 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-based Safe Trajectory Planning for Autonomous Ground Vehicle in Multi-Floor Scenarios
Jun 23, 2026The development of trajectory planning strategies for autonomous ground vehicles (AGVs) represents a prevailing research interest within the domain of intelligent transportation systems. This paper introduces a trajectory planning framework tailored for multi-floor scenarios. The framework consists of two main modules: the task planning module and the trajectory planning module. The task planning module involves a strategic selection phase, where a task planning strategy based on generalized voronoi diagrams (GVD) and multi-objective algorithms is proposed to select the floor exits for each floor. The trajectory planning module utilizes optimization-based methods to generate high-quality trajectories, and a warm-started hierarchical planning framework is designed to ensure rapid convergence. Additionally, for handling complex obstacle constraints, a correlation constraint calculation method is designed for reducing obstacle constraints in trajectory planning. Finally, the feasibility and effectiveness of the proposed framework are verified through simulations.
\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
SAPO: Self-Adaptive Process Optimization Makes Small Reasoners Stronger
Jan 28, 2026Existing self-evolution methods overlook the influence of fine-grained reasoning steps, which leads to the reasoner-verifier gap. The computational inefficiency of Monte Carlo (MC) process supervision further exacerbates the difficulty in mitigating the gap. Motivated by the Error-Related Negativity (ERN), which the reasoner can localize error following incorrect decisions, guiding rapid adjustments, we propose a Self-Adaptive Process Optimization (SAPO) method for self-improvement in Small Language Models (SLMs). SAPO adaptively and efficiently introduces process supervision signals by actively minimizing the reasoner-verifier gap rather than relying on inefficient MC estimations. Extensive experiments demonstrate that the proposed method outperforms most existing self-evolution methods on two challenging task types: mathematics and code. Additionally, to further investigate SAPO's impact on verifier performance, this work introduces two new benchmarks for process reward models in both mathematical and coding tasks.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
LAVQA: A Latency-Aware Visual Question Answering Framework for Shared Autonomy in Self-Driving Vehicles
Nov 14, 2025When uncertainty is high, self-driving vehicles may halt for safety and benefit from the access to remote human operators who can provide high-level guidance. This paradigm, known as {shared autonomy}, enables autonomous vehicle and remote human operators to jointly formulate appropriate responses. To address critical decision timing with variable latency due to wireless network delays and human response time, we present LAVQA, a latency-aware shared autonomy framework that integrates Visual Question Answering (VQA) and spatiotemporal risk visualization. LAVQA augments visual queries with Latency-Induced COllision Map (LICOM), a dynamically evolving map that represents both temporal latency and spatial uncertainty. It enables remote operator to observe as the vehicle safety regions vary over time in the presence of dynamic obstacles and delayed responses. Closed-loop simulations in CARLA, the de-facto standard for autonomous vehicle simulator, suggest that that LAVQA can reduce collision rates by over 8x compared to latency-agnostic baselines.
xbench: Tracking Agents Productivity Scaling with Profession-Aligned Real-World Evaluations
Jun 16, 2025


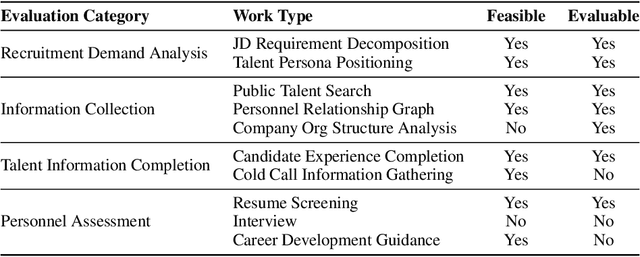
We introduce xbench, a dynamic, profession-aligned evaluation suite designed to bridge the gap between AI agent capabilities and real-world productivity. While existing benchmarks often focus on isolated technical skills, they may not accurately reflect the economic value agents deliver in professional settings. To address this, xbench targets commercially significant domains with evaluation tasks defined by industry professionals. Our framework creates metrics that strongly correlate with productivity value, enables prediction of Technology-Market Fit (TMF), and facilitates tracking of product capabilities over time. As our initial implementations, we present two benchmarks: Recruitment and Marketing. For Recruitment, we collect 50 tasks from real-world headhunting business scenarios to evaluate agents' abilities in company mapping, information retrieval, and talent sourcing. For Marketing, we assess agents' ability to match influencers with advertiser needs, evaluating their performance across 50 advertiser requirements using a curated pool of 836 candidate influencers. We present initial evaluation results for leading contemporary agents, establishing a baseline for these professional domains. Our continuously updated evalsets and evaluations are available at https://xbench.org.
Trajectory Optimization for UAV-Based Medical Delivery with Temporal Logic Constraints and Convex Feasible Set Collision Avoidance
Jun 06, 2025This paper addresses the problem of trajectory optimization for unmanned aerial vehicles (UAVs) performing time-sensitive medical deliveries in urban environments. Specifically, we consider a single UAV with 3 degree-of-freedom dynamics tasked with delivering blood packages to multiple hospitals, each with a predefined time window and priority. Mission objectives are encoded using Signal Temporal Logic (STL), enabling the formal specification of spatial-temporal constraints. To ensure safety, city buildings are modeled as 3D convex obstacles, and obstacle avoidance is handled through a Convex Feasible Set (CFS) method. The entire planning problem-combining UAV dynamics, STL satisfaction, and collision avoidance-is formulated as a convex optimization problem that ensures tractability and can be solved efficiently using standard convex programming techniques. Simulation results demonstrate that the proposed method generates dynamically feasible, collision-free trajectories that satisfy temporal mission goals, providing a scalable and reliable approach for autonomous UAV-based medical logistics.
UAV-UGV Cooperative Trajectory Optimization and Task Allocation for Medical Rescue Tasks in Post-Disaster Environments
Jun 06, 2025



In post-disaster scenarios, rapid and efficient delivery of medical resources is critical and challenging due to severe damage to infrastructure. To provide an optimized solution, we propose a cooperative trajectory optimization and task allocation framework leveraging unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs). This study integrates a Genetic Algorithm (GA) for efficient task allocation among multiple UAVs and UGVs, and employs an informed-RRT* (Rapidly-exploring Random Tree Star) algorithm for collision-free trajectory generation. Further optimization of task sequencing and path efficiency is conducted using Covariance Matrix Adaptation Evolution Strategy (CMA-ES). Simulation experiments conducted in a realistic post-disaster environment demonstrate that our proposed approach significantly improves the overall efficiency of medical rescue operations compared to traditional strategies, showing substantial reductions in total mission completion time and traveled distance. Additionally, the cooperative utilization of UAVs and UGVs effectively balances their complementary advantages, highlighting the system' s scalability and practicality for real-world deployment.