 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue from Observations: Towards Large-Scale Imitation Learning via Self-Improvement
Jul 09, 2025Imitation Learning from Observation (IfO) offers a powerful way to learn behaviors at large-scale: Unlike behavior cloning or offline reinforcement learning, IfO can leverage action-free demonstrations and thus circumvents the need for costly action-labeled demonstrations or reward functions. However, current IfO research focuses on idealized scenarios with mostly bimodal-quality data distributions, restricting the meaningfulness of the results. In contrast, this paper investigates more nuanced distributions and introduces a method to learn from such data, moving closer to a paradigm in which imitation learning can be performed iteratively via self-improvement. Our method adapts RL-based imitation learning to action-free demonstrations, using a value function to transfer information between expert and non-expert data. Through comprehensive evaluation, we delineate the relation between different data distributions and the applicability of algorithms and highlight the limitations of established methods. Our findings provide valuable insights for developing more robust and practical IfO techniques on a path to scalable behaviour learning.
ExoStart: Efficient learning for dexterous manipulation with sensorized exoskeleton demonstrations
Jun 13, 2025



Recent advancements in teleoperation systems have enabled high-quality data collection for robotic manipulators, showing impressive results in learning manipulation at scale. This progress suggests that extending these capabilities to robotic hands could unlock an even broader range of manipulation skills, especially if we could achieve the same level of dexterity that human hands exhibit. However, teleoperating robotic hands is far from a solved problem, as it presents a significant challenge due to the high degrees of freedom of robotic hands and the complex dynamics occurring during contact-rich settings. In this work, we present ExoStart, a general and scalable learning framework that leverages human dexterity to improve robotic hand control. In particular, we obtain high-quality data by collecting direct demonstrations without a robot in the loop using a sensorized low-cost wearable exoskeleton, capturing the rich behaviors that humans can demonstrate with their own hands. We also propose a simulation-based dynamics filter that generates dynamically feasible trajectories from the collected demonstrations and use the generated trajectories to bootstrap an auto-curriculum reinforcement learning method that relies only on simple sparse rewards. The ExoStart pipeline is generalizable and yields robust policies that transfer zero-shot to the real robot. Our results demonstrate that ExoStart can generate dexterous real-world hand skills, achieving a success rate above 50% on a wide range of complex tasks such as opening an AirPods case or inserting and turning a key in a lock. More details and videos can be found in https://sites.google.com/view/exostart.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Faithfulness of LLM Self-Explanations for Commonsense Tasks: Larger Is Better, and Instruction-Tuning Allows Trade-Offs but Not Pareto Dominance
Mar 17, 2025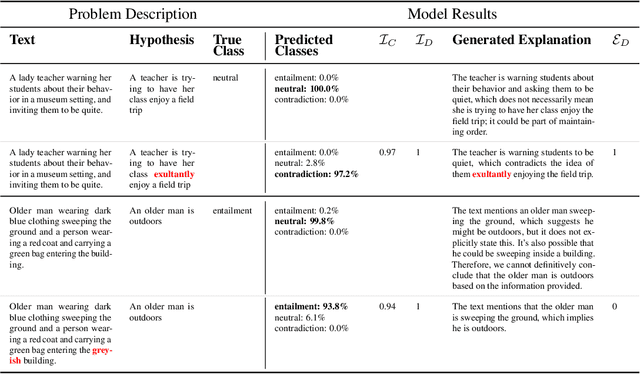
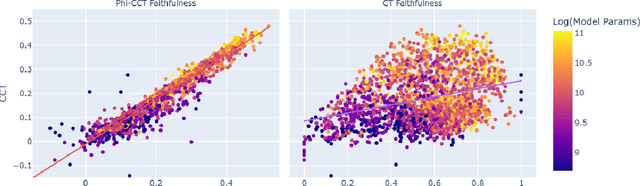
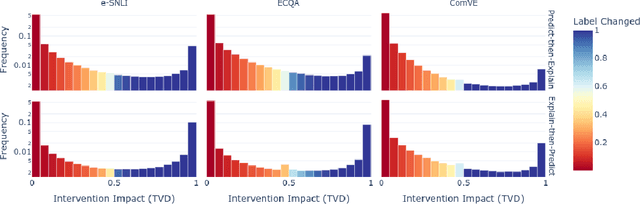
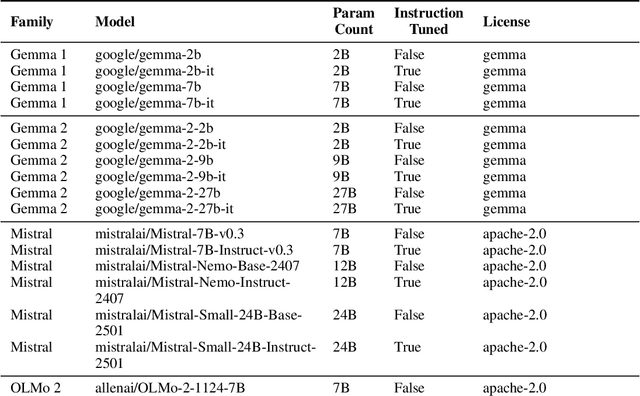
As large language models (LLMs) become increasingly capable, ensuring that their self-generated explanations are faithful to their internal decision-making process is critical for safety and oversight. In this work, we conduct a comprehensive counterfactual faithfulness analysis across 62 models from 8 families, encompassing both pretrained and instruction-tuned variants and significantly extending prior studies of counterfactual tests. We introduce phi-CCT, a simplified variant of the Correlational Counterfactual Test, which avoids the need for token probabilities while explaining most of the variance of the original test. Our findings reveal clear scaling trends: larger models are consistently more faithful on our metrics. However, when comparing instruction-tuned and human-imitated explanations, we find that observed differences in faithfulness can often be attributed to explanation verbosity, leading to shifts along the true-positive/false-positive Pareto frontier. While instruction-tuning and prompting can influence this trade-off, we find limited evidence that they fundamentally expand the frontier of explanatory faithfulness beyond what is achievable with pretrained models of comparable size. Our analysis highlights the nuanced relationship between instruction-tuning, verbosity, and the faithful representation of model decision processes.
Proc4Gem: Foundation models for physical agency through procedural generation
Mar 11, 2025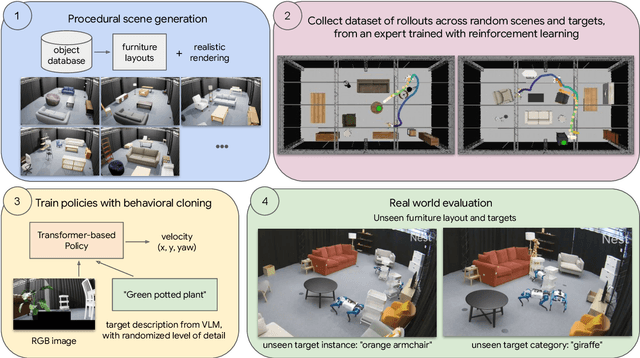


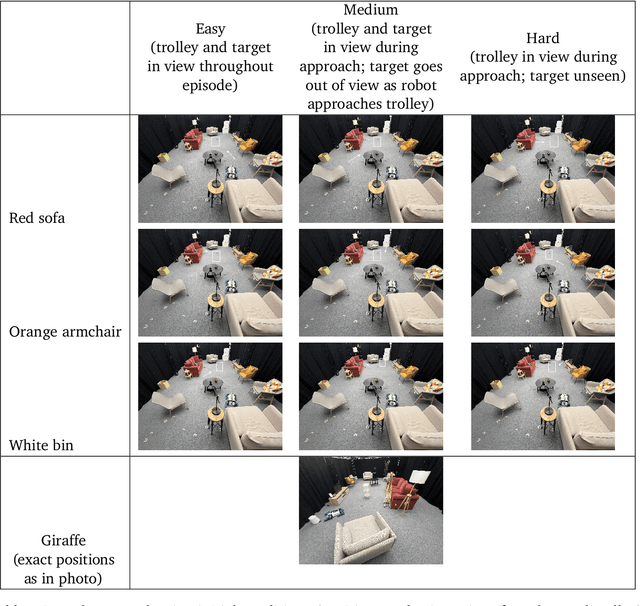
In robot learning, it is common to either ignore the environment semantics, focusing on tasks like whole-body control which only require reasoning about robot-environment contacts, or conversely to ignore contact dynamics, focusing on grounding high-level movement in vision and language. In this work, we show that advances in generative modeling, photorealistic rendering, and procedural generation allow us to tackle tasks requiring both. By generating contact-rich trajectories with accurate physics in semantically-diverse simulations, we can distill behaviors into large multimodal models that directly transfer to the real world: a system we call Proc4Gem. Specifically, we show that a foundation model, Gemini, fine-tuned on only simulation data, can be instructed in language to control a quadruped robot to push an object with its body to unseen targets in unseen real-world environments. Our real-world results demonstrate the promise of using simulation to imbue foundation models with physical agency. Videos can be found at our website: https://sites.google.com/view/proc4gem
Learning-Order Autoregressive Models with Application to Molecular Graph Generation
Mar 07, 2025



Autoregressive models (ARMs) have become the workhorse for sequence generation tasks, since many problems can be modeled as next-token prediction. While there appears to be a natural ordering for text (i.e., left-to-right), for many data types, such as graphs, the canonical ordering is less obvious. To address this problem, we introduce a variant of ARM that generates high-dimensional data using a probabilistic ordering that is sequentially inferred from data. This model incorporates a trainable probability distribution, referred to as an \emph{order-policy}, that dynamically decides the autoregressive order in a state-dependent manner. To train the model, we introduce a variational lower bound on the exact log-likelihood, which we optimize with stochastic gradient estimation. We demonstrate experimentally that our method can learn meaningful autoregressive orderings in image and graph generation. On the challenging domain of molecular graph generation, we achieve state-of-the-art results on the QM9 and ZINC250k benchmarks, evaluated using the Fr\'{e}chet ChemNet Distance (FCD).
Re-evaluating Open-ended Evaluation of Large Language Models
Feb 27, 2025

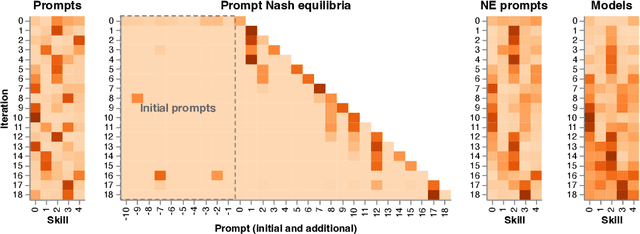

Evaluation has traditionally focused on ranking candidates for a specific skill. Modern generalist models, such as Large Language Models (LLMs), decidedly outpace this paradigm. Open-ended evaluation systems, where candidate models are compared on user-submitted prompts, have emerged as a popular solution. Despite their many advantages, we show that the current Elo-based rating systems can be susceptible to and even reinforce biases in data, intentional or accidental, due to their sensitivity to redundancies. To address this issue, we propose evaluation as a 3-player game, and introduce novel game-theoretic solution concepts to ensure robustness to redundancy. We show that our method leads to intuitive ratings and provide insights into the competitive landscape of LLM development.
Preference Optimization as Probabilistic Inference
Oct 05, 2024



Existing preference optimization methods are mainly designed for directly learning from human feedback with the assumption that paired examples (preferred vs. dis-preferred) are available. In contrast, we propose a method that can leverage unpaired preferred or dis-preferred examples, and works even when only one type of feedback (positive or negative) is available. This flexibility allows us to apply it in scenarios with varying forms of feedback and models, including training generative language models based on human feedback as well as training policies for sequential decision-making problems, where learned (value) functions are available. Our approach builds upon the probabilistic framework introduced in (Dayan and Hinton, 1997), which proposes to use expectation-maximization (EM) to directly optimize the probability of preferred outcomes (as opposed to classic expected reward maximization). To obtain a practical algorithm, we identify and address a key limitation in current EM-based methods: when applied to preference optimization, they solely maximize the likelihood of preferred examples, while neglecting dis-preferred samples. We show how one can extend EM algorithms to explicitly incorporate dis-preferred outcomes, leading to a novel, theoretically grounded, preference optimization algorithm that offers an intuitive and versatile way to learn from both positive and negative feedback.
DemoStart: Demonstration-led auto-curriculum applied to sim-to-real with multi-fingered robots
Sep 10, 2024



We present DemoStart, a novel auto-curriculum reinforcement learning method capable of learning complex manipulation behaviors on an arm equipped with a three-fingered robotic hand, from only a sparse reward and a handful of demonstrations in simulation. Learning from simulation drastically reduces the development cycle of behavior generation, and domain randomization techniques are leveraged to achieve successful zero-shot sim-to-real transfer. Transferred policies are learned directly from raw pixels from multiple cameras and robot proprioception. Our approach outperforms policies learned from demonstrations on the real robot and requires 100 times fewer demonstrations, collected in simulation. More details and videos in https://sites.google.com/view/demostart.
A Unifying Framework for Action-Conditional Self-Predictive Reinforcement Learning
Jun 04, 2024



Learning a good representation is a crucial challenge for Reinforcement Learning (RL) agents. Self-predictive learning provides means to jointly learn a latent representation and dynamics model by bootstrapping from future latent representations (BYOL). Recent work has developed theoretical insights into these algorithms by studying a continuous-time ODE model for self-predictive representation learning under the simplifying assumption that the algorithm depends on a fixed policy (BYOL-$\Pi$); this assumption is at odds with practical instantiations of such algorithms, which explicitly condition their predictions on future actions. In this work, we take a step towards bridging the gap between theory and practice by analyzing an action-conditional self-predictive objective (BYOL-AC) using the ODE framework, characterizing its convergence properties and highlighting important distinctions between the limiting solutions of the BYOL-$\Pi$ and BYOL-AC dynamics. We show how the two representations are related by a variance equation. This connection leads to a novel variance-like action-conditional objective (BYOL-VAR) and its corresponding ODE. We unify the study of all three objectives through two complementary lenses; a model-based perspective, where each objective is shown to be equivalent to a low-rank approximation of certain dynamics, and a model-free perspective, which establishes relationships between the objectives and their respective value, Q-value, and advantage function. Our empirical investigations, encompassing both linear function approximation and Deep RL environments, demonstrates that BYOL-AC is better overall in a variety of different settings.