 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deployment Case Study in Robotic Apparel Automation: Digital Twin Integration, Interoperability, and Workforce Enablement
Jun 15, 2026Despite steady advances in flexible automation in sectors such as electronics and automotive manufacturing, apparel automation remains challenging because fabrics are deformable and difficult to manipulate with robots. This paper presents a deployment-oriented case study of a robotic sewing system for denim manufacturing, emphasizing the system-level integration required for practical adoption. At the engineering level, a digital thread module parses DXF production drawings into process parameters and executable robot trajectories, reducing manual programming effort and enabling rapid re-targeting across sewing operations. In parallel, a digital twin of the workcell is used during pre-deployment to validate reach and clearance, refine layout and sequencing, evaluate operator access, and assess cycle-time compatibility with upstream and downstream tasks, thereby reducing commissioning risk. At deployment, the system integrates a collaborative robot with conventional sewing equipment, welding, suction fixtures, and machine-level controllers through an interoperability layer. Runtime monitoring and verification, including seam monitoring, collision checking, and trajectory-level validation, improve robustness under environmental variability, while operator-facing training and guidance tools support setup, troubleshooting, and technology adoption. Two staged factory deployments on denim shorts, covering 2D pocket operations and 3D garment-shaping seams, show that digital-twin-based validation, digital-thread-driven task generation, interoperability, runtime verification, and operator training are important for scaling robotic apparel automation.
Closing the Loop in Teleoperation: Episode-Level Data Quality Assessment and Feedback for High-Quality Demonstration Collection
May 25, 2026Industrial automation is at a pivotal moment, as Physical AI is driving a transition from rigid, hand-engineered automation systems toward more flexible and adaptive systems. This shift has created a growing demand for large-scale, real-world robot demonstration data, making teleoperation an increasingly important mechanism for data collection. However, high-quality teleoperated demonstrations remain difficult to obtain in practice, as novice operators often produce episodes that are task-successful but suboptimal for downstream use due to inefficient motion, repeated corrections, or operation near robot joint limits. We present a Data Quality Assessment and Feedback (DQAF) framework that closes the loop in teleoperation by providing immediate post-episode feedback grounded in semantic task progress and robot telemetry. The framework extracts quality relevant signals such as sub-task progress, motion smoothness, stalls, kinematic limits and converts them into structured quality assessments and actionable natural-language feedback. Unlike binary success or failure feedback, the proposed system explains why an episode is suboptimal and highlights specific behaviors to correct in the next trial. We evaluate the framework through a diagnostic validation study and a pilot user study. In the validation study, the system is compared with a human reviewer during dataset curation, producing rejection reasons and actionable feedback for improvement. In the pilot study with three novice operators across two manipulation tasks, the operator who received the systems immediate, automated post-episode feedback improved faster than those who did not, producing higher-quality demonstrations sooner.
A Factory-Floor Deployment Case Study of VLA Pipelines for Industrial Packaging Task: Workflow, Failures, and Lessons
May 25, 2026Vision-Language-Action (VLA) policies have shown promising manipulation capabilities, yet their practical impact is often limited by the reliability demands of real-world deployment. We present a deployment study of an industrial packaging task at Siemens Factory (GWE, Erlangen, Germany), where a robot must pick a transparent accessory bag from a cluttered pile, insert it into the remaining cavity of a cardboard package, and ensure that the bag and its contents remain below the closing plane. Our goal is to understand the practical effort required to adapt a pretrained Pi0.5 policy to a single factory-floor task through iterative fine-tuning and deployment-driven refinement. The pipeline consists of repeated loops of data collection, curation, fine-tuning, evaluation, and targeted recovery data collection. We have accumulated 2535 episodes (10 hours) from the on-site factory settings. In this paper, we contribute an empirical account of a factory-floor VLA deployment, highlighting recurring failure modes and lessons that inform how to improve the deployment workflow.
GrowSplat: Constructing Temporal Digital Twins of Plants with Gaussian Splats
May 16, 2025



Accurate temporal reconstructions of plant growth are essential for plant phenotyping and breeding, yet remain challenging due to complex geometries, occlusions, and non-rigid deformations of plants. We present a novel framework for building temporal digital twins of plants by combining 3D Gaussian Splatting with a robust sample alignment pipeline. Our method begins by reconstructing Gaussian Splats from multi-view camera data, then leverages a two-stage registration approach: coarse alignment through feature-based matching and Fast Global Registration, followed by fine alignment with Iterative Closest Point. This pipeline yields a consistent 4D model of plant development in discrete time steps. We evaluate the approach on data from the Netherlands Plant Eco-phenotyping Center, demonstrating detailed temporal reconstructions of Sequoia and Quinoa species. Videos and Images can be seen at https://berkeleyautomation.github.io/GrowSplat/
Verifiable Learned Behaviors via Motion Primitive Composition: Applications to Scooping of Granular Media
Sep 26, 2023A robotic behavior model that can reliably generate behaviors from natural language inputs in real time would substantially expedite the adoption of industrial robots due to enhanced system flexibility. To facilitate these efforts, we construct a framework in which learned behaviors, created by a natural language abstractor, are verifiable by construction. Leveraging recent advancements in motion primitives and probabilistic verification, we construct a natural-language behavior abstractor that generates behaviors by synthesizing a directed graph over the provided motion primitives. If these component motion primitives are constructed according to the criteria we specify, the resulting behaviors are probabilistically verifiable. We demonstrate this verifiable behavior generation capacity in both simulation on an exploration task and on hardware with a robot scooping granular media.
Can Machines Garden? Systematically Comparing the AlphaGarden vs. Professional Horticulturalists
Jun 29, 2023



The AlphaGarden is an automated testbed for indoor polyculture farming which combines a first-order plant simulator, a gantry robot, a seed planting algorithm, plant phenotyping and tracking algorithms, irrigation sensors and algorithms, and custom pruning tools and algorithms. In this paper, we systematically compare the performance of the AlphaGarden to professional horticulturalists on the staff of the UC Berkeley Oxford Tract Greenhouse. The humans and the machine tend side-by-side polyculture gardens with the same seed arrangement. We compare performance in terms of canopy coverage, plant diversity, and water consumption. Results from two 60-day cycles suggest that the automated AlphaGarden performs comparably to professional horticulturalists in terms of coverage and diversity, and reduces water consumption by as much as 44%. Code, videos, and datasets are available at https://sites.google.com/berkeley.edu/systematiccomparison.
IIFL: Implicit Interactive Fleet Learning from Heterogeneous Human Supervisors
Jun 27, 2023



Imitation learning has been applied to a range of robotic tasks, but can struggle when (1) robots encounter edge cases that are not represented in the training data (distribution shift) or (2) the human demonstrations are heterogeneous: taking different paths around an obstacle, for instance (multimodality). Interactive fleet learning (IFL) mitigates distribution shift by allowing robots to access remote human teleoperators during task execution and learn from them over time, but is not equipped to handle multimodality. Recent work proposes Implicit Behavior Cloning (IBC), which is able to represent multimodal demonstrations using energy-based models (EBMs). In this work, we propose addressing both multimodality and distribution shift with Implicit Interactive Fleet Learning (IIFL), the first extension of implicit policies to interactive imitation learning (including the single-robot, single-human setting). IIFL quantifies uncertainty using a novel application of Jeffreys divergence to EBMs. While IIFL is more computationally expensive than explicit methods, results suggest that IIFL achieves 4.5x higher return on human effort in simulation experiments and an 80% higher success rate in a physical block pushing task over (Explicit) IFL, IBC, and other baselines when human supervision is heterogeneous.
Learning on the Job: Self-Rewarding Offline-to-Online Finetuning for Industrial Insertion of Novel Connectors from Vision
Oct 27, 2022Learning-based methods in robotics hold the promise of generalization, but what can be done if a learned policy does not generalize to a new situation? In principle, if an agent can at least evaluate its own success (i.e., with a reward classifier that generalizes well even when the policy does not), it could actively practice the task and finetune the policy in this situation. We study this problem in the setting of industrial insertion tasks, such as inserting connectors in sockets and setting screws. Existing algorithms rely on precise localization of the connector or socket and carefully managed physical setups, such as assembly lines, to succeed at the task. But in unstructured environments such as homes or even some industrial settings, robots cannot rely on precise localization and may be tasked with previously unseen connectors. Offline reinforcement learning on a variety of connector insertion tasks is a potential solution, but what if the robot is tasked with inserting previously unseen connector? In such a scenario, we will still need methods that can robustly solve such tasks with online practice. One of the main observations we make in this work is that, with a suitable representation learning and domain generalization approach, it can be significantly easier for the reward function to generalize to a new but structurally similar task (e.g., inserting a new type of connector) than for the policy. This means that a learned reward function can be used to facilitate the finetuning of the robot's policy in situations where the policy fails to generalize in zero shot, but the reward function generalizes successfully. We show that such an approach can be instantiated in the real world, pretrained on 50 different connectors, and successfully finetuned to new connectors via the learned reward function. Videos can be viewed at https://sites.google.com/view/learningonthejob
Learning to Efficiently Plan Robust Frictional Multi-Object Grasps
Oct 13, 2022

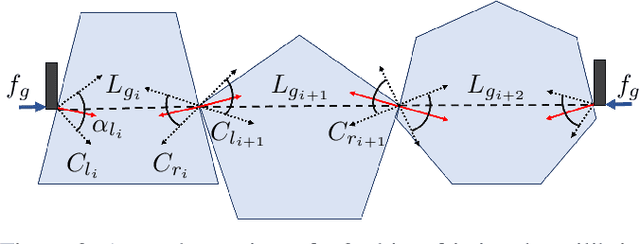

We consider a decluttering problem where multiple rigid convex polygonal objects rest in randomly placed positions and orientations on a planar surface and must be efficiently transported to a packing box using both single and multi-object grasps. Prior work considered frictionless multi-object grasping. In this paper, we introduce friction to increase picks per hour. We train a neural network using real examples to plan robust multi-object grasps. In physical experiments, we find an 11.7% increase in success rates, a 1.7x increase in picks per hour, and an 8.2x decrease in grasp planning time compared to prior work on multi-object grasping. Videos are available at https://youtu.be/pEZpHX5FZIs.
LEGS: Learning Efficient Grasp Sets for Exploratory Grasping
Nov 29, 2021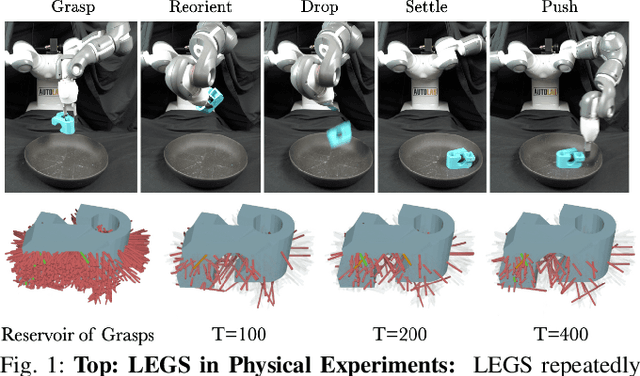
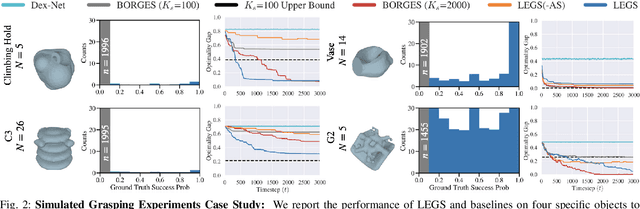
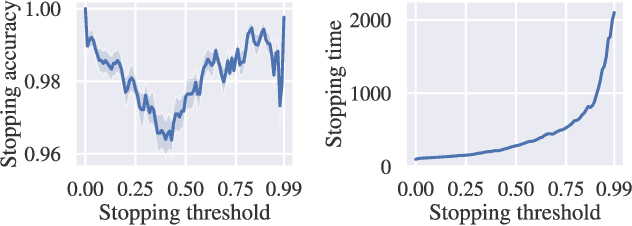
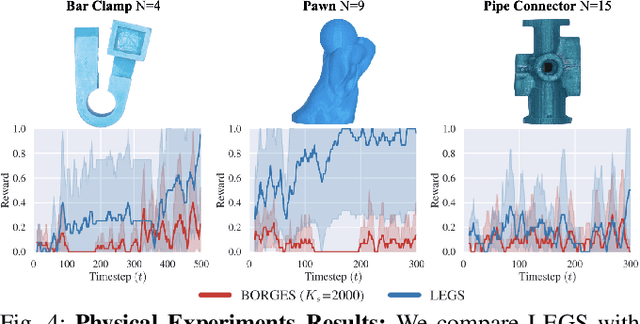
Previous work defined Exploratory Grasping, where a robot iteratively grasps and drops an unknown complex polyhedral object to discover a set of robust grasps for each recognizably distinct stable pose of the object. Recent work used a multi-armed bandit model with a small set of candidate grasps per pose; however, for objects with few successful grasps, this set may not include the most robust grasp. We present Learned Efficient Grasp Sets (LEGS), an algorithm that can efficiently explore thousands of possible grasps by constructing small active sets of promising grasps and uses learned confidence bounds to determine when, with high confidence, it can stop exploring the object. Experiments suggest that LEGS can identify a high-quality grasp more efficiently than prior algorithms which do not learn active sets. In simulation experiments, we measure the optimality gap between the success probability of the best grasp identified by LEGS and baselines and that of the true most robust grasp. After 3000 steps of exploration, LEGS outperforms baseline algorithms on 10 of the 14 Dex-Net Adversarial objects and 25 of the 39 EGAD! objects. We then develop a self-supervised grasping system, where the robot explores grasps with minimal human intervention. Physical experiments across 3 objects suggest that LEGS converges to high-performing grasps significantly faster than baselines. See \url{https://sites.google.com/view/legs-exp-grasping} for supplemental material and videos.