 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC3-Eval: Evaluating Robot Foundation Models via Self-Consistent Video Generation
Jun 17, 2026Evaluating generalist robot manipulation policies in the real world is expensive, slow, and difficult to scale. Action-conditioned video world models offer a scalable alternative by simulating policy rollouts. Autoregressive rollouts accumulate compounding errors, observations across multiple camera views must remain mutually consistent, and the evaluator must generalize to policies whose behaviors lie outside the training distribution. We address these challenges with SC3-Eval, a self-consistent video generation recipe that adapts a pre-trained video foundation model into an accurate policy evaluator by enforcing three complementary forms of consistency. First, forward-inverse dynamics consistency jointly trains the model to predict frames from actions and to recover actions from frames, anchoring generated rollouts to a physically plausible action manifold and counteracting the drift a forward-only model cannot penalize. Second, cross-view consistency trains the model to inpaint each camera view from the other, keeping the multi-camera observation coherent over long rollouts without any explicit memory mechanism. Third, test-time consistency reuses the inverse dynamics mode at inference as a per-action-chunk uncertainty signal that terminates rollouts whose generated frames drift away from the requested actions. We also demonstrate SC3-Eval rollouts reproduce the failure modes that policies exhibit in real-world rollouts, supporting fine-grained diagnostic comparison rather than aggregate ranking alone. Across seven real-world vision-language-action policies, SC3-Eval attains a closed-loop Pearson correlation of $0.929$ and MMRV of $0.119$, outperforming three strong prior video-model-based baselines, and generalizes to new tasks.
Open-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
$π$, But Make It Fly: Physics-Guided Transfer of VLA Models to Aerial Manipulation
Mar 26, 2026Vision-Language-Action (VLA) models such as $π_0$ have demonstrated remarkable generalization across diverse fixed-base manipulators. However, transferring these foundation models to aerial platforms remains an open challenge due to the fundamental mismatch between the quasi-static dynamics of fixed-base arms and the underactuated, highly dynamic nature of flight. In this work, we introduce AirVLA, a system that investigates the transferability of manipulation-pretrained VLAs to aerial pick-and-place tasks. We find that while visual representations transfer effectively, the specific control dynamics required for flight do not. To bridge this "dynamics gap" without retraining the foundation model, we introduce a Payload-Aware Guidance mechanism that injects payload constraints directly into the policy's flow-matching sampling process. To overcome data scarcity, we further utilize a Gaussian Splatting pipeline to synthesize navigation training data. We evaluate our method through a cumulative 460 real-world experiments which demonstrate that this synthetic data is a key enabler of performance, unlocking 100% success in navigation tasks where directly fine-tuning on teleoperation data alone attains 81% success. Our inference-time intervention, Payload-Aware Guidance, increases real-world pick-and-place task success from 23% to 50%. Finally, we evaluate the model on a long-horizon compositional task, achieving a 62% overall success rate. These results suggest that pre-trained manipulation VLAs, with appropriate data augmentation and physics-informed guidance, can transfer to aerial manipulation and navigation, as well as the composition of these tasks.
MEM: Multi-Scale Embodied Memory for Vision Language Action Models
Mar 04, 2026Conventionally, memory in end-to-end robotic learning involves inputting a sequence of past observations into the learned policy. However, in complex multi-stage real-world tasks, the robot's memory must represent past events at multiple levels of granularity: from long-term memory that captures abstracted semantic concepts (e.g., a robot cooking dinner should remember which stages of the recipe are already done) to short-term memory that captures recent events and compensates for occlusions (e.g., a robot remembering the object it wants to pick up once its arm occludes it). In this work, our main insight is that an effective memory architecture for long-horizon robotic control should combine multiple modalities to capture these different levels of abstraction. We introduce Multi-Scale Embodied Memory (MEM), an approach for mixed-modal long-horizon memory in robot policies. MEM combines video-based short-horizon memory, compressed via a video encoder, with text-based long-horizon memory. Together, they enable robot policies to perform tasks that span up to fifteen minutes, like cleaning up a kitchen, or preparing a grilled cheese sandwich. Additionally, we find that memory enables MEM policies to intelligently adapt manipulation strategies in-context.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better
May 29, 2025Vision-language-action (VLA) models provide a powerful approach to training control policies for physical systems, such as robots, by combining end-to-end learning with transfer of semantic knowledge from web-scale vision-language model (VLM) training. However, the constraints of real-time control are often at odds with the design of VLMs: the most powerful VLMs have tens or hundreds of billions of parameters, presenting an obstacle to real-time inference, and operate on discrete tokens rather than the continuous-valued outputs that are required for controlling robots. To address this challenge, recent VLA models have used specialized modules for efficient continuous control, such as action experts or continuous output heads, which typically require adding new untrained parameters to the pretrained VLM backbone. While these modules improve real-time and control capabilities, it remains an open question whether they preserve or degrade the semantic knowledge contained in the pretrained VLM, and what effect they have on the VLA training dynamics. In this paper, we study this question in the context of VLAs that include a continuous diffusion or flow matching action expert, showing that naively including such experts significantly harms both training speed and knowledge transfer. We provide an extensive analysis of various design choices, their impact on performance and knowledge transfer, and propose a technique for insulating the VLM backbone during VLA training that mitigates this issue. Videos are available at https://pi.website/research/knowledge_insulation.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
Feb 26, 2025Generalist robots that can perform a range of different tasks in open-world settings must be able to not only reason about the steps needed to accomplish their goals, but also process complex instructions, prompts, and even feedback during task execution. Intricate instructions (e.g., "Could you make me a vegetarian sandwich?" or "I don't like that one") require not just the ability to physically perform the individual steps, but the ability to situate complex commands and feedback in the physical world. In this work, we describe a system that uses vision-language models in a hierarchical structure, first reasoning over complex prompts and user feedback to deduce the most appropriate next step to fulfill the task, and then performing that step with low-level actions. In contrast to direct instruction following methods that can fulfill simple commands ("pick up the cup"), our system can reason through complex prompts and incorporate situated feedback during task execution ("that's not trash"). We evaluate our system across three robotic platforms, including single-arm, dual-arm, and dual-arm mobile robots, demonstrating its ability to handle tasks such as cleaning messy tables, making sandwiches, and grocery shopping.
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Jan 16, 2025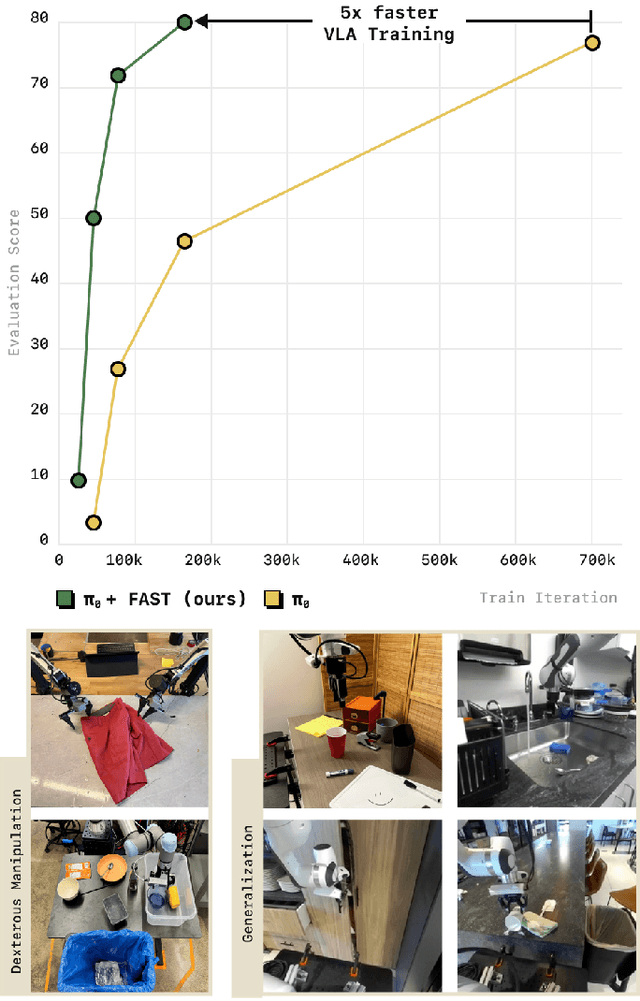

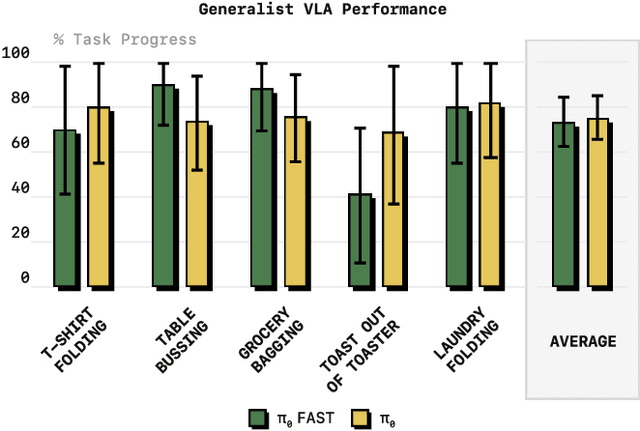
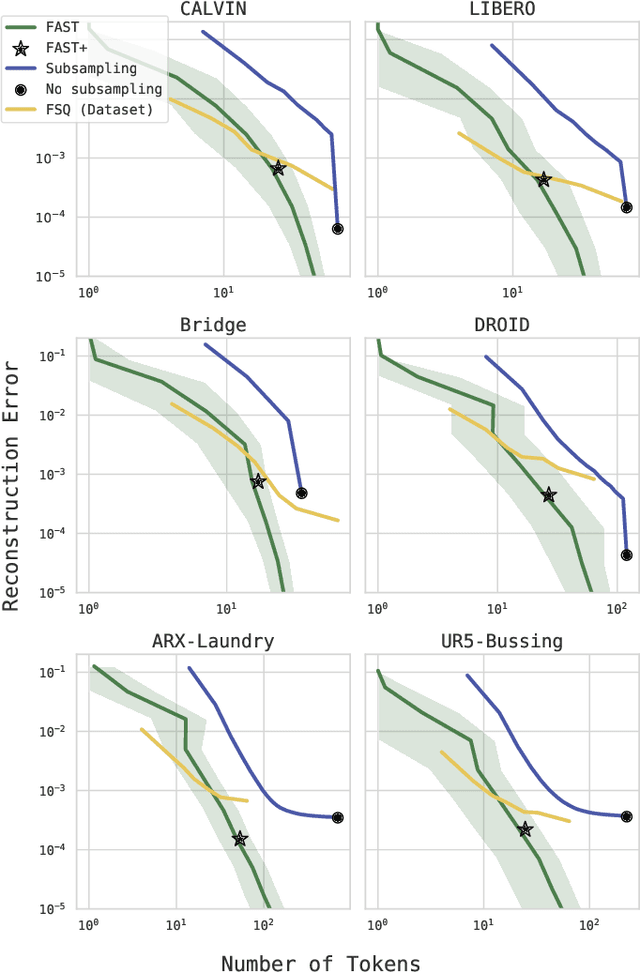
Autoregressive sequence models, such as Transformer-based vision-language action (VLA) policies, can be tremendously effective for capturing complex and generalizable robotic behaviors. However, such models require us to choose a tokenization of our continuous action signals, which determines how the discrete symbols predicted by the model map to continuous robot actions. We find that current approaches for robot action tokenization, based on simple per-dimension, per-timestep binning schemes, typically perform poorly when learning dexterous skills from high-frequency robot data. To address this challenge, we propose a new compression-based tokenization scheme for robot actions, based on the discrete cosine transform. Our tokenization approach, Frequency-space Action Sequence Tokenization (FAST), enables us to train autoregressive VLAs for highly dexterous and high-frequency tasks where standard discretization methods fail completely. Based on FAST, we release FAST+, a universal robot action tokenizer, trained on 1M real robot action trajectories. It can be used as a black-box tokenizer for a wide range of robot action sequences, with diverse action spaces and control frequencies. Finally, we show that, when combined with the pi0 VLA, our method can scale to training on 10k hours of robot data and match the performance of diffusion VLAs, while reducing training time by up to 5x.
What's the Move? Hybrid Imitation Learning via Salient Points
Dec 06, 2024



While imitation learning (IL) offers a promising framework for teaching robots various behaviors, learning complex tasks remains challenging. Existing IL policies struggle to generalize effectively across visual and spatial variations even for simple tasks. In this work, we introduce SPHINX: Salient Point-based Hybrid ImitatioN and eXecution, a flexible IL policy that leverages multimodal observations (point clouds and wrist images), along with a hybrid action space of low-frequency, sparse waypoints and high-frequency, dense end effector movements. Given 3D point cloud observations, SPHINX learns to infer task-relevant points within a point cloud, or salient points, which support spatial generalization by focusing on semantically meaningful features. These salient points serve as anchor points to predict waypoints for long-range movement, such as reaching target poses in free-space. Once near a salient point, SPHINX learns to switch to predicting dense end-effector movements given close-up wrist images for precise phases of a task. By exploiting the strengths of different input modalities and action representations for different manipulation phases, SPHINX tackles complex tasks in a sample-efficient, generalizable manner. Our method achieves 86.7% success across 4 real-world and 2 simulated tasks, outperforming the next best state-of-the-art IL baseline by 41.1% on average across 440 real world trials. SPHINX additionally generalizes to novel viewpoints, visual distractors, spatial arrangements, and execution speeds with a 1.7x speedup over the most competitive baseline. Our website (http://sphinx-manip.github.io) provides open-sourced code for data collection, training, and evaluation, along with supplementary videos.