 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024



An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
RT-1: Robotics Transformer for Real-World Control at Scale
Dec 13, 2022



By transferring knowledge from large, diverse, task-agnostic datasets, modern machine learning models can solve specific downstream tasks either zero-shot or with small task-specific datasets to a high level of performance. While this capability has been demonstrated in other fields such as computer vision, natural language processing or speech recognition, it remains to be shown in robotics, where the generalization capabilities of the models are particularly critical due to the difficulty of collecting real-world robotic data. We argue that one of the keys to the success of such general robotic models lies with open-ended task-agnostic training, combined with high-capacity architectures that can absorb all of the diverse, robotic data. In this paper, we present a model class, dubbed Robotics Transformer, that exhibits promising scalable model properties. We verify our conclusions in a study of different model classes and their ability to generalize as a function of the data size, model size, and data diversity based on a large-scale data collection on real robots performing real-world tasks. The project's website and videos can be found at robotics-transformer.github.io
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022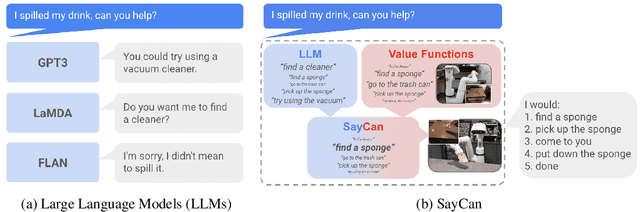
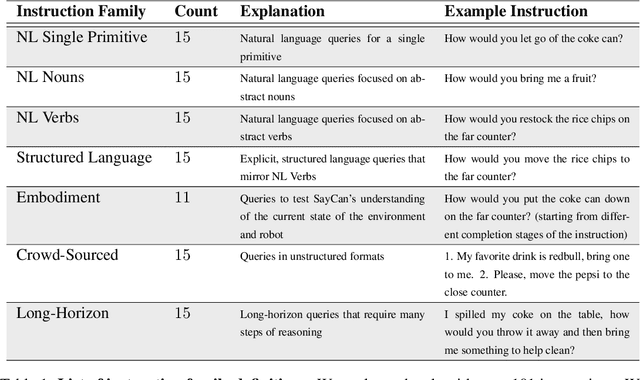
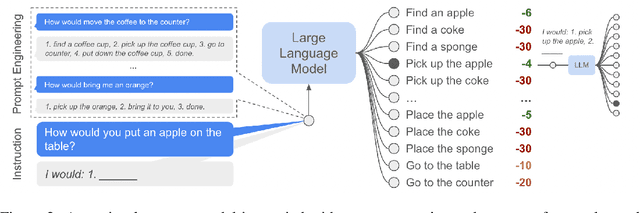
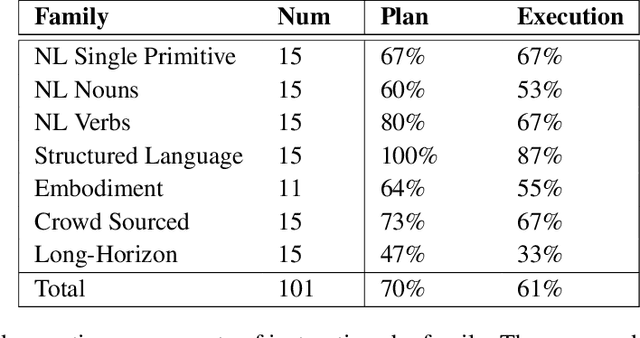
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/
RL-RRT: Kinodynamic Motion Planning via Learning Reachability Estimators from RL Policies
Jul 12, 2019


This paper addresses two challenges facing sampling-based kinodynamic motion planning: a way to identify good candidate states for local transitions and the subsequent computationally intractable steering between these candidate states. Through the combination of sampling-based planning, a Rapidly Exploring Randomized Tree (RRT) and an efficient kinodynamic motion planner through machine learning, we propose an efficient solution to long-range planning for kinodynamic motion planning. First, we use deep reinforcement learning to learn an obstacle-avoiding policy that maps a robot's sensor observations to actions, which is used as a local planner during planning and as a controller during execution. Second, we train a reachability estimator in a supervised manner, which predicts the RL policy's time to reach a state in the presence of obstacles. Lastly, we introduce RL-RRT that uses the RL policy as a local planner, and the reachability estimator as the distance function to bias tree-growth towards promising regions. We evaluate our method on three kinodynamic systems, including physical robot experiments. Results across all three robots tested indicate that RL-RRT outperforms state of the art kinodynamic planners in efficiency, and also provides a shorter path finish time than a steering function free method. The learned local planner policy and accompanying reachability estimator demonstrate transferability to the previously unseen experimental environments, making RL-RRT fast because the expensive computations are replaced with simple neural network inference. Video: https://youtu.be/dDMVMTOI8KY
* Accepted to Robotics and Automation Letters in June 2019
Data-Efficient Learning for Sim-to-Real Robotic Grasping using Deep Point Cloud Prediction Networks
Jun 21, 2019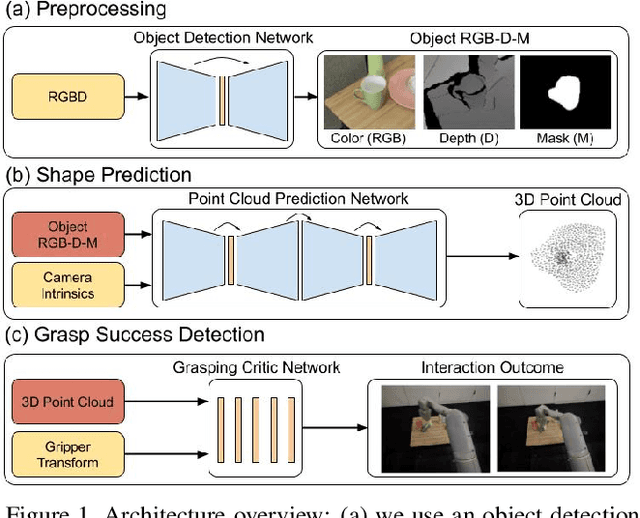
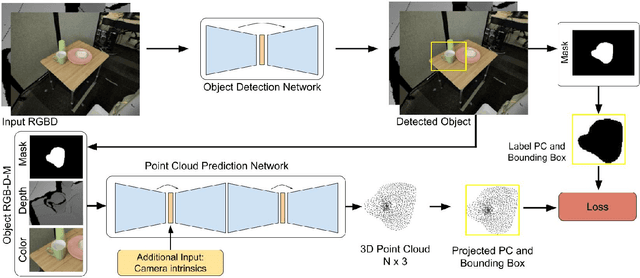
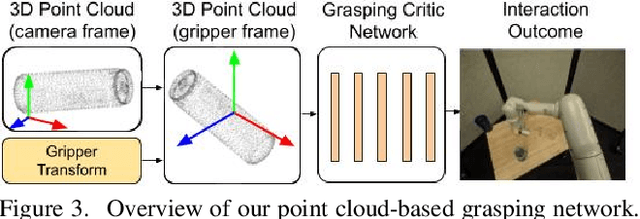
Training a deep network policy for robot manipulation is notoriously costly and time consuming as it depends on collecting a significant amount of real world data. To work well in the real world, the policy needs to see many instances of the task, including various object arrangements in the scene as well as variations in object geometry, texture, material, and environmental illumination. In this paper, we propose a method that learns to perform table-top instance grasping of a wide variety of objects while using no real world grasping data, outperforming the baseline using 2.5D shape by 10%. Our method learns 3D point cloud of object, and use that to train a domain-invariant grasping policy. We formulate the learning process as a two-step procedure: 1) Learning a domain-invariant 3D shape representation of objects from about 76K episodes in simulation and about 530 episodes in the real world, where each episode lasts less than a minute and 2) Learning a critic grasping policy in simulation only based on the 3D shape representation from step 1. Our real world data collection in step 1 is both cheaper and faster compared to existing approaches as it only requires taking multiple snapshots of the scene using a RGBD camera. Finally, the learned 3D representation is not specific to grasping, and can potentially be used in other interaction tasks.
When random search is not enough: Sample-Efficient and Noise-Robust Blackbox Optimization of RL Policies
Mar 07, 2019
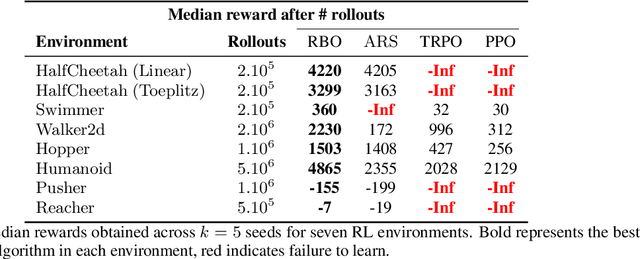
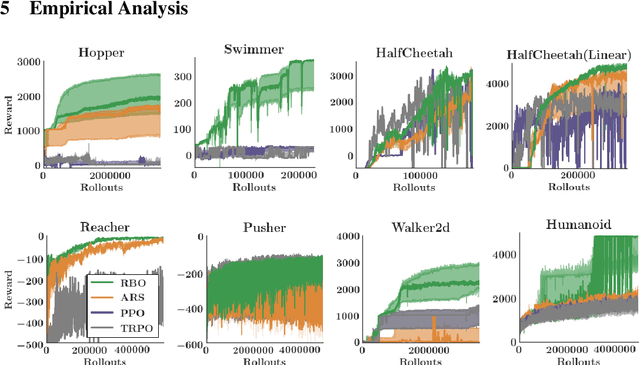

Interest in derivative-free optimization (DFO) and "evolutionary strategies" (ES) has recently surged in the Reinforcement Learning (RL) community, with growing evidence that they match state of the art methods for policy optimization tasks. However, blackbox DFO methods suffer from high sampling complexity since they require a substantial number of policy rollouts for reliable updates. They can also be very sensitive to noise in the rewards, actuators or the dynamics of the environment. In this paper we propose to replace the standard ES derivative-free paradigm for RL based on simple reward-weighted averaged random perturbations for policy updates, that has recently become a subject of voluminous research, by an algorithm where gradients of blackbox RL functions are estimated via regularized regression methods. In particular, we propose to use L1/L2 regularized regression-based gradient estimation to exploit sparsity and smoothness, as well as LP decoding techniques for handling adversarial stochastic and deterministic noise. Our methods can be naturally aligned with sliding trust region techniques for efficient samples reuse to further reduce sampling complexity. This is not the case for standard ES methods requiring independent sampling in each epoch. We show that our algorithms can be applied in locomotion tasks, where training is conducted in the presence of substantial noise, e.g. for learning in sim transferable stable walking behaviors for quadruped robots or training quadrupeds how to follow a path. We further demonstrate our methods on several $\mathrm{OpenAI}$ $\mathrm{Gym}$ $\mathrm{Mujoco}$ RL tasks. We manage to train effective policies even if up to $25\%$ of all measurements are arbitrarily corrupted, where standard ES methods produce sub-optimal policies or do not manage to learn at all. Our empirical results are backed by theoretical guarantees.
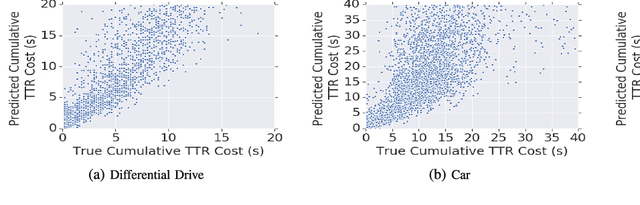
Long-Range Indoor Navigation with PRM-RL
Feb 25, 2019
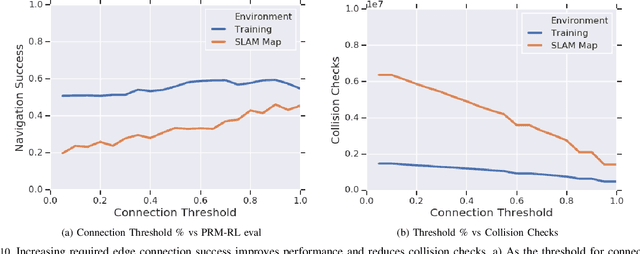
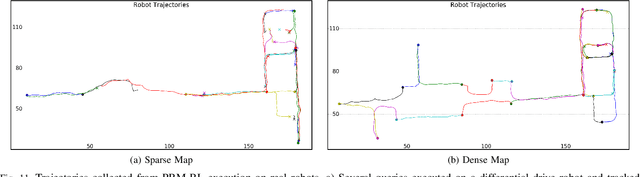
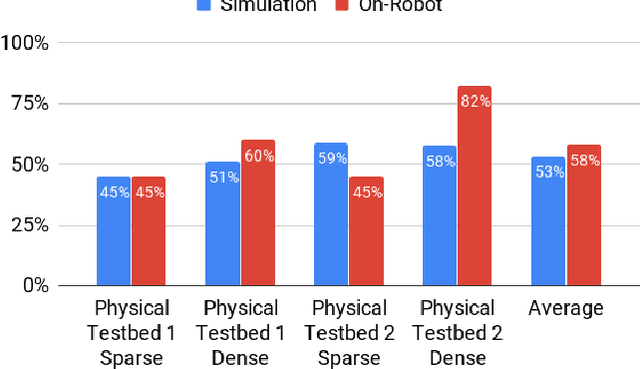
Long-range indoor navigation requires guiding robots with noisy sensors and controls through cluttered environments along paths that span a variety of buildings. We achieve this with PRM-RL, a hierarchical robot navigation method in which reinforcement learning agents that map noisy sensors to robot controls learn to solve short-range obstacle avoidance tasks, and then sampling-based planners map where these agents can reliably navigate in simulation; these roadmaps and agents are then deployed on-robot, guiding the robot along the shortest path where the agents are likely to succeed. Here we use Probabilistic Roadmaps (PRMs) as the sampling-based planner and AutoRL as the reinforcement learning method in the indoor navigation context. We evaluate the method in simulation for kinematic differential drive and kinodynamic car-like robots in several environments, and on-robot for differential-drive robots at two physical sites. Our results show PRM-RL with AutoRL is more successful than several baselines, is robust to noise, and can guide robots over hundreds of meters in the face of noise and obstacles in both simulation and on-robot, including over 3.3 kilometers of physical robot navigation.