 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
Just Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning
Jun 06, 2025Large reasoning models (LRMs) achieve higher performance on challenging reasoning tasks by generating more tokens at inference time, but this verbosity often wastes computation on easy problems. Existing solutions, including supervised finetuning on shorter traces, user-controlled budgets, or RL with uniform penalties, either require data curation, manual configuration, or treat all problems alike regardless of difficulty. We introduce Adaptive Length Penalty (ALP), a reinforcement learning objective tailoring generation length to per-prompt solve rate. During training, ALP monitors each prompt's online solve rate through multiple rollouts and adds a differentiable penalty whose magnitude scales inversely with that rate, so confident (easy) prompts incur a high cost for extra tokens while hard prompts remain unhindered. Posttraining DeepScaleR-1.5B with ALP cuts average token usage by 50\% without significantly dropping performance. Relative to fixed-budget and uniform penalty baselines, ALP redistributes its reduced budget more intelligently by cutting compute on easy prompts and reallocating saved tokens to difficult ones, delivering higher accuracy on the hardest problems with higher cost.
Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models
Feb 24, 2025Increasing interest in reasoning models has led math to become a prominent testing ground for algorithmic and methodological improvements. However, existing open math datasets either contain a small collection of high-quality, human-written problems or a large corpus of machine-generated problems of uncertain quality, forcing researchers to choose between quality and quantity. In this work, we present Big-Math, a dataset of over 250,000 high-quality math questions with verifiable answers, purposefully made for reinforcement learning (RL). To create Big-Math, we rigorously filter, clean, and curate openly available datasets, extracting questions that satisfy our three desiderata: (1) problems with uniquely verifiable solutions, (2) problems that are open-ended, (3) and problems with a closed-form solution. To ensure the quality of Big-Math, we manually verify each step in our filtering process. Based on the findings from our filtering process, we introduce 47,000 new questions with verified answers, Big-Math-Reformulated: closed-ended questions (i.e. multiple choice questions) that have been reformulated as open-ended questions through a systematic reformulation algorithm. Compared to the most commonly used existing open-source datasets for math reasoning, GSM8k and MATH, Big-Math is an order of magnitude larger, while our rigorous filtering ensures that we maintain the questions most suitable for RL. We also provide a rigorous analysis of the dataset, finding that Big-Math contains a high degree of diversity across problem domains, and incorporates a wide range of problem difficulties, enabling a wide range of downstream uses for models of varying capabilities and training requirements. By bridging the gap between data quality and quantity, Big-Math establish a robust foundation for advancing reasoning in LLMs.
MJ-VIDEO: Fine-Grained Benchmarking and Rewarding Video Preferences in Video Generation
Feb 03, 2025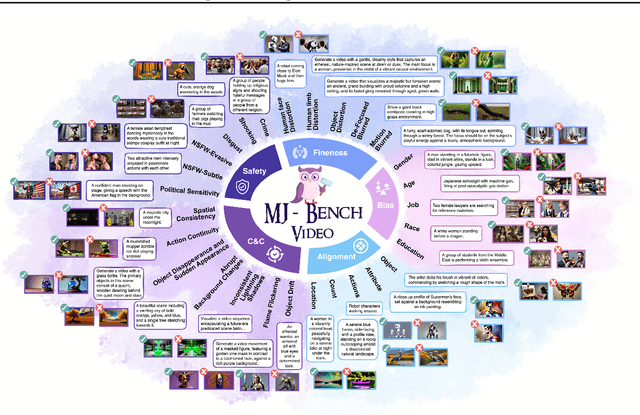
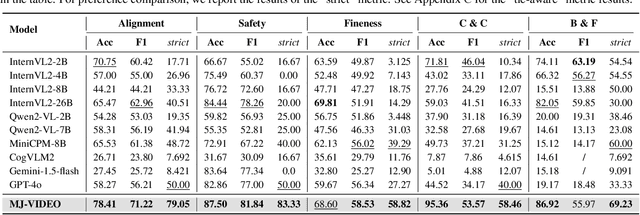
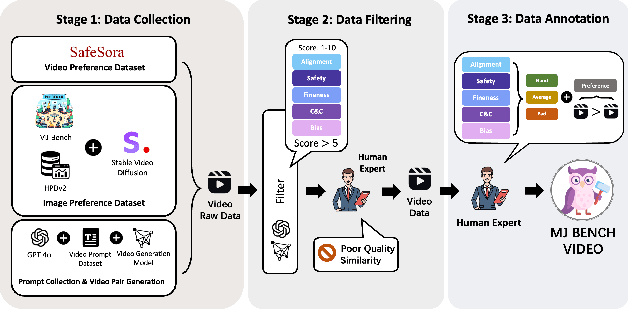
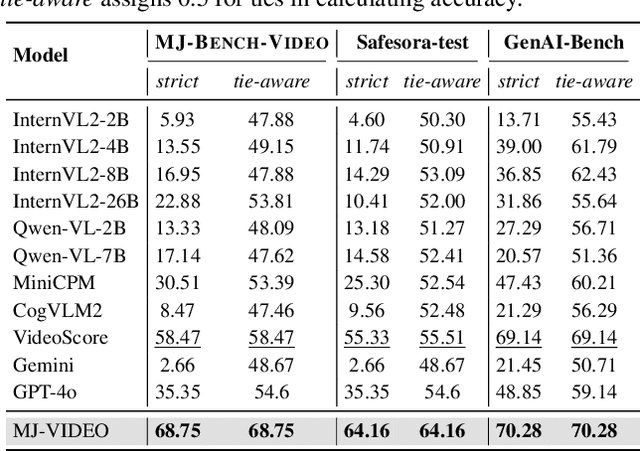
Recent advancements in video generation have significantly improved the ability to synthesize videos from text instructions. However, existing models still struggle with key challenges such as instruction misalignment, content hallucination, safety concerns, and bias. Addressing these limitations, we introduce MJ-BENCH-VIDEO, a large-scale video preference benchmark designed to evaluate video generation across five critical aspects: Alignment, Safety, Fineness, Coherence & Consistency, and Bias & Fairness. This benchmark incorporates 28 fine-grained criteria to provide a comprehensive evaluation of video preference. Building upon this dataset, we propose MJ-VIDEO, a Mixture-of-Experts (MoE)-based video reward model designed to deliver fine-grained reward. MJ-VIDEO can dynamically select relevant experts to accurately judge the preference based on the input text-video pair. This architecture enables more precise and adaptable preference judgments. Through extensive benchmarking on MJ-BENCH-VIDEO, we analyze the limitations of existing video reward models and demonstrate the superior performance of MJ-VIDEO in video preference assessment, achieving 17.58% and 15.87% improvements in overall and fine-grained preference judgments, respectively. Additionally, introducing MJ-VIDEO for preference tuning in video generation enhances the alignment performance.
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
Jan 08, 2025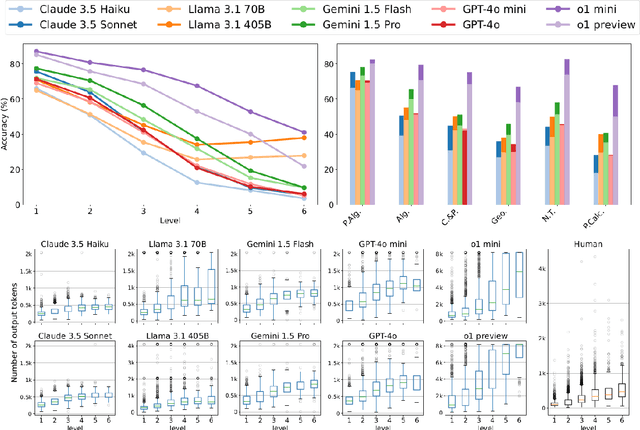
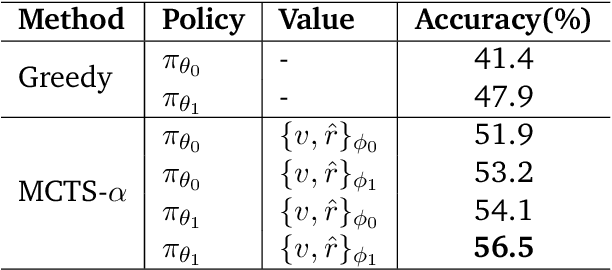
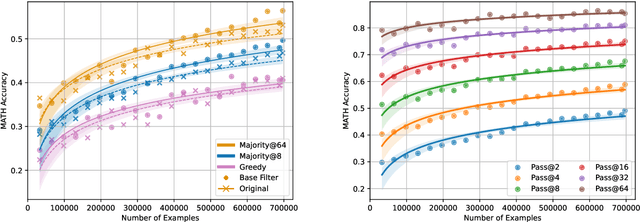
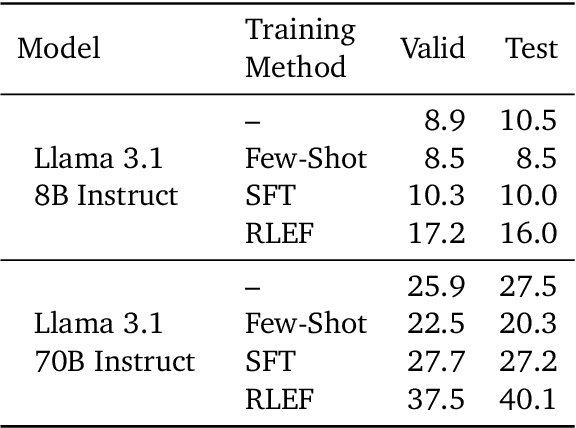
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. Finally, we outline a concrete pipeline for training a model to produce Meta-CoTs, incorporating instruction tuning with linearized search traces and reinforcement learning post-training. Finally, we discuss open research questions, including scaling laws, verifier roles, and the potential for discovering novel reasoning algorithms. This work provides a theoretical and practical roadmap to enable Meta-CoT in LLMs, paving the way for more powerful and human-like reasoning in artificial intelligence.
Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World
Oct 22, 2024



The increasing presence of AI-generated content on the internet raises a critical question: What happens when generative machine learning models are pretrained on web-scale datasets containing data created by earlier models? Some authors prophesy $\textit{model collapse}$ under a "$\textit{replace}$" scenario: a sequence of models, the first trained with real data and each later one trained only on synthetic data from its preceding model. In this scenario, models successively degrade. Others see collapse as easily avoidable; in an "$\textit{accumulate}$' scenario, a sequence of models is trained, but each training uses all real and synthetic data generated so far. In this work, we deepen and extend the study of these contrasting scenarios. First, collapse versus avoidance of collapse is studied by comparing the replace and accumulate scenarios on each of three prominent generative modeling settings; we find the same contrast emerges in all three settings. Second, we study a compromise scenario; the available data remains the same as in the accumulate scenario -- but unlike $\textit{accumulate}$ and like $\textit{replace}$, each model is trained using a fixed compute budget; we demonstrate that model test loss on real data is larger than in the $\textit{accumulate}$ scenario, but apparently plateaus, unlike the divergence seen with $\textit{replace}$. Third, we study the relative importance of cardinality and proportion of real data for avoiding model collapse. Surprisingly, we find a non-trivial interaction between real and synthetic data, where the value of synthetic data for reducing test loss depends on the absolute quantity of real data. Our insights are particularly important when forecasting whether future frontier generative models will collapse or thrive, and our results open avenues for empirically and mathematically studying the context-dependent value of synthetic data.
D5RL: Diverse Datasets for Data-Driven Deep Reinforcement Learning
Aug 15, 2024



Offline reinforcement learning algorithms hold the promise of enabling data-driven RL methods that do not require costly or dangerous real-world exploration and benefit from large pre-collected datasets. This in turn can facilitate real-world applications, as well as a more standardized approach to RL research. Furthermore, offline RL methods can provide effective initializations for online finetuning to overcome challenges with exploration. However, evaluating progress on offline RL algorithms requires effective and challenging benchmarks that capture properties of real-world tasks, provide a range of task difficulties, and cover a range of challenges both in terms of the parameters of the domain (e.g., length of the horizon, sparsity of rewards) and the parameters of the data (e.g., narrow demonstration data or broad exploratory data). While considerable progress in offline RL in recent years has been enabled by simpler benchmark tasks, the most widely used datasets are increasingly saturating in performance and may fail to reflect properties of realistic tasks. We propose a new benchmark for offline RL that focuses on realistic simulations of robotic manipulation and locomotion environments, based on models of real-world robotic systems, and comprising a variety of data sources, including scripted data, play-style data collected by human teleoperators, and other data sources. Our proposed benchmark covers state-based and image-based domains, and supports both offline RL and online fine-tuning evaluation, with some of the tasks specifically designed to require both pre-training and fine-tuning. We hope that our proposed benchmark will facilitate further progress on both offline RL and fine-tuning algorithms. Website with code, examples, tasks, and data is available at \url{https://sites.google.com/view/d5rl/}
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
Aug 13, 2024Large Language Models (LLMs) have shown remarkable capabilities in natural language tasks requiring complex reasoning, yet their application in agentic, multi-step reasoning within interactive environments remains a difficult challenge. Traditional supervised pre-training on static datasets falls short in enabling autonomous agent capabilities needed to perform complex decision-making in dynamic settings like web navigation. Previous attempts to bridge this ga-through supervised fine-tuning on curated expert demonstrations-often suffer from compounding errors and limited exploration data, resulting in sub-optimal policy outcomes. To overcome these challenges, we propose a framework that combines guided Monte Carlo Tree Search (MCTS) search with a self-critique mechanism and iterative fine-tuning on agent interactions using an off-policy variant of the Direct Preference Optimization (DPO) algorithm. Our method allows LLM agents to learn effectively from both successful and unsuccessful trajectories, thereby improving their generalization in complex, multi-step reasoning tasks. We validate our approach in the WebShop environment-a simulated e-commerce platform where it consistently outperforms behavior cloning and reinforced fine-tuning baseline, and beats average human performance when equipped with the capability to do online search. In real-world booking scenarios, our methodology boosts Llama-3 70B model's zero-shot performance from 18.6% to 81.7% success rate (a 340% relative increase) after a single day of data collection and further to 95.4% with online search. We believe this represents a substantial leap forward in the capabilities of autonomous agents, paving the way for more sophisticated and reliable decision-making in real-world settings.
PERSONA: A Reproducible Testbed for Pluralistic Alignment
Jul 24, 2024



The rapid advancement of language models (LMs) necessitates robust alignment with diverse user values. However, current preference optimization approaches often fail to capture the plurality of user opinions, instead reinforcing majority viewpoints and marginalizing minority perspectives. We introduce PERSONA, a reproducible test bed designed to evaluate and improve pluralistic alignment of LMs. We procedurally generate diverse user profiles from US census data, resulting in 1,586 synthetic personas with varied demographic and idiosyncratic attributes. We then generate a large-scale evaluation dataset containing 3,868 prompts and 317,200 feedback pairs obtained from our synthetic personas. Leveraging this dataset, we systematically evaluate LM capabilities in role-playing diverse users, verified through human judges, and the establishment of both a benchmark, PERSONA Bench, for pluralistic alignment approaches as well as an extensive dataset to create new and future benchmarks. The full dataset and benchmarks are available here: https://www.synthlabs.ai/research/persona.
MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
Jul 05, 2024



While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes. To address this issue, we introduce MJ-Bench, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias. Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset. Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities. Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench. All data, code, models are available at https://huggingface.co/MJ-Bench.