage Learning of Highly Dynamic Motions with Rigid and Articulated Soft Quadrupeds
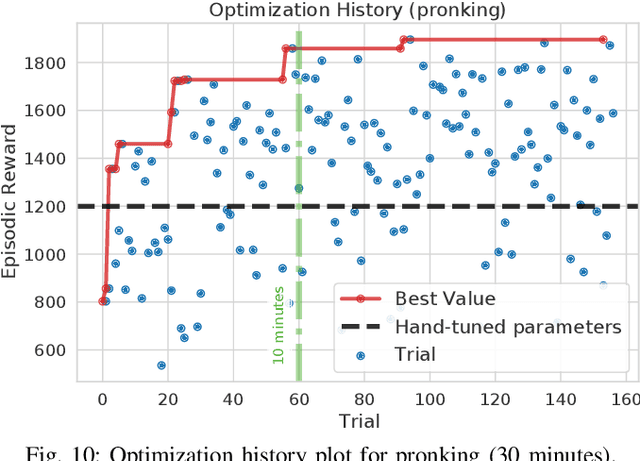
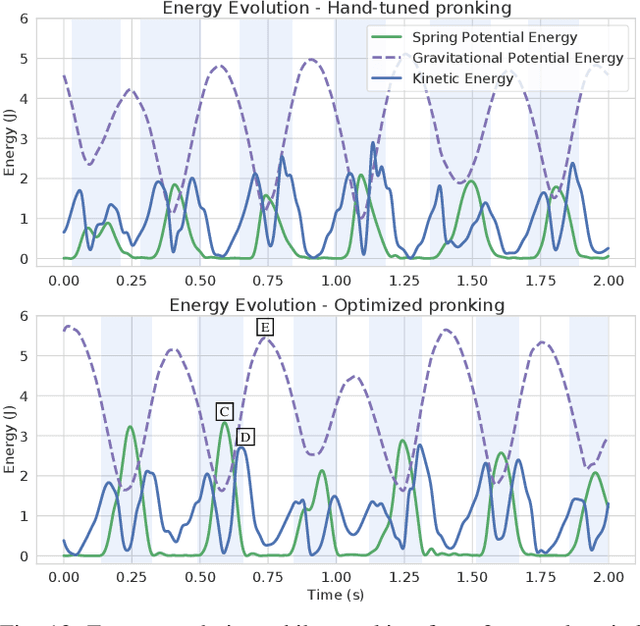
Sep 18, 2023Controlled execution of dynamic motions in quadrupedal robots, especially those with articulated soft bodies, presents a unique set of challenges that traditional methods struggle to address efficiently. In this study, we tackle these issues by relying on a simple yet effective two-stage learning framework to generate dynamic motions for quadrupedal robots. First, a gradient-free evolution strategy is employed to discover simply represented control policies, eliminating the need for a predefined reference motion. Then, we refine these policies using deep reinforcement learning. Our approach enables the acquisition of complex motions like pronking and back-flipping, effectively from scratch. Additionally, our method simplifies the traditionally labour-intensive task of reward shaping, boosting the efficiency of the learning process. Importantly, our framework proves particularly effective for articulated soft quadrupeds, whose inherent compliance and adaptability make them ideal for dynamic tasks but also introduce unique control challenges.
Learning to Exploit Elastic Actuators for Quadruped Locomotion
Sep 15, 2022

Spring-based actuators in legged locomotion provide energy-efficiency and improved performance, but increase the difficulty of controller design. Whereas previous works have focused on extensive modeling and simulation to find optimal controllers for such systems, we propose to learn model-free controllers directly on the real robot. In our approach, gaits are first synthesized by central pattern generators (CPGs), whose parameters are optimized to quickly obtain an open-loop controller that achieves efficient locomotion. Then, to make that controller more robust and further improve the performance, we use reinforcement learning to close the loop, to learn corrective actions on top of the CPGs. We evaluate the proposed approach in DLR's elastic quadruped bert. Our results in learning trotting and pronking gaits show that exploitation of the spring actuator dynamics emerges naturally from optimizing for dynamic motions, yielding high-performing locomotion despite being model-free. The whole process takes no more than 1.5 hours on the real robot and results in natural-looking gaits.
Making Reinforcement Learning Work on Swimmer
Aug 25, 2022
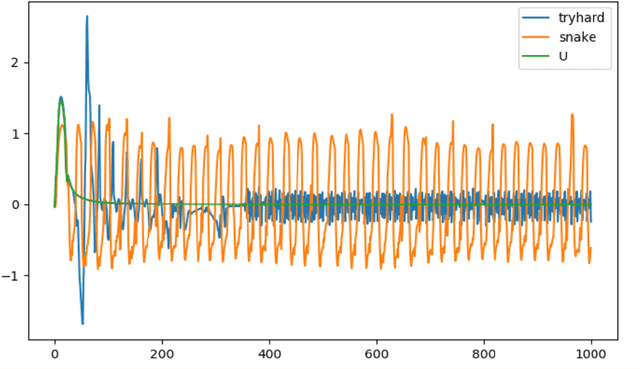
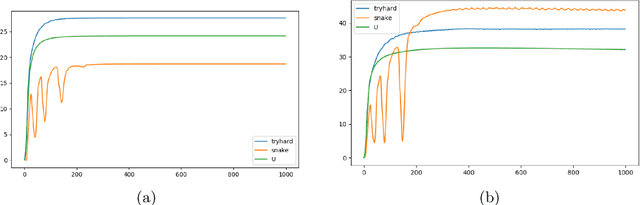
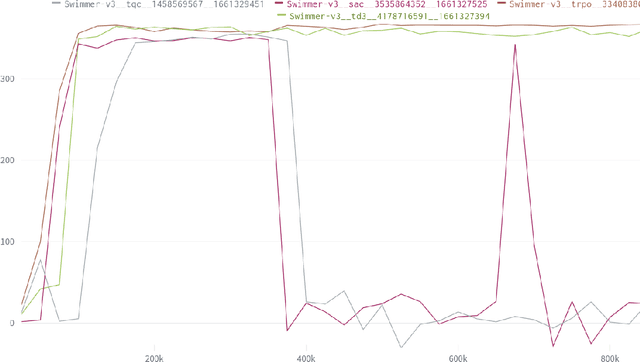
The SWIMMER environment is a standard benchmark in reinforcement learning (RL). In particular, it is often used in papers comparing or combining RL methods with direct policy search methods such as genetic algorithms or evolution strategies. A lot of these papers report poor performance on SWIMMER from RL methods and much better performance from direct policy search methods. In this technical report we show that the low performance of RL methods on SWIMMER simply comes from the inadequate tuning of an important hyper-parameter, the discount factor. Furthermore we show that, by setting this hyper-parameter to a correct value, the issue can be easily fixed. Finally, for a set of often used RL algorithms, we provide a set of successful hyper-parameters obtained with the Stable Baselines3 library and its RL Zoo.
A2C is a special case of PPO
May 18, 2022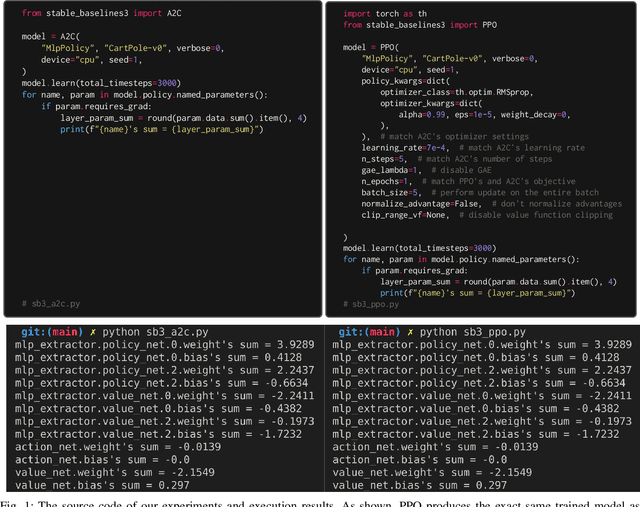
Advantage Actor-critic (A2C) and Proximal Policy Optimization (PPO) are popular deep reinforcement learning algorithms used for game AI in recent years. A common understanding is that A2C and PPO are separate algorithms because PPO's clipped objective appears significantly different than A2C's objective. In this paper, however, we show A2C is a special case of PPO. We present theoretical justifications and pseudocode analysis to demonstrate why. To validate our claim, we conduct an empirical experiment using \texttt{Stable-baselines3}, showing A2C and PPO produce the \textit{exact} same models when other settings are controlled.
Generalized State-Dependent Exploration for Deep Reinforcement Learning in Robotics
May 12, 2020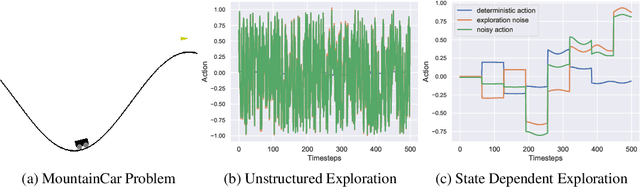


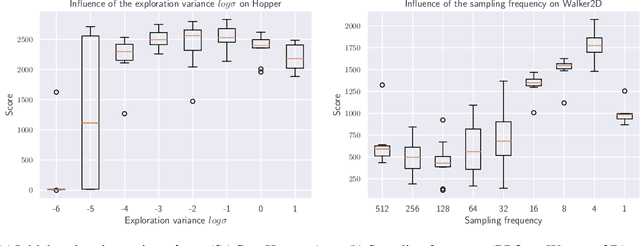
Reinforcement learning (RL) enables robots to learn skills from interactions with the real world. In practice, the unstructured step-based exploration used in Deep RL -- often very successful in simulation -- leads to jerky motion patterns on real robots. Consequences of the resulting shaky behavior are poor exploration, or even damage to the robot. We address these issues by adapting state-dependent exploration (SDE) to current Deep RL algorithms. To enable this adaptation, we propose three extensions to the original SDE, which leads to a new exploration method generalized state-dependent exploration (gSDE). We evaluate gSDE both in simulation, on PyBullet continuous control tasks, and directly on a tendon-driven elastic robot. gSDE yields competitive results in simulation but outperforms the unstructured exploration on the real robot. The code is available at https://github.com/DLR-RM/stable-baselines3/tree/sde.
Decoupling feature extraction from policy learning: assessing benefits of state representation learning in goal based robotics
Feb 03, 2019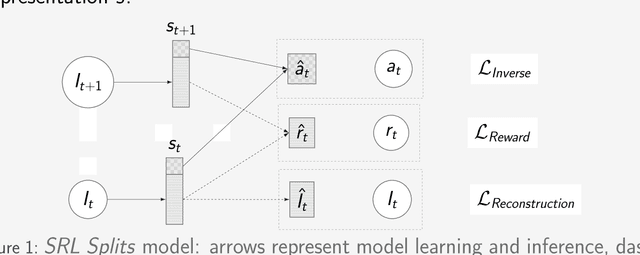

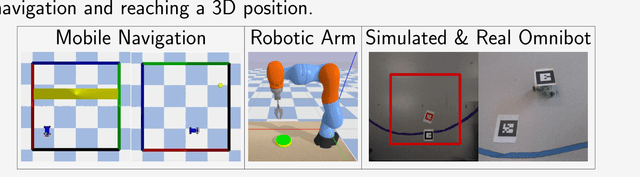
Scaling end-to-end reinforcement learning to control real robots from vision presents a series of challenges, in particular in terms of sample efficiency. Against end-to-end learning, state representation learning can help learn a compact, efficient and relevant representation of states that speeds up policy learning, reducing the number of samples needed, and that is easier to interpret. We evaluate several state representation learning methods on goal based robotics tasks and propose a new unsupervised model that stacks representations and combines strengths of several of these approaches. This method encodes all the relevant features, performs on par or better than end-to-end learning, and is robust to hyper-parameters change.
S-RL Toolbox: Environments, Datasets and Evaluation Metrics for State Representation Learning
Oct 10, 2018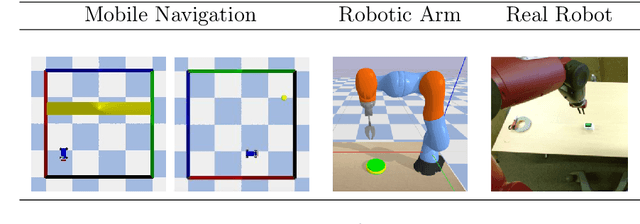
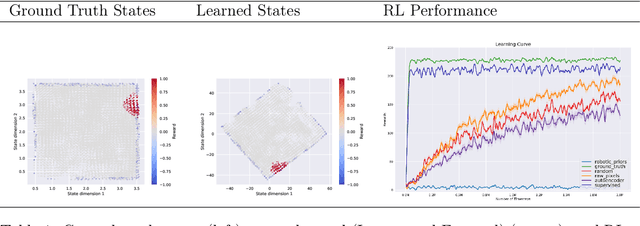
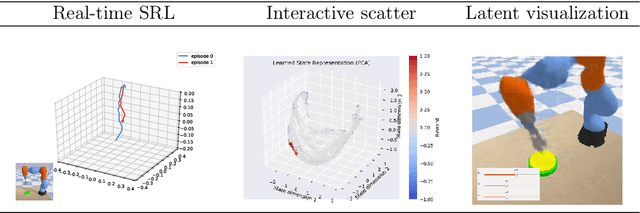
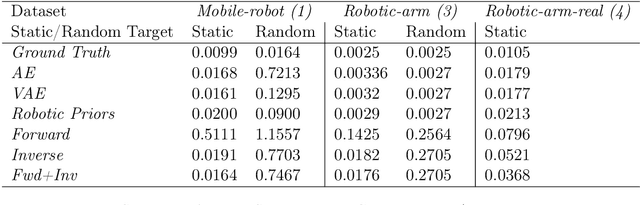
State representation learning aims at learning compact representations from raw observations in robotics and control applications. Approaches used for this objective are auto-encoders, learning forward models, inverse dynamics or learning using generic priors on the state characteristics. However, the diversity in applications and methods makes the field lack standard evaluation datasets, metrics and tasks. This paper provides a set of environments, data generators, robotic control tasks, metrics and tools to facilitate iterative state representation learning and evaluation in reinforcement learning settings.