 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving Embodied Foundation Models
Sep 18, 2025Foundation models trained on web-scale data have revolutionized robotics, but their application to low-level control remains largely limited to behavioral cloning. Drawing inspiration from the success of the reinforcement learning stage in fine-tuning large language models, we propose a two-stage post-training approach for robotics. The first stage, Supervised Fine-Tuning (SFT), fine-tunes pretrained foundation models using both: a) behavioral cloning, and b) steps-to-go prediction objectives. In the second stage, Self-Improvement, steps-to-go prediction enables the extraction of a well-shaped reward function and a robust success detector, enabling a fleet of robots to autonomously practice downstream tasks with minimal human supervision. Through extensive experiments on real-world and simulated robot embodiments, our novel post-training recipe unveils significant results on Embodied Foundation Models. First, we demonstrate that the combination of SFT and Self-Improvement is significantly more sample-efficient than scaling imitation data collection for supervised learning, and that it leads to policies with significantly higher success rates. Further ablations highlight that the combination of web-scale pretraining and Self-Improvement is the key to this sample-efficiency. Next, we demonstrate that our proposed combination uniquely unlocks a capability that current methods cannot achieve: autonomously practicing and acquiring novel skills that generalize far beyond the behaviors observed in the imitation learning datasets used during training. These findings highlight the transformative potential of combining pretrained foundation models with online Self-Improvement to enable autonomous skill acquisition in robotics. Our project website can be found at https://self-improving-efms.github.io .
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Robot Data Curation with Mutual Information Estimators
Feb 12, 2025The performance of imitation learning policies often hinges on the datasets with which they are trained. Consequently, investment in data collection for robotics has grown across both industrial and academic labs. However, despite the marked increase in the quantity of demonstrations collected, little work has sought to assess the quality of said data despite mounting evidence of its importance in other areas such as vision and language. In this work, we take a critical step towards addressing the data quality in robotics. Given a dataset of demonstrations, we aim to estimate the relative quality of individual demonstrations in terms of both state diversity and action predictability. To do so, we estimate the average contribution of a trajectory towards the mutual information between states and actions in the entire dataset, which precisely captures both the entropy of the state distribution and the state-conditioned entropy of actions. Though commonly used mutual information estimators require vast amounts of data often beyond the scale available in robotics, we introduce a novel technique based on k-nearest neighbor estimates of mutual information on top of simple VAE embeddings of states and actions. Empirically, we demonstrate that our approach is able to partition demonstration datasets by quality according to human expert scores across a diverse set of benchmarks spanning simulation and real world environments. Moreover, training policies based on data filtered by our method leads to a 5-10% improvement in RoboMimic and better performance on real ALOHA and Franka setups.
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025
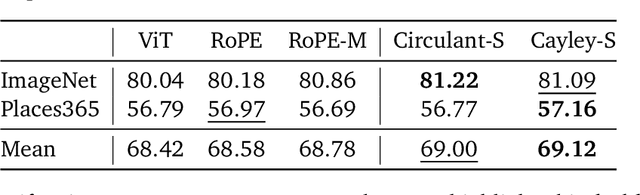
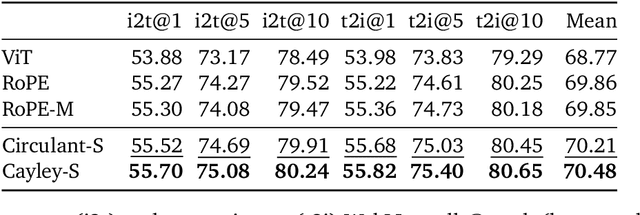

We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Vision Language Models are In-Context Value Learners
Nov 07, 2024



Predicting temporal progress from visual trajectories is important for intelligent robots that can learn, adapt, and improve. However, learning such progress estimator, or temporal value function, across different tasks and domains requires both a large amount of diverse data and methods which can scale and generalize. To address these challenges, we present Generative Value Learning (\GVL), a universal value function estimator that leverages the world knowledge embedded in vision-language models (VLMs) to predict task progress. Naively asking a VLM to predict values for a video sequence performs poorly due to the strong temporal correlation between successive frames. Instead, GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. Without any robot or task specific training, GVL can in-context zero-shot and few-shot predict effective values for more than 300 distinct real-world tasks across diverse robot platforms, including challenging bimanual manipulation tasks. Furthermore, we demonstrate that GVL permits flexible multi-modal in-context learning via examples from heterogeneous tasks and embodiments, such as human videos. The generality of GVL enables various downstream applications pertinent to visuomotor policy learning, including dataset filtering, success detection, and advantage-weighted regression -- all without any model training or finetuning.
ALOHA Unleashed: A Simple Recipe for Robot Dexterity
Oct 17, 2024Recent work has shown promising results for learning end-to-end robot policies using imitation learning. In this work we address the question of how far can we push imitation learning for challenging dexterous manipulation tasks. We show that a simple recipe of large scale data collection on the ALOHA 2 platform, combined with expressive models such as Diffusion Policies, can be effective in learning challenging bimanual manipulation tasks involving deformable objects and complex contact rich dynamics. We demonstrate our recipe on 5 challenging real-world and 3 simulated tasks and demonstrate improved performance over state-of-the-art baselines. The project website and videos can be found at aloha-unleashed.github.io.
Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers
Mar 19, 2024



While large-scale robotic systems typically rely on textual instructions for tasks, this work explores a different approach: can robots infer the task directly from observing humans? This shift necessitates the robot's ability to decode human intent and translate it into executable actions within its physical constraints and environment. We introduce Vid2Robot, a novel end-to-end video-based learning framework for robots. Given a video demonstration of a manipulation task and current visual observations, Vid2Robot directly produces robot actions. This is achieved through a unified representation model trained on a large dataset of human video and robot trajectory. The model leverages cross-attention mechanisms to fuse prompt video features to the robot's current state and generate appropriate actions that mimic the observed task. To further improve policy performance, we propose auxiliary contrastive losses that enhance the alignment between human and robot video representations. We evaluate Vid2Robot on real-world robots, demonstrating a 20% improvement in performance compared to other video-conditioned policies when using human demonstration videos. Additionally, our model exhibits emergent capabilities, such as successfully transferring observed motions from one object to another, and long-horizon composition, thus showcasing its potential for real-world applications. Project website: vid2robot.github.io
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
Feb 12, 2024



Vision language models (VLMs) have shown impressive capabilities across a variety of tasks, from logical reasoning to visual understanding. This opens the door to richer interaction with the world, for example robotic control. However, VLMs produce only textual outputs, while robotic control and other spatial tasks require outputting continuous coordinates, actions, or trajectories. How can we enable VLMs to handle such settings without fine-tuning on task-specific data? In this paper, we propose a novel visual prompting approach for VLMs that we call Prompting with Iterative Visual Optimization (PIVOT), which casts tasks as iterative visual question answering. In each iteration, the image is annotated with a visual representation of proposals that the VLM can refer to (e.g., candidate robot actions, localizations, or trajectories). The VLM then selects the best ones for the task. These proposals are iteratively refined, allowing the VLM to eventually zero in on the best available answer. We investigate PIVOT on real-world robotic navigation, real-world manipulation from images, instruction following in simulation, and additional spatial inference tasks such as localization. We find, perhaps surprisingly, that our approach enables zero-shot control of robotic systems without any robot training data, navigation in a variety of environments, and other capabilities. Although current performance is far from perfect, our work highlights potentials and limitations of this new regime and shows a promising approach for Internet-Scale VLMs in robotic and spatial reasoning domains. Website: pivot-prompt.github.io and HuggingFace: https://huggingface.co/spaces/pivot-prompt/pivot-prompt-demo.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.