 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers
Mar 19, 2024



While large-scale robotic systems typically rely on textual instructions for tasks, this work explores a different approach: can robots infer the task directly from observing humans? This shift necessitates the robot's ability to decode human intent and translate it into executable actions within its physical constraints and environment. We introduce Vid2Robot, a novel end-to-end video-based learning framework for robots. Given a video demonstration of a manipulation task and current visual observations, Vid2Robot directly produces robot actions. This is achieved through a unified representation model trained on a large dataset of human video and robot trajectory. The model leverages cross-attention mechanisms to fuse prompt video features to the robot's current state and generate appropriate actions that mimic the observed task. To further improve policy performance, we propose auxiliary contrastive losses that enhance the alignment between human and robot video representations. We evaluate Vid2Robot on real-world robots, demonstrating a 20% improvement in performance compared to other video-conditioned policies when using human demonstration videos. Additionally, our model exhibits emergent capabilities, such as successfully transferring observed motions from one object to another, and long-horizon composition, thus showcasing its potential for real-world applications. Project website: vid2robot.github.io
AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
Jan 23, 2024Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
Visual Backtracking Teleoperation: A Data Collection Protocol for Offline Image-Based Reinforcement Learning
Oct 05, 2022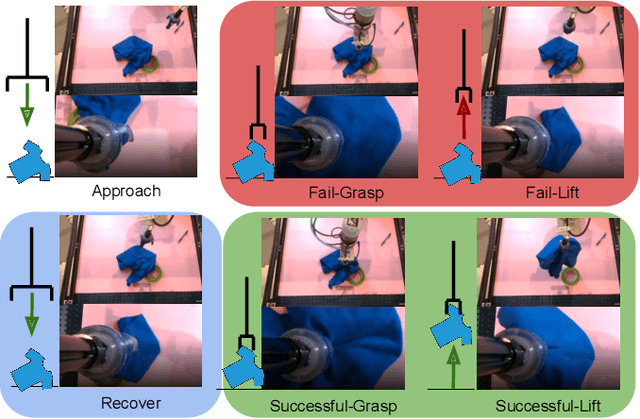
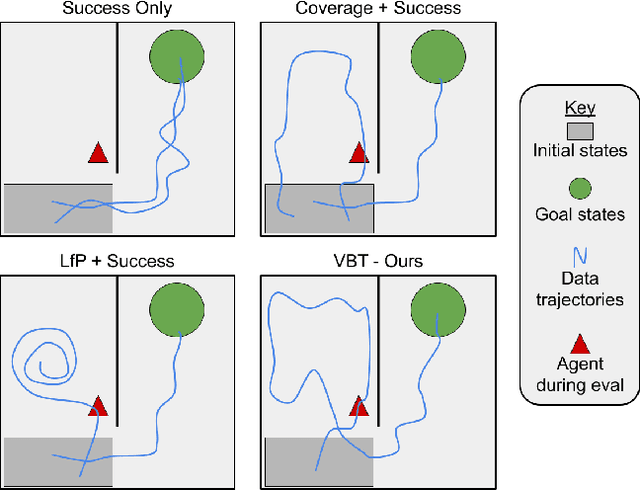
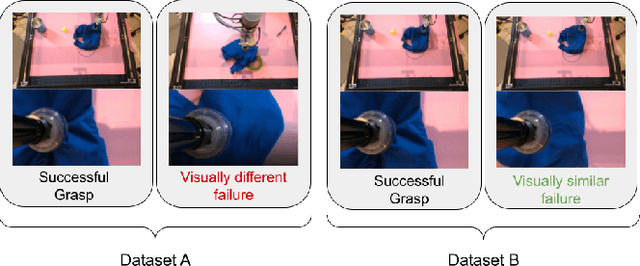
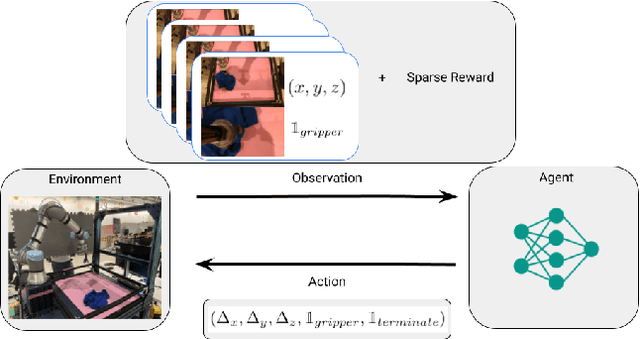
We consider how to most efficiently leverage teleoperator time to collect data for learning robust image-based value functions and policies for sparse reward robotic tasks. To accomplish this goal, we modify the process of data collection to include more than just successful demonstrations of the desired task. Instead we develop a novel protocol that we call Visual Backtracking Teleoperation (VBT), which deliberately collects a dataset of visually similar failures, recoveries, and successes. VBT data collection is particularly useful for efficiently learning accurate value functions from small datasets of image-based observations. We demonstrate VBT on a real robot to perform continuous control from image observations for the deformable manipulation task of T-shirt grasping. We find that by adjusting the data collection process we improve the quality of both the learned value functions and policies over a variety of baseline methods for data collection. Specifically, we find that offline reinforcement learning on VBT data outperforms standard behavior cloning on successful demonstration data by 13% when both methods are given equal-sized datasets of 60 minutes of data from the real robot.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022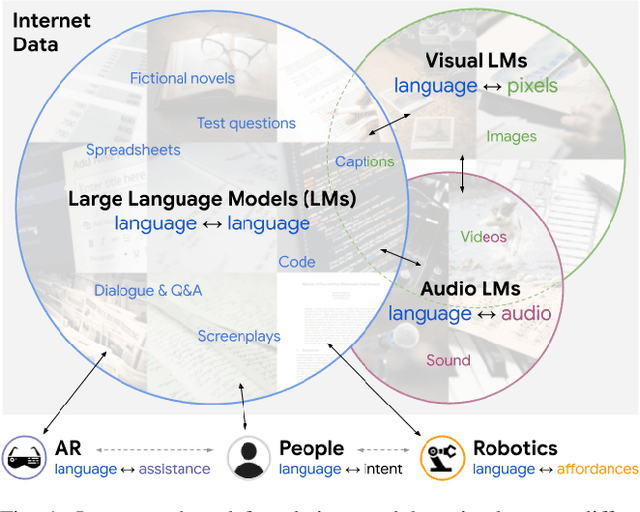
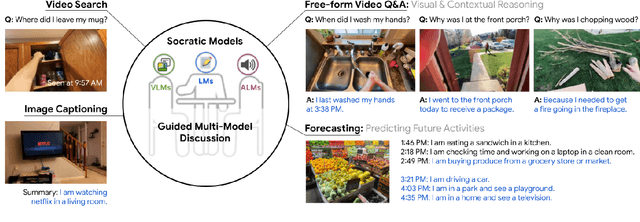
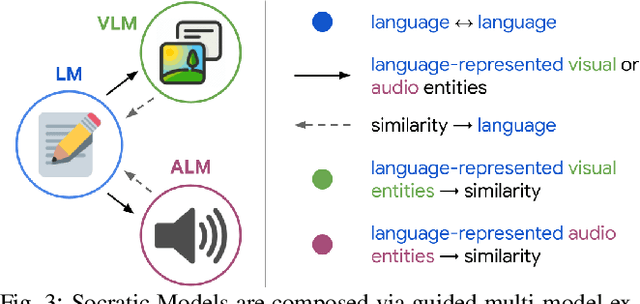
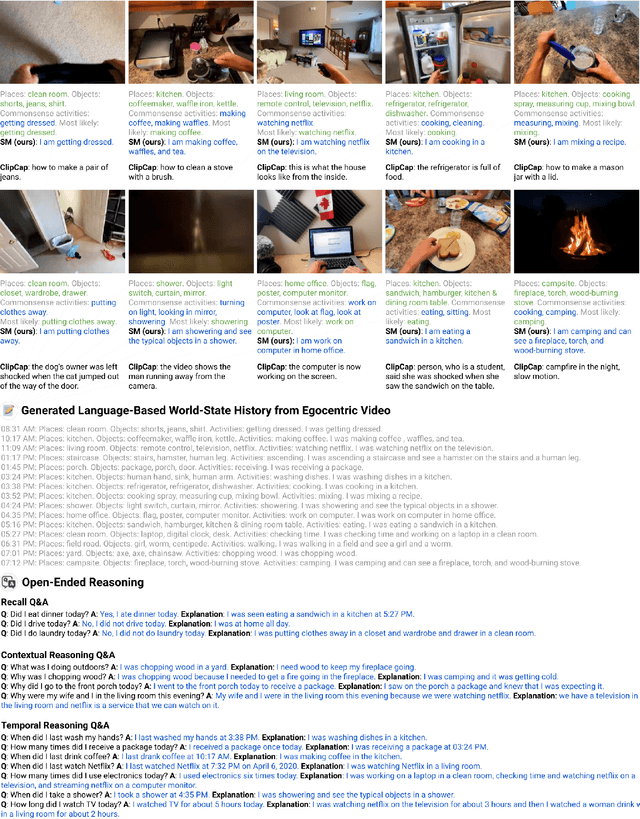
Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
Oct 27, 2020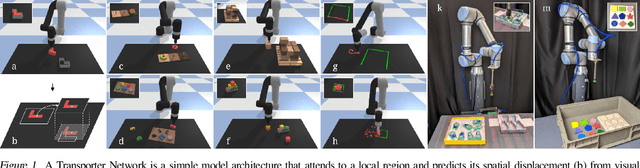
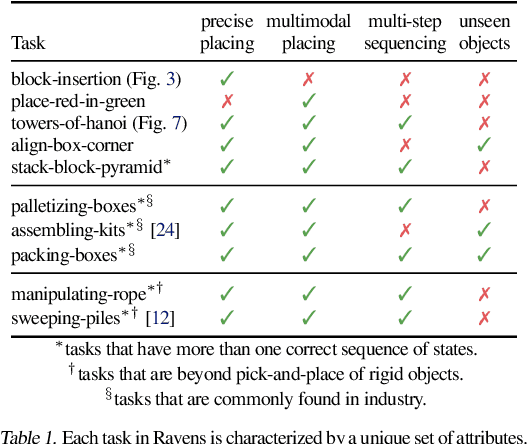
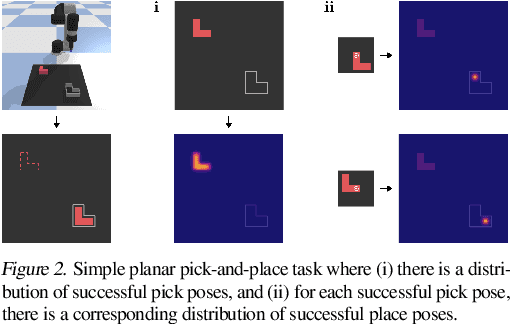
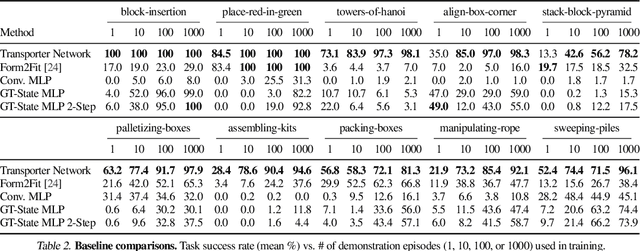
Robotic manipulation can be formulated as inducing a sequence of spatial displacements: where the space being moved can encompass an object, part of an object, or end effector. In this work, we propose the Transporter Network, a simple model architecture that rearranges deep features to infer spatial displacements from visual input - which can parameterize robot actions. It makes no assumptions of objectness (e.g. canonical poses, models, or keypoints), it exploits spatial symmetries, and is orders of magnitude more sample efficient than our benchmarked alternatives in learning vision-based manipulation tasks: from stacking a pyramid of blocks, to assembling kits with unseen objects; from manipulating deformable ropes, to pushing piles of small objects with closed-loop feedback. Our method can represent complex multi-modal policy distributions and generalizes to multi-step sequential tasks, as well as 6DoF pick-and-place. Experiments on 10 simulated tasks show that it learns faster and generalizes better than a variety of end-to-end baselines, including policies that use ground-truth object poses. We validate our methods with hardware in the real world. Experiment videos and code will be made available at https://transporternets.github.io
Learning Synergies between Pushing and Grasping with Self-supervised Deep Reinforcement Learning
Sep 30, 2018
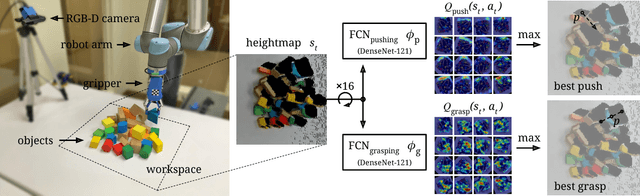
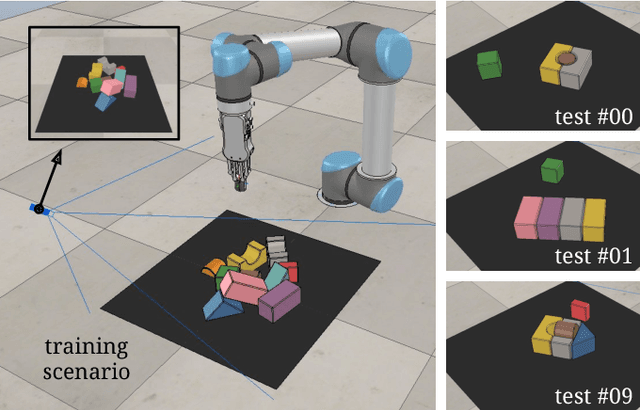
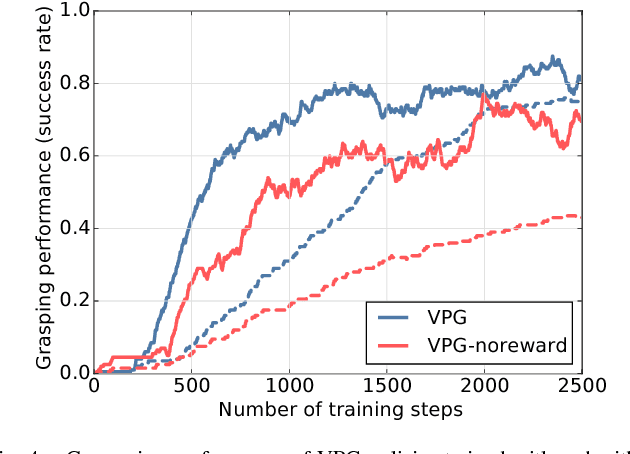
Skilled robotic manipulation benefits from complex synergies between non-prehensile (e.g. pushing) and prehensile (e.g. grasping) actions: pushing can help rearrange cluttered objects to make space for arms and fingers; likewise, grasping can help displace objects to make pushing movements more precise and collision-free. In this work, we demonstrate that it is possible to discover and learn these synergies from scratch through model-free deep reinforcement learning. Our method involves training two fully convolutional networks that map from visual observations to actions: one infers the utility of pushes for a dense pixel-wise sampling of end effector orientations and locations, while the other does the same for grasping. Both networks are trained jointly in a Q-learning framework and are entirely self-supervised by trial and error, where rewards are provided from successful grasps. In this way, our policy learns pushing motions that enable future grasps, while learning grasps that can leverage past pushes. During picking experiments in both simulation and real-world scenarios, we find that our system quickly learns complex behaviors amid challenging cases of clutter, and achieves better grasping success rates and picking efficiencies than baseline alternatives after only a few hours of training. We further demonstrate that our method is capable of generalizing to novel objects. Qualitative results (videos), code, pre-trained models, and simulation environments are available at http://vpg.cs.princeton.edu