 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue from Observations: Towards Large-Scale Imitation Learning via Self-Improvement
Jul 09, 2025Imitation Learning from Observation (IfO) offers a powerful way to learn behaviors at large-scale: Unlike behavior cloning or offline reinforcement learning, IfO can leverage action-free demonstrations and thus circumvents the need for costly action-labeled demonstrations or reward functions. However, current IfO research focuses on idealized scenarios with mostly bimodal-quality data distributions, restricting the meaningfulness of the results. In contrast, this paper investigates more nuanced distributions and introduces a method to learn from such data, moving closer to a paradigm in which imitation learning can be performed iteratively via self-improvement. Our method adapts RL-based imitation learning to action-free demonstrations, using a value function to transfer information between expert and non-expert data. Through comprehensive evaluation, we delineate the relation between different data distributions and the applicability of algorithms and highlight the limitations of established methods. Our findings provide valuable insights for developing more robust and practical IfO techniques on a path to scalable behaviour learning.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Deep SE(3)-Equivariant Geometric Reasoning for Precise Placement Tasks
Apr 20, 2024



Many robot manipulation tasks can be framed as geometric reasoning tasks, where an agent must be able to precisely manipulate an object into a position that satisfies the task from a set of initial conditions. Often, task success is defined based on the relationship between two objects - for instance, hanging a mug on a rack. In such cases, the solution should be equivariant to the initial position of the objects as well as the agent, and invariant to the pose of the camera. This poses a challenge for learning systems which attempt to solve this task by learning directly from high-dimensional demonstrations: the agent must learn to be both equivariant as well as precise, which can be challenging without any inductive biases about the problem. In this work, we propose a method for precise relative pose prediction which is provably SE(3)-equivariant, can be learned from only a few demonstrations, and can generalize across variations in a class of objects. We accomplish this by factoring the problem into learning an SE(3) invariant task-specific representation of the scene and then interpreting this representation with novel geometric reasoning layers which are provably SE(3) equivariant. We demonstrate that our method can yield substantially more precise placement predictions in simulated placement tasks than previous methods trained with the same amount of data, and can accurately represent relative placement relationships data collected from real-world demonstrations. Supplementary information and videos can be found at https://sites.google.com/view/reldist-iclr-2023.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Aug 31, 2023



For robots to be useful outside labs and specialized factories we need a way to teach them new useful behaviors quickly. Current approaches lack either the generality to onboard new tasks without task-specific engineering, or else lack the data-efficiency to do so in an amount of time that enables practical use. In this work we explore dense tracking as a representational vehicle to allow faster and more general learning from demonstration. Our approach utilizes Track-Any-Point (TAP) models to isolate the relevant motion in a demonstration, and parameterize a low-level controller to reproduce this motion across changes in the scene configuration. We show this results in robust robot policies that can solve complex object-arrangement tasks such as shape-matching, stacking, and even full path-following tasks such as applying glue and sticking objects together, all from demonstrations that can be collected in minutes.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Wish you were here: Hindsight Goal Selection for long-horizon dexterous manipulation
Dec 02, 2021
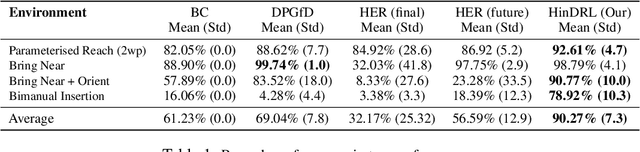
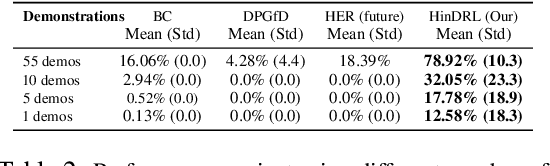

Complex sequential tasks in continuous-control settings often require agents to successfully traverse a set of "narrow passages" in their state space. Solving such tasks with a sparse reward in a sample-efficient manner poses a challenge to modern reinforcement learning (RL) due to the associated long-horizon nature of the problem and the lack of sufficient positive signal during learning. Various tools have been applied to address this challenge. When available, large sets of demonstrations can guide agent exploration. Hindsight relabelling on the other hand does not require additional sources of information. However, existing strategies explore based on task-agnostic goal distributions, which can render the solution of long-horizon tasks impractical. In this work, we extend hindsight relabelling mechanisms to guide exploration along task-specific distributions implied by a small set of successful demonstrations. We evaluate the approach on four complex, single and dual arm, robotics manipulation tasks against strong suitable baselines. The method requires far fewer demonstrations to solve all tasks and achieves a significantly higher overall performance as task complexity increases. Finally, we investigate the robustness of the proposed solution with respect to the quality of input representations and the number of demonstrations.
Learning Time-Invariant Reward Functions through Model-Based Inverse Reinforcement Learning
Jul 07, 2021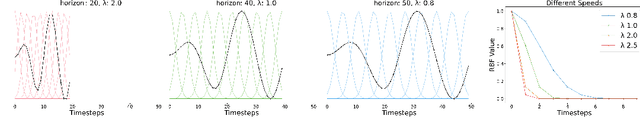
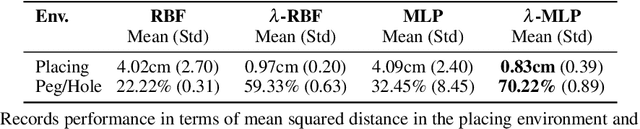

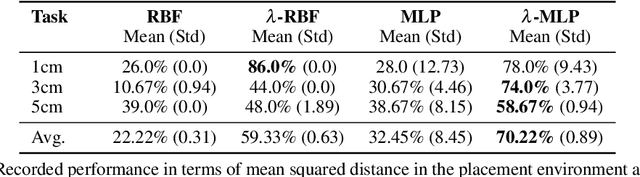
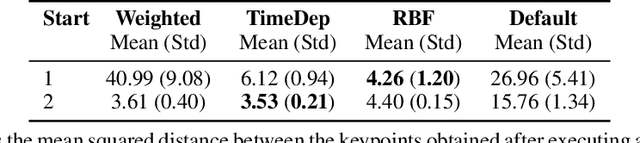
Inverse reinforcement learning is a paradigm motivated by the goal of learning general reward functions from demonstrated behaviours. Yet the notion of generality for learnt costs is often evaluated in terms of robustness to various spatial perturbations only, assuming deployment at fixed speeds of execution. However, this is impractical in the context of robotics and building time-invariant solutions is of crucial importance. In this work, we propose a formulation that allows us to 1) vary the length of execution by learning time-invariant costs, and 2) relax the temporal alignment requirements for learning from demonstration. We apply our method to two different types of cost formulations and evaluate their performance in the context of learning reward functions for simulated placement and peg in hole tasks. Our results show that our approach enables learning temporally invariant rewards from misaligned demonstration that can also generalise spatially to out of distribution tasks.
Model-Based Inverse Reinforcement Learning from Visual Demonstrations
Oct 18, 2020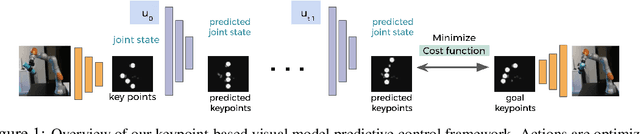
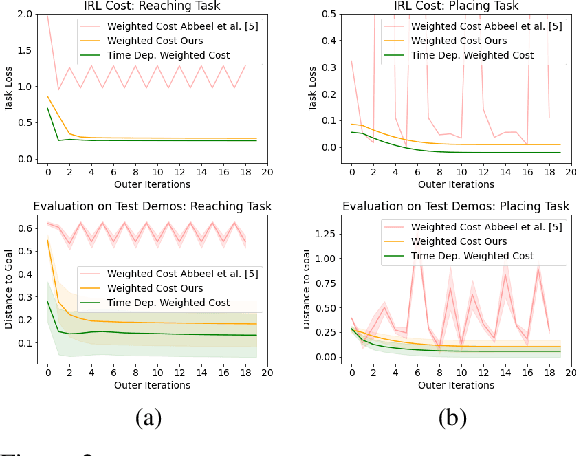

Scaling model-based inverse reinforcement learning (IRL) to real robotic manipulation tasks with unknown dynamics remains an open problem. The key challenges lie in learning good dynamics models, developing algorithms that scale to high-dimensional state-spaces and being able to learn from both visual and proprioceptive demonstrations. In this work, we present a gradient-based inverse reinforcement learning framework that utilizes a pre-trained visual dynamics model to learn cost functions when given only visual human demonstrations. The learned cost functions are then used to reproduce the demonstrated behavior via visual model predictive control. We evaluate our framework on hardware on two basic object manipulation tasks.
Residual Learning from Demonstration
Aug 18, 2020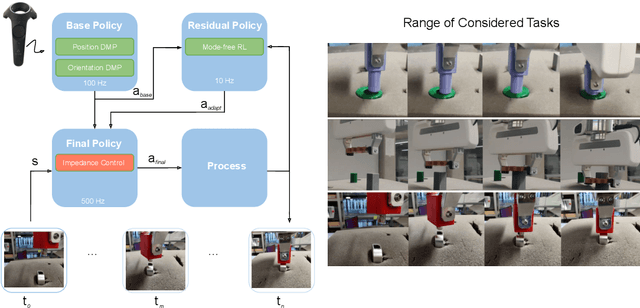
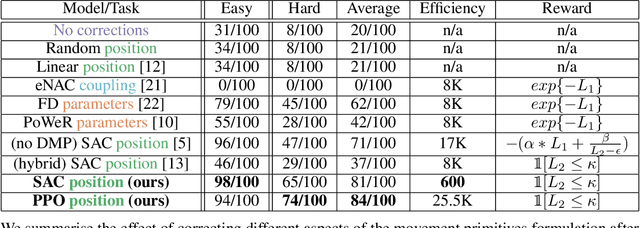
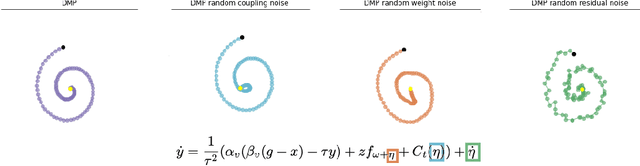
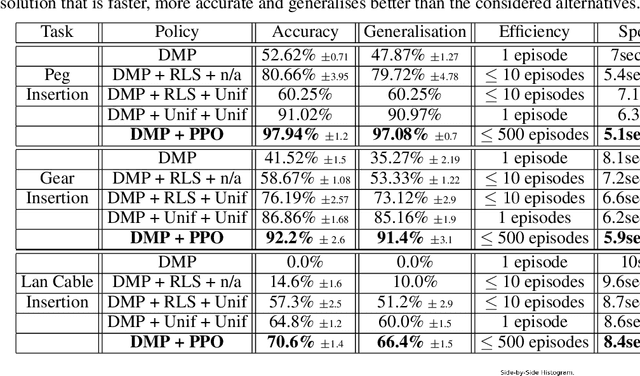
Contacts and friction are inherent to nearly all robotic manipulation tasks. Through the motor skill of insertion, we study how robots can learn to cope when these attributes play a salient role. In this work we propose residual learning from demonstration (rLfD), a framework that combines dynamic movement primitives (DMP) that rely on behavioural cloning with a reinforcement learning (RL) based residual correction policy. The proposed solution is applied directly in task space and operates on the full pose of the robot. We show that rLfD outperforms alternatives and improves the generalisation abilities of DMPs. We evaluate this approach by training an agent to successfully perform both simulated and real world insertions of pegs, gears and plugs into respective sockets.