 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Universal Grasping
Jun 15, 2026Humans can grasp objects effortlessly, whereas multi-fingered robots are far from this level of generality. We argue that the most natural source of robot grasping data is from humans, who pick up thousands of objects every day. We present HUG, a flow-matching model that generates diverse human grasps for any user-specified object in a single RGB-D image captured from a stereo camera. Using smart glasses, we first collect 1M-HUGs, an egocentric dataset of human grasps spanning 1M frames (27.8 hrs) and 6,707 object instances across 41 buildings. Next, to model the distribution of natural human grasps, our novel flow-matching model fuses RGB and depth observations to output a grasp parameterized by wrist translation, wrist rotation, and MANO hand pose. Predicted grasps can be retargeted to various robot hands, enabling zero-shot grasping in everyday scenes. To standardize evaluation, we build a new simulated benchmark, HUG-Bench, of 90 unseen objects from five geometric categories and various sizes, with metric-scale 3D meshes. We evaluate HUG in the real world on the 30-object test set of HUG-Bench across multiple stereo cameras, robot embodiments, and household environments. HUG outperforms the state-of-the-art grasping baselines by +23% and +34% on our challenging object set. Code, data, benchmark, checkpoints, and an interactive demo are released on our website: https://grasping.io/
Ruka-v2: Tendon Driven Open-Source Dexterous Hand with Wrist and Abduction for Robot Learning
Mar 27, 2026Lack of accessible and dexterous robot hardware has been a significant bottleneck to achieving human-level dexterity in robots. Last year, we released Ruka, a fully open-sourced, tendon-driven humanoid hand with 11 degrees of freedom - 2 per finger and 3 at the thumb - buildable for under $1,300. It was one of the first fully open-sourced humanoid hands, and introduced a novel data-driven approach to finger control that captures tendon dynamics within the control system. Despite these contributions, Ruka lacked two degrees of freedom essential for closely imitating human behavior: wrist mobility and finger adduction/abduction. In this paper, we introduce Ruka-v2: a fully open-sourced, tendon-driven humanoid hand featuring a decoupled 2-DOF parallel wrist and abduction/adduction at the fingers. The parallel wrist adds smooth, independent flexion/extension and radial/ulnar deviation, enabling manipulation in confined environments such as cabinets. Abduction enables motions such as grasping thin objects, in-hand rotation, and calligraphy. We present the design of Ruka-v2 and evaluate it against Ruka through user studies on teleoperated tasks, finding a 51.3% reduction in completion time and a 21.2% increase in success rate. We further demonstrate its full range of applications for robot learning: bimanual and single-arm teleoperation across 13 dexterous tasks, and autonomous policy learning on 3 tasks. All 3D print files, assembly instructions, controller software, and videos are available at https://ruka-hand-v2.github.io/ .
Quality over Quantity: Demonstration Curation via Influence Functions for Data-Centric Robot Learning
Mar 10, 2026Learning from demonstrations has emerged as a promising paradigm for end-to-end robot control, particularly when scaled to diverse and large datasets. However, the quality of demonstration data, often collected through human teleoperation, remains a critical bottleneck for effective data-driven robot learning. Human errors, operational constraints, and teleoperator variability introduce noise and suboptimal behaviors, making data curation essential yet largely manual and heuristic-driven. In this work, we propose Quality over Quantity (QoQ), a grounded and systematic approach to identifying high-quality data by defining data quality as the contribution of each training sample to reducing loss on validation demonstrations. To efficiently estimate this contribution, we leverage influence functions, which quantify the impact of individual training samples on model performance. We further introduce two key techniques to adapt influence functions for robot demonstrations: (i) using maximum influence across validation samples to capture the most relevant state-action pairs, and (ii) aggregating influence scores of state-action pairs within the same trajectory to reduce noise and improve data coverage. Experiments in both simulated and real-world settings show that QoQ consistently improves policy performances over prior data selection methods.
YOR: Your Own Mobile Manipulator for Generalizable Robotics
Feb 11, 2026Recent advances in robot learning have generated significant interest in capable platforms that may eventually approach human-level competence. This interest, combined with the commoditization of actuators, has propelled growth in low-cost robotic platforms. However, the optimal form factor for mobile manipulation, especially on a budget, remains an open question. We introduce YOR, an open-source, low-cost mobile manipulator that integrates an omnidirectional base, a telescopic vertical lift, and two arms with grippers to achieve whole-body mobility and manipulation. Our design emphasizes modularity, ease of assembly using off-the-shelf components, and affordability, with a bill-of-materials cost under 10,000 USD. We demonstrate YOR's capability by completing tasks that require coordinated whole-body control, bimanual manipulation, and autonomous navigation. Overall, YOR offers competitive functionality for mobile manipulation research at a fraction of the cost of existing platforms. Project website: https://www.yourownrobot.ai/
Contact-Anchored Policies: Contact Conditioning Creates Strong Robot Utility Models
Feb 09, 2026The prevalent paradigm in robot learning attempts to generalize across environments, embodiments, and tasks with language prompts at runtime. A fundamental tension limits this approach: language is often too abstract to guide the concrete physical understanding required for robust manipulation. In this work, we introduce Contact-Anchored Policies (CAP), which replace language conditioning with points of physical contact in space. Simultaneously, we structure CAP as a library of modular utility models rather than a monolithic generalist policy. This factorization allows us to implement a real-to-sim iteration cycle: we build EgoGym, a lightweight simulation benchmark, to rapidly identify failure modes and refine our models and datasets prior to real-world deployment. We show that by conditioning on contact and iterating via simulation, CAP generalizes to novel environments and embodiments out of the box on three fundamental manipulation skills while using only 23 hours of demonstration data, and outperforms large, state-of-the-art VLAs in zero-shot evaluations by 56%. All model checkpoints, codebase, hardware, simulation, and datasets will be open-sourced. Project page: https://cap-policy.github.io/
Point Bridge: 3D Representations for Cross Domain Policy Learning
Jan 24, 2026Robot foundation models are beginning to deliver on the promise of generalist robotic agents, yet progress remains constrained by the scarcity of large-scale real-world manipulation datasets. Simulation and synthetic data generation offer a scalable alternative, but their usefulness is limited by the visual domain gap between simulation and reality. In this work, we present Point Bridge, a framework that leverages unified, domain-agnostic point-based representations to unlock synthetic datasets for zero-shot sim-to-real policy transfer, without explicit visual or object-level alignment. Point Bridge combines automated point-based representation extraction via Vision-Language Models (VLMs), transformer-based policy learning, and efficient inference-time pipelines to train capable real-world manipulation agents using only synthetic data. With additional co-training on small sets of real demonstrations, Point Bridge further improves performance, substantially outperforming prior vision-based sim-and-real co-training methods. It achieves up to 44% gains in zero-shot sim-to-real transfer and up to 66% with limited real data across both single-task and multitask settings. Videos of the robot are best viewed at: https://pointbridge3d.github.io/
Touch begins where vision ends: Generalizable policies for contact-rich manipulation
Jun 16, 2025Data-driven approaches struggle with precise manipulation; imitation learning requires many hard-to-obtain demonstrations, while reinforcement learning yields brittle, non-generalizable policies. We introduce VisuoTactile Local (ViTaL) policy learning, a framework that solves fine-grained manipulation tasks by decomposing them into two phases: a reaching phase, where a vision-language model (VLM) enables scene-level reasoning to localize the object of interest, and a local interaction phase, where a reusable, scene-agnostic ViTaL policy performs contact-rich manipulation using egocentric vision and tactile sensing. This approach is motivated by the observation that while scene context varies, the low-level interaction remains consistent across task instances. By training local policies once in a canonical setting, they can generalize via a localize-then-execute strategy. ViTaL achieves around 90% success on contact-rich tasks in unseen environments and is robust to distractors. ViTaL's effectiveness stems from three key insights: (1) foundation models for segmentation enable training robust visual encoders via behavior cloning; (2) these encoders improve the generalizability of policies learned using residual RL; and (3) tactile sensing significantly boosts performance in contact-rich tasks. Ablation studies validate each of these insights, and we demonstrate that ViTaL integrates well with high-level VLMs, enabling robust, reusable low-level skills. Results and videos are available at https://vitalprecise.github.io.
eFlesh: Highly customizable Magnetic Touch Sensing using Cut-Cell Microstructures
Jun 11, 2025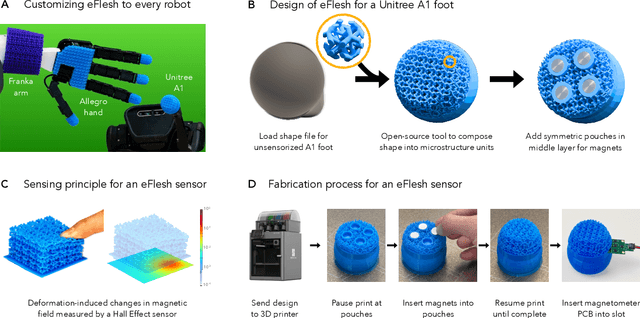


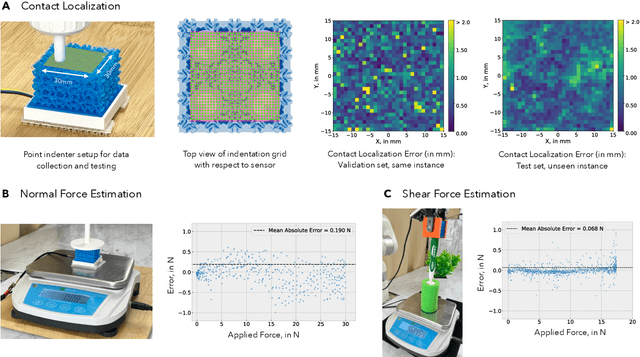
If human experience is any guide, operating effectively in unstructured environments -- like homes and offices -- requires robots to sense the forces during physical interaction. Yet, the lack of a versatile, accessible, and easily customizable tactile sensor has led to fragmented, sensor-specific solutions in robotic manipulation -- and in many cases, to force-unaware, sensorless approaches. With eFlesh, we bridge this gap by introducing a magnetic tactile sensor that is low-cost, easy to fabricate, and highly customizable. Building an eFlesh sensor requires only four components: a hobbyist 3D printer, off-the-shelf magnets (<$5), a CAD model of the desired shape, and a magnetometer circuit board. The sensor is constructed from tiled, parameterized microstructures, which allow for tuning the sensor's geometry and its mechanical response. We provide an open-source design tool that converts convex OBJ/STL files into 3D-printable STLs for fabrication. This modular design framework enables users to create application-specific sensors, and to adjust sensitivity depending on the task. Our sensor characterization experiments demonstrate the capabilities of eFlesh: contact localization RMSE of 0.5 mm, and force prediction RMSE of 0.27 N for normal force and 0.12 N for shear force. We also present a learned slip detection model that generalizes to unseen objects with 95% accuracy, and visuotactile control policies that improve manipulation performance by 40% over vision-only baselines -- achieving 91% average success rate for four precise tasks that require sub-mm accuracy for successful completion. All design files, code and the CAD-to-eFlesh STL conversion tool are open-sourced and available on https://e-flesh.com.
EgoZero: Robot Learning from Smart Glasses
May 26, 2025



Despite recent progress in general purpose robotics, robot policies still lag far behind basic human capabilities in the real world. Humans interact constantly with the physical world, yet this rich data resource remains largely untapped in robot learning. We propose EgoZero, a minimal system that learns robust manipulation policies from human demonstrations captured with Project Aria smart glasses, $\textbf{and zero robot data}$. EgoZero enables: (1) extraction of complete, robot-executable actions from in-the-wild, egocentric, human demonstrations, (2) compression of human visual observations into morphology-agnostic state representations, and (3) closed-loop policy learning that generalizes morphologically, spatially, and semantically. We deploy EgoZero policies on a gripper Franka Panda robot and demonstrate zero-shot transfer with 70% success rate over 7 manipulation tasks and only 20 minutes of data collection per task. Our results suggest that in-the-wild human data can serve as a scalable foundation for real-world robot learning - paving the way toward a future of abundant, diverse, and naturalistic training data for robots. Code and videos are available at https://egozero-robot.github.io.
RUKA: Rethinking the Design of Humanoid Hands with Learning
Apr 17, 2025Dexterous manipulation is a fundamental capability for robotic systems, yet progress has been limited by hardware trade-offs between precision, compactness, strength, and affordability. Existing control methods impose compromises on hand designs and applications. However, learning-based approaches present opportunities to rethink these trade-offs, particularly to address challenges with tendon-driven actuation and low-cost materials. This work presents RUKA, a tendon-driven humanoid hand that is compact, affordable, and capable. Made from 3D-printed parts and off-the-shelf components, RUKA has 5 fingers with 15 underactuated degrees of freedom enabling diverse human-like grasps. Its tendon-driven actuation allows powerful grasping in a compact, human-sized form factor. To address control challenges, we learn joint-to-actuator and fingertip-to-actuator models from motion-capture data collected by the MANUS glove, leveraging the hand's morphological accuracy. Extensive evaluations demonstrate RUKA's superior reachability, durability, and strength compared to other robotic hands. Teleoperation tasks further showcase RUKA's dexterous movements. The open-source design and assembly instructions of RUKA, code, and data are available at https://ruka-hand.github.io/.