 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Physical Risk Control in the Era of Foundation Model-enabled Robotics
May 19, 2025Recent Foundation Model-enabled robotics (FMRs) display greatly improved general-purpose skills, enabling more adaptable automation than conventional robotics. Their ability to handle diverse tasks thus creates new opportunities to replace human labor. However, unlike general foundation models, FMRs interact with the physical world, where their actions directly affect the safety of humans and surrounding objects, requiring careful deployment and control. Based on this proposition, our survey comprehensively summarizes robot control approaches to mitigate physical risks by covering all the lifespan of FMRs ranging from pre-deployment to post-accident stage. Specifically, we broadly divide the timeline into the following three phases: (1) pre-deployment phase, (2) pre-incident phase, and (3) post-incident phase. Throughout this survey, we find that there is much room to study (i) pre-incident risk mitigation strategies, (ii) research that assumes physical interaction with humans, and (iii) essential issues of foundation models themselves. We hope that this survey will be a milestone in providing a high-resolution analysis of the physical risks of FMRs and their control, contributing to the realization of a good human-robot relationship.
Real-World Robot Applications of Foundation Models: A Review
Feb 08, 2024



Recent developments in foundation models, like Large Language Models (LLMs) and Vision-Language Models (VLMs), trained on extensive data, facilitate flexible application across different tasks and modalities. Their impact spans various fields, including healthcare, education, and robotics. This paper provides an overview of the practical application of foundation models in real-world robotics, with a primary emphasis on the replacement of specific components within existing robot systems. The summary encompasses the perspective of input-output relationships in foundation models, as well as their role in perception, motion planning, and control within the field of robotics. This paper concludes with a discussion of future challenges and implications for practical robot applications.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
TRAIL Team Description Paper for RoboCup@Home 2023
Oct 05, 2023



Our team, TRAIL, consists of AI/ML laboratory members from The University of Tokyo. We leverage our extensive research experience in state-of-the-art machine learning to build general-purpose in-home service robots. We previously participated in two competitions using Human Support Robot (HSR): RoboCup@Home Japan Open 2020 (DSPL) and World Robot Summit 2020, equivalent to RoboCup World Tournament. Throughout the competitions, we showed that a data-driven approach is effective for performing in-home tasks. Aiming for further development of building a versatile and fast-adaptable system, in RoboCup @Home 2023, we unify three technologies that have recently been evaluated as components in the fields of deep learning and robot learning into a real household robot system. In addition, to stimulate research all over the RoboCup@Home community, we build a platform that manages data collected from each site belonging to the community around the world, taking advantage of the characteristics of the community.
Self-Recovery Prompting: Promptable General Purpose Service Robot System with Foundation Models and Self-Recovery
Sep 27, 2023



A general-purpose service robot (GPSR), which can execute diverse tasks in various environments, requires a system with high generalizability and adaptability to tasks and environments. In this paper, we first developed a top-level GPSR system for worldwide competition (RoboCup@Home 2023) based on multiple foundation models. This system is both generalizable to variations and adaptive by prompting each model. Then, by analyzing the performance of the developed system, we found three types of failure in more realistic GPSR application settings: insufficient information, incorrect plan generation, and plan execution failure. We then propose the self-recovery prompting pipeline, which explores the necessary information and modifies its prompts to recover from failure. We experimentally confirm that the system with the self-recovery mechanism can accomplish tasks by resolving various failure cases. Supplementary videos are available at https://sites.google.com/view/srgpsr .
GenDOM: Generalizable One-shot Deformable Object Manipulation with Parameter-Aware Policy
Sep 19, 2023Due to the inherent uncertainty in their deformability during motion, previous methods in deformable object manipulation, such as rope and cloth, often required hundreds of real-world demonstrations to train a manipulation policy for each object, which hinders their applications in our ever-changing world. To address this issue, we introduce GenDOM, a framework that allows the manipulation policy to handle different deformable objects with only a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable object parameters and training it with a diverse range of simulated deformable objects so that the policy can adjust actions based on different object parameters. At the time of inference, given a new object, GenDOM can estimate the deformable object parameters with only a single real-world demonstration by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations in a differentiable physics simulator. Empirical validations on both simulated and real-world object manipulation setups clearly show that our method can manipulate different objects with a single demonstration and significantly outperforms the baseline in both environments (a 62% improvement for in-domain ropes and a 15% improvement for out-of-distribution ropes in simulation, as well as a 26% improvement for ropes and a 50% improvement for cloths in the real world), demonstrating the effectiveness of our approach in one-shot deformable object manipulation.
GenORM: Generalizable One-shot Rope Manipulation with Parameter-Aware Policy
Jun 20, 2023



Due to the inherent uncertainty in their deformability during motion, previous methods in rope manipulation often require hundreds of real-world demonstrations to train a manipulation policy for each rope, even for simple tasks such as rope goal reaching, which hinder their applications in our ever-changing world. To address this issue, we introduce GenORM, a framework that allows the manipulation policy to handle different deformable ropes with a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable rope parameters and training it with a diverse range of simulated deformable ropes so that the policy can adjust actions based on different rope parameters. At the time of inference, given a new rope, GenORM estimates the deformable rope parameters by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations. With the help of a differentiable physics simulator, we require only a single real-world demonstration. Empirical validations on both simulated and real-world rope manipulation setups clearly show that our method can manipulate different ropes with a single demonstration and significantly outperforms the baseline in both environments (62% improvement in in-domain ropes, and 15% improvement in out-of-distribution ropes in simulation, 26% improvement in real-world), demonstrating the effectiveness of our approach in one-shot rope manipulation.
Collective Intelligence for Object Manipulation with Mobile Robots
Nov 28, 2022



While natural systems often present collective intelligence that allows them to self-organize and adapt to changes, the equivalent is missing in most artificial systems. We explore the possibility of such a system in the context of cooperative object manipulation using mobile robots. Although conventional works demonstrate potential solutions for the problem in restricted settings, they have computational and learning difficulties. More importantly, these systems do not possess the ability to adapt when facing environmental changes. In this work, we show that by distilling a planner derived from a gradient-based soft-body physics simulator into an attention-based neural network, our multi-robot manipulation system can achieve better performance than baselines. In addition, our system also generalizes to unseen configurations during training and is able to adapt toward task completions when external turbulence and environmental changes are applied.
World Robot Challenge 2020 -- Partner Robot: A Data-Driven Approach for Room Tidying with Mobile Manipulator
Jul 22, 2022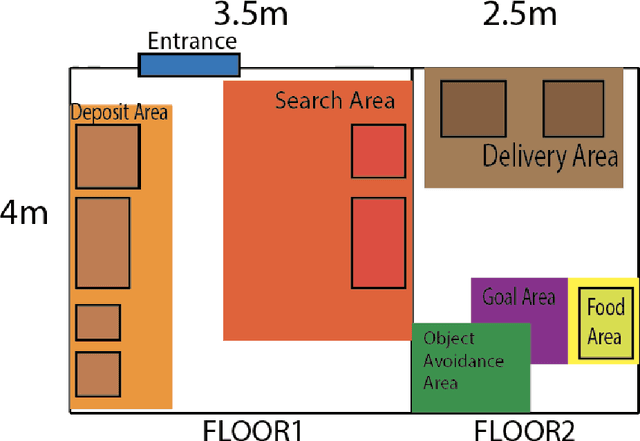


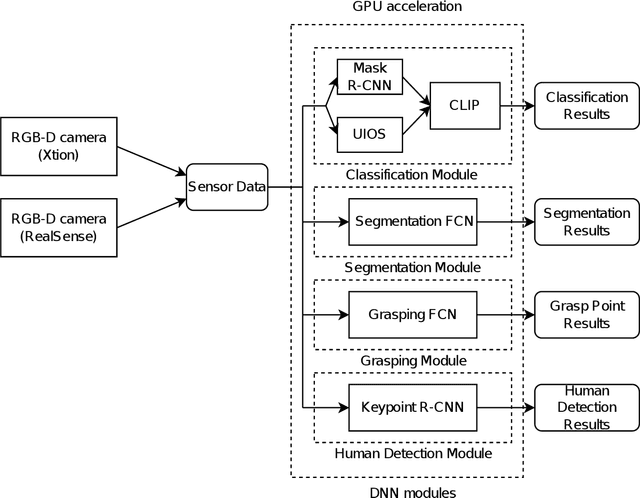
Tidying up a household environment using a mobile manipulator poses various challenges in robotics, such as adaptation to large real-world environmental variations, and safe and robust deployment in the presence of humans.The Partner Robot Challenge in World Robot Challenge (WRC) 2020, a global competition held in September 2021, benchmarked tidying tasks in the real home environments, and importantly, tested for full system performances.For this challenge, we developed an entire household service robot system, which leverages a data-driven approach to adapt to numerous edge cases that occur during the execution, instead of classical manual pre-programmed solutions. In this paper, we describe the core ingredients of the proposed robot system, including visual recognition, object manipulation, and motion planning. Our robot system won the second prize, verifying the effectiveness and potential of data-driven robot systems for mobile manipulation in home environments.
Tool as Embodiment for Recursive Manipulation
Dec 01, 2021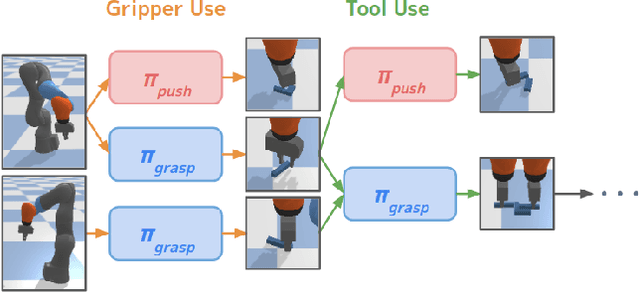
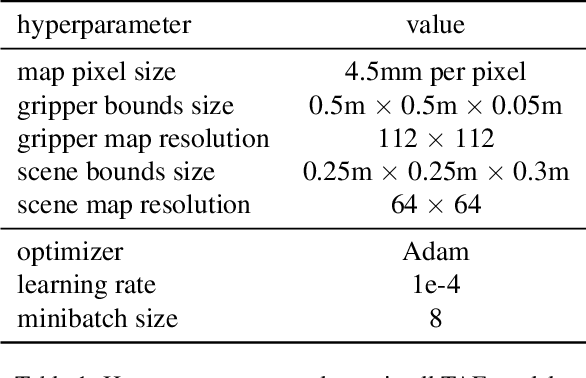
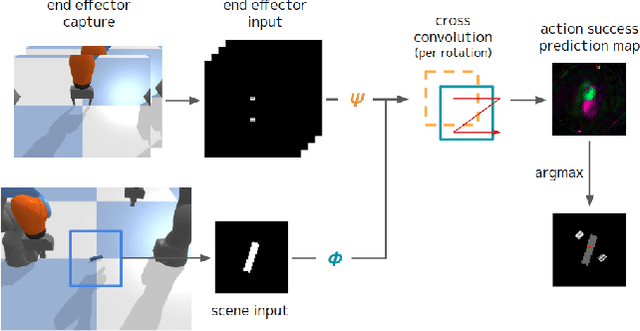
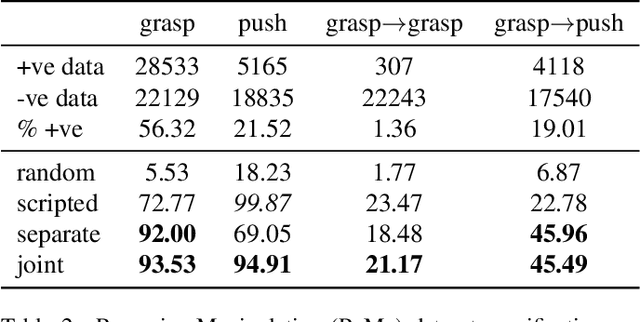
Humans and many animals exhibit a robust capability to manipulate diverse objects, often directly with their bodies and sometimes indirectly with tools. Such flexibility is likely enabled by the fundamental consistency in underlying physics of object manipulation such as contacts and force closures. Inspired by viewing tools as extensions of our bodies, we present Tool-As-Embodiment (TAE), a parameterization for tool-based manipulation policies that treat hand-object and tool-object interactions in the same representation space. The result is a single policy that can be applied recursively on robots to use end effectors to manipulate objects, and use objects as tools, i.e. new end-effectors, to manipulate other objects. By sharing experiences across different embodiments for grasping or pushing, our policy exhibits higher performance than if separate policies were trained. Our framework could utilize all experiences from different resolutions of tool-enabled embodiments to a single generic policy for each manipulation skill. Videos at https://sites.google.com/view/recursivemanipulation