 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-is-Sim: Bridging the Sim-to-Real Gap with a Dynamic Digital Twin for Real-World Robot Policy Evaluation
Apr 04, 2025Recent advancements in behavior cloning have enabled robots to perform complex manipulation tasks. However, accurately assessing training performance remains challenging, particularly for real-world applications, as behavior cloning losses often correlate poorly with actual task success. Consequently, researchers resort to success rate metrics derived from costly and time-consuming real-world evaluations, making the identification of optimal policies and detection of overfitting or underfitting impractical. To address these issues, we propose real-is-sim, a novel behavior cloning framework that incorporates a dynamic digital twin (based on Embodied Gaussians) throughout the entire policy development pipeline: data collection, training, and deployment. By continuously aligning the simulated world with the physical world, demonstrations can be collected in the real world with states extracted from the simulator. The simulator enables flexible state representations by rendering image inputs from any viewpoint or extracting low-level state information from objects embodied within the scene. During training, policies can be directly evaluated within the simulator in an offline and highly parallelizable manner. Finally, during deployment, policies are run within the simulator where the real robot directly tracks the simulated robot's joints, effectively decoupling policy execution from real hardware and mitigating traditional domain-transfer challenges. We validate real-is-sim on the PushT manipulation task, demonstrating strong correlation between success rates obtained in the simulator and real-world evaluations. Videos of our system can be found at https://realissim.rai-inst.com.
Affordance-Centric Policy Learning: Sample Efficient and Generalisable Robot Policy Learning using Affordance-Centric Task Frames
Oct 15, 2024



Affordances are central to robotic manipulation, where most tasks can be simplified to interactions with task-specific regions on objects. By focusing on these key regions, we can abstract away task-irrelevant information, simplifying the learning process, and enhancing generalisation. In this paper, we propose an affordance-centric policy-learning approach that centres and appropriately \textit{orients} a \textit{task frame} on these affordance regions allowing us to achieve both \textbf{intra-category invariance} -- where policies can generalise across different instances within the same object category -- and \textbf{spatial invariance} -- which enables consistent performance regardless of object placement in the environment. We propose a method to leverage existing generalist large vision models to extract and track these affordance frames, and demonstrate that our approach can learn manipulation tasks using behaviour cloning from as little as 10 demonstrations, with equivalent generalisation to an image-based policy trained on 305 demonstrations. We provide video demonstrations on our project site: https://affordance-policy.github.io.
Physically Embodied Gaussian Splatting: A Realtime Correctable World Model for Robotics
Jun 16, 2024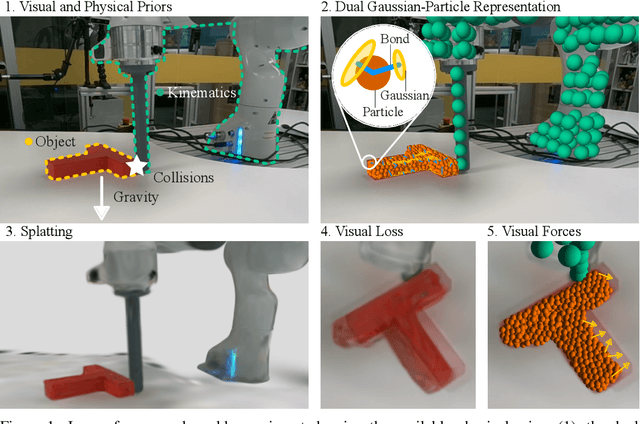
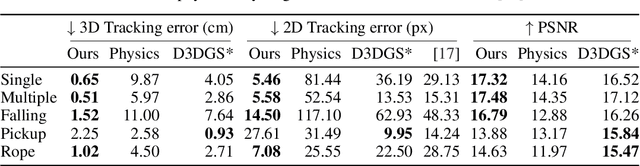


For robots to robustly understand and interact with the physical world, it is highly beneficial to have a comprehensive representation - modelling geometry, physics, and visual observations - that informs perception, planning, and control algorithms. We propose a novel dual Gaussian-Particle representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates visual forces that correct the particle positions while respecting known physical constraints. By integrating predictive physical modelling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality. Our system runs in realtime at 30Hz using only 3 cameras. We validate our approach on 2D and 3D tracking tasks as well as photometric reconstruction quality. Videos are found at https://embodied-gaussians.github.io/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Task Planning
Jul 12, 2023



Large language models (LLMs) have demonstrated impressive results in developing generalist planning agents for diverse tasks. However, grounding these plans in expansive, multi-floor, and multi-room environments presents a significant challenge for robotics. We introduce SayPlan, a scalable approach to LLM-based, large-scale task planning for robotics using 3D scene graph (3DSG) representations. To ensure the scalability of our approach, we: (1) exploit the hierarchical nature of 3DSGs to allow LLMs to conduct a semantic search for task-relevant subgraphs from a smaller, collapsed representation of the full graph; (2) reduce the planning horizon for the LLM by integrating a classical path planner and (3) introduce an iterative replanning pipeline that refines the initial plan using feedback from a scene graph simulator, correcting infeasible actions and avoiding planning failures. We evaluate our approach on two large-scale environments spanning up to 3 floors, 36 rooms and 140 objects, and show that our approach is capable of grounding large-scale, long-horizon task plans from abstract, and natural language instruction for a mobile manipulator robot to execute.
Learning Fabric Manipulation in the Real World with Human Videos
Nov 12, 2022



Fabric manipulation is a long-standing challenge in robotics due to the enormous state space and complex dynamics. Learning approaches stand out as promising for this domain as they allow us to learn behaviours directly from data. Most prior methods however rely heavily on simulation, which is still limited by the large sim-to-real gap of deformable objects or rely on large datasets. A promising alternative is to learn fabric manipulation directly from watching humans perform the task. In this work, we explore how demonstrations for fabric manipulation tasks can be collected directly by humans, providing an extremely natural and fast data collection pipeline. Then, using only a handful of such demonstrations, we show how a pick-and-place policy can be learned and deployed on a real robot, without any robot data collection at all. We demonstrate our approach on a fabric folding task, showing that our policy can reliably reach folded states from crumpled initial configurations. Videos are available at: https://sites.google.com/view/foldingbyhand
ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic Scenes
Nov 11, 2022



Neural Radiance Fields (NeRFs) learn implicit representations of - typically static - environments from images. Our paper extends NeRFs to handle dynamic scenes in an online fashion. We propose ParticleNeRF that adapts to changes in the geometry of the environment as they occur, learning a new up-to-date representation every 350 ms. ParticleNeRF can represent the current state of dynamic environments with much higher fidelity as other NeRF frameworks. To achieve this, we introduce a new particle-based parametric encoding, which allows the intermediate NeRF features - now coupled to particles in space - to move with the dynamic geometry. This is possible by backpropagating the photometric reconstruction loss into the position of the particles. The position gradients are interpreted as particle velocities and integrated into positions using a position-based dynamics (PBS) physics system. Introducing PBS into the NeRF formulation allows us to add collision constraints to the particle motion and creates future opportunities to add other movement priors into the system, such as rigid and deformable body
Density-aware NeRF Ensembles: Quantifying Predictive Uncertainty in Neural Radiance Fields
Sep 19, 2022

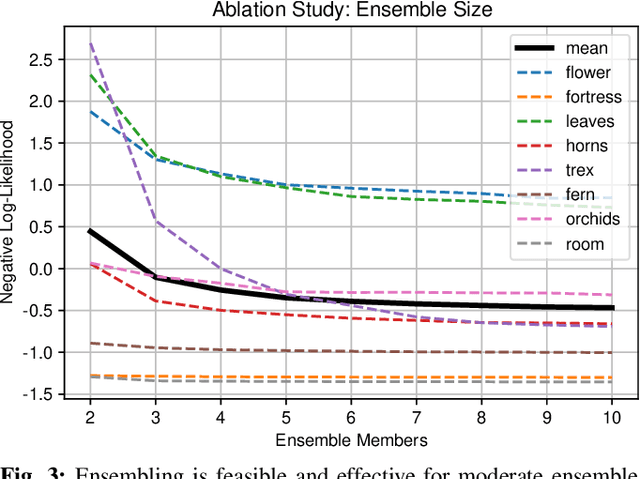
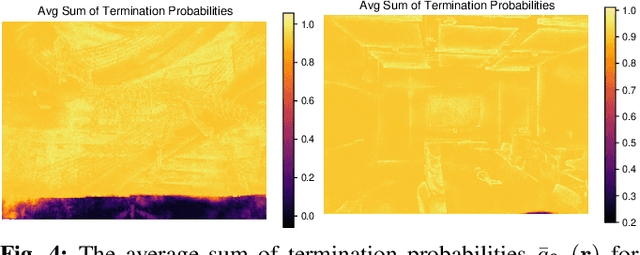
We show that ensembling effectively quantifies model uncertainty in Neural Radiance Fields (NeRFs) if a density-aware epistemic uncertainty term is considered. The naive ensembles investigated in prior work simply average rendered RGB images to quantify the model uncertainty caused by conflicting explanations of the observed scene. In contrast, we additionally consider the termination probabilities along individual rays to identify epistemic model uncertainty due to a lack of knowledge about the parts of a scene unobserved during training. We achieve new state-of-the-art performance across established uncertainty quantification benchmarks for NeRFs, outperforming methods that require complex changes to the NeRF architecture and training regime. We furthermore demonstrate that NeRF uncertainty can be utilised for next-best view selection and model refinement.
Implicit Object Mapping With Noisy Data
Apr 22, 2022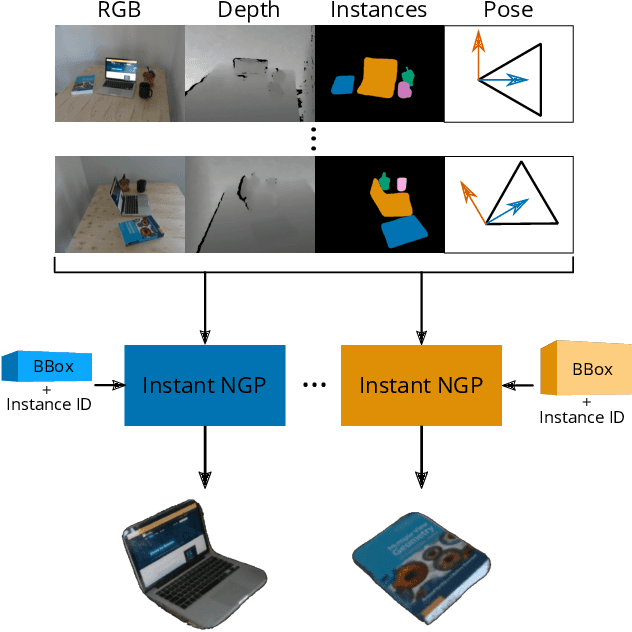
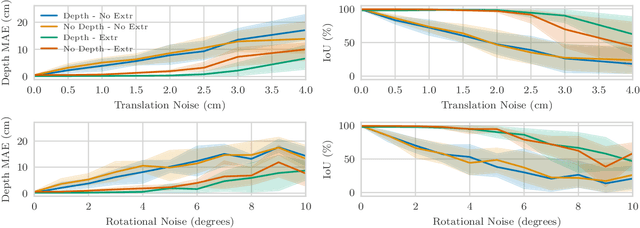


Modelling individual objects as Neural Radiance Fields (NeRFs) within a robotic context can benefit many downstream tasks such as scene understanding and object manipulation. However, real-world training data collected by a robot deviate from the ideal in several key aspects. (i) The trajectories are constrained and full visual coverage is not guaranteed - especially when obstructions are present. (ii) The poses associated with the images are noisy. (iii) The objects are not easily isolated from the background. This paper addresses the above three points and uses the outputs of an object-based SLAM system to bound objects in the scene with coarse primitives and - in concert with instance masks - identify obstructions in the training images. Objects are therefore automatically bounded, and non-relevant geometry is excluded from the NeRF representation. The method's performance is benchmarked under ideal conditions and tested against errors in the poses and instance masks. Our results show that object-based NeRFs are robust to pose variations but sensitive to the quality of the instance masks.