 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rise and Potential of Large Language Model Based Agents: A Survey
Sep 19, 2023



For a long time, humanity has pursued artificial intelligence (AI) equivalent to or surpassing the human level, with AI agents considered a promising vehicle for this pursuit. AI agents are artificial entities that sense their environment, make decisions, and take actions. Many efforts have been made to develop intelligent agents, but they mainly focus on advancement in algorithms or training strategies to enhance specific capabilities or performance on particular tasks. Actually, what the community lacks is a general and powerful model to serve as a starting point for designing AI agents that can adapt to diverse scenarios. Due to the versatile capabilities they demonstrate, large language models (LLMs) are regarded as potential sparks for Artificial General Intelligence (AGI), offering hope for building general AI agents. Many researchers have leveraged LLMs as the foundation to build AI agents and have achieved significant progress. In this paper, we perform a comprehensive survey on LLM-based agents. We start by tracing the concept of agents from its philosophical origins to its development in AI, and explain why LLMs are suitable foundations for agents. Building upon this, we present a general framework for LLM-based agents, comprising three main components: brain, perception, and action, and the framework can be tailored for different applications. Subsequently, we explore the extensive applications of LLM-based agents in three aspects: single-agent scenarios, multi-agent scenarios, and human-agent cooperation. Following this, we delve into agent societies, exploring the behavior and personality of LLM-based agents, the social phenomena that emerge from an agent society, and the insights they offer for human society. Finally, we discuss several key topics and open problems within the field. A repository for the related papers at https://github.com/WooooDyy/LLM-Agent-Paper-List.
Augmenting conformers with structured state space models for online speech recognition
Sep 15, 2023



Online speech recognition, where the model only accesses context to the left, is an important and challenging use case for ASR systems. In this work, we investigate augmenting neural encoders for online ASR by incorporating structured state-space sequence models (S4), which are a family of models that provide a parameter-efficient way of accessing arbitrarily long left context. We perform systematic ablation studies to compare variants of S4 models and propose two novel approaches that combine them with convolutions. We find that the most effective design is to stack a small S4 using real-valued recurrent weights with a local convolution, allowing them to work complementarily. Our best model achieves WERs of 4.01%/8.53% on test sets from Librispeech, outperforming Conformers with extensively tuned convolution.
Towards Word-Level End-to-End Neural Speaker Diarization with Auxiliary Network
Sep 15, 2023



While standard speaker diarization attempts to answer the question "who spoken when", most of relevant applications in reality are more interested in determining "who spoken what". Whether it is the conventional modularized approach or the more recent end-to-end neural diarization (EEND), an additional automatic speech recognition (ASR) model and an orchestration algorithm are required to associate the speaker labels with recognized words. In this paper, we propose Word-level End-to-End Neural Diarization (WEEND) with auxiliary network, a multi-task learning algorithm that performs end-to-end ASR and speaker diarization in the same neural architecture. That is, while speech is being recognized, speaker labels are predicted simultaneously for each recognized word. Experimental results demonstrate that WEEND outperforms the turn-based diarization baseline system on all 2-speaker short-form scenarios and has the capability to generalize to audio lengths of 5 minutes. Although 3+speaker conversations are harder, we find that with enough in-domain training data, WEEND has the potential to deliver high quality diarized text.
Text Injection for Capitalization and Turn-Taking Prediction in Speech Models
Aug 14, 2023



Text injection for automatic speech recognition (ASR), wherein unpaired text-only data is used to supplement paired audio-text data, has shown promising improvements for word error rate. This study examines the use of text injection for auxiliary tasks, which are the non-ASR tasks often performed by an E2E model. In this work, we use joint end-to-end and internal language model training (JEIT) as our text injection algorithm to train an ASR model which performs two auxiliary tasks. The first is capitalization, which is a de-normalization task. The second is turn-taking prediction, which attempts to identify whether a user has completed their conversation turn in a digital assistant interaction. We show results demonstrating that our text injection method boosts capitalization performance for long-tail data, and improves turn-taking detection recall.
Practical Conformer: Optimizing size, speed and flops of Conformer for on-Device and cloud ASR
Mar 31, 2023



Conformer models maintain a large number of internal states, the vast majority of which are associated with self-attention layers. With limited memory bandwidth, reading these from memory at each inference step can slow down inference. In this paper, we design an optimized conformer that is small enough to meet on-device restrictions and has fast inference on TPUs. We explore various ideas to improve the execution speed, including replacing lower conformer blocks with convolution-only blocks, strategically downsizing the architecture, and utilizing an RNNAttention-Performer. Our optimized conformer can be readily incorporated into a cascaded-encoder setting, allowing a second-pass decoder to operate on its output and improve the accuracy whenever more resources are available. Altogether, we find that these optimizations can reduce latency by a factor of 6.8x, and come at a reasonable trade-off in quality. With the cascaded second-pass, we show that the recognition accuracy is completely recoverable. Thus, our proposed encoder can double as a strong standalone encoder in on device, and as the first part of a high-performance ASR pipeline.
JEIT: Joint End-to-End Model and Internal Language Model Training for Speech Recognition
Feb 16, 2023



We propose JEIT, a joint end-to-end (E2E) model and internal language model (ILM) training method to inject large-scale unpaired text into ILM during E2E training which improves rare-word speech recognition. With JEIT, the E2E model computes an E2E loss on audio-transcript pairs while its ILM estimates a cross-entropy loss on unpaired text. The E2E model is trained to minimize a weighted sum of E2E and ILM losses. During JEIT, ILM absorbs knowledge from unpaired text while the E2E training serves as regularization. Unlike ILM adaptation methods, JEIT does not require a separate adaptation step and avoids the need for Kullback-Leibler divergence regularization of ILM. We also show that modular hybrid autoregressive transducer (MHAT) performs better than HAT in the JEIT framework, and is much more robust than HAT during ILM adaptation. To push the limit of unpaired text injection, we further propose a combined JEIT and JOIST training (CJJT) that benefits from modality matching, encoder text injection and ILM training. Both JEIT and CJJT can foster a more effective LM fusion. With 100B unpaired sentences, JEIT/CJJT improves rare-word recognition accuracy by up to 16.4% over a model trained without unpaired text.
* 5 pages, 3 figures, in ICASSP 2023
JOIST: A Joint Speech and Text Streaming Model For ASR
Oct 13, 2022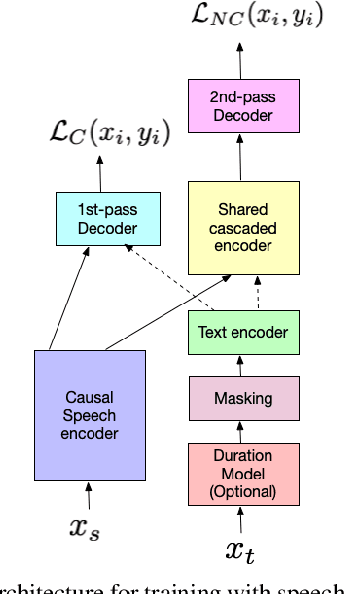
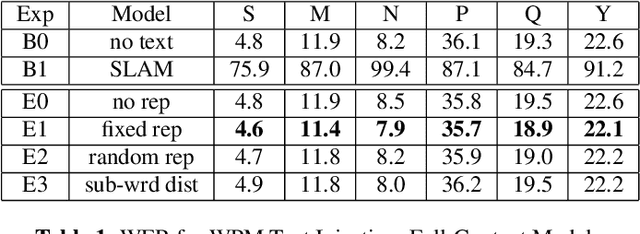
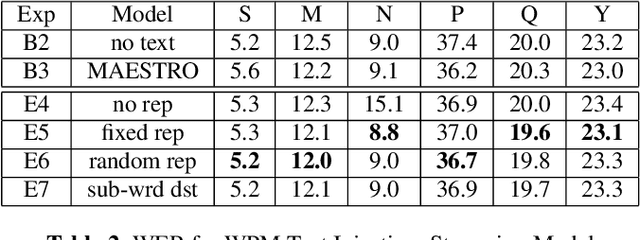
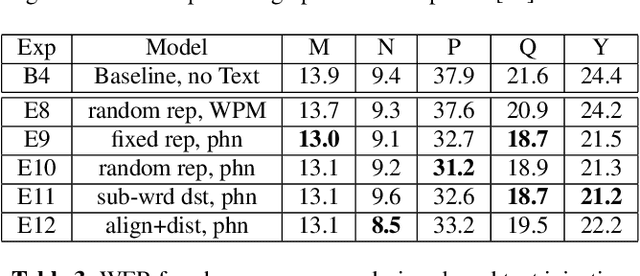
We present JOIST, an algorithm to train a streaming, cascaded, encoder end-to-end (E2E) model with both speech-text paired inputs, and text-only unpaired inputs. Unlike previous works, we explore joint training with both modalities, rather than pre-training and fine-tuning. In addition, we explore JOIST using a streaming E2E model with an order of magnitude more data, which are also novelties compared to previous works. Through a series of ablation studies, we explore different types of text modeling, including how to model the length of the text sequence and the appropriate text sub-word unit representation. We find that best text representation for JOIST improves WER across a variety of search and rare-word test sets by 4-14% relative, compared to a model not trained with text. In addition, we quantitatively show that JOIST maintains streaming capabilities, which is important for good user-level experience.
Improving Deliberation by Text-Only and Semi-Supervised Training
Jun 29, 2022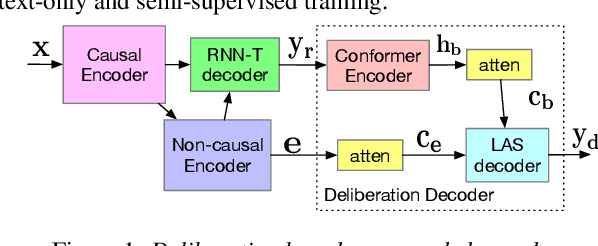
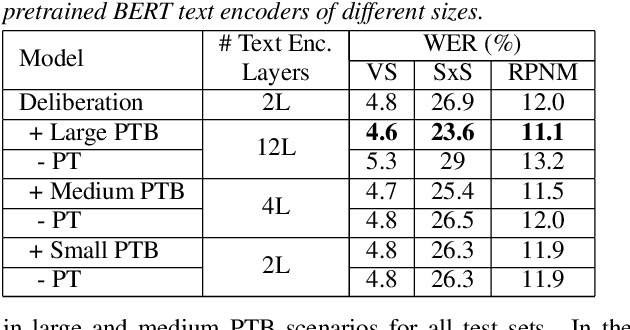
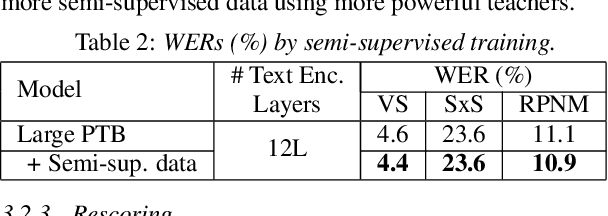
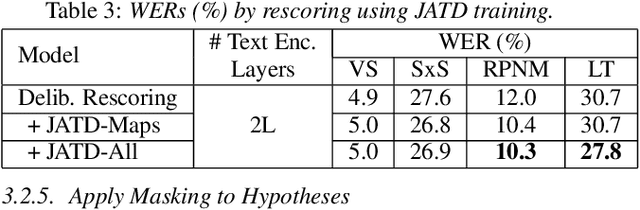
Text-only and semi-supervised training based on audio-only data has gained popularity recently due to the wide availability of unlabeled text and speech data. In this work, we propose incorporating text-only and semi-supervised training into an attention-based deliberation model. By incorporating text-only data in training a bidirectional encoder representation from transformer (BERT) for the deliberation text encoder, and large-scale text-to-speech and audio-only utterances using joint acoustic and text decoder (JATD) and semi-supervised training, we achieved 4%-12% WER reduction for various tasks compared to the baseline deliberation. Compared to a state-of-the-art language model (LM) rescoring method, the deliberation model reduces the Google Voice Search WER by 11% relative. We show that the deliberation model also achieves a positive human side-by-side evaluation compared to the state-of-the-art LM rescorer with reasonable endpointer latencies.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022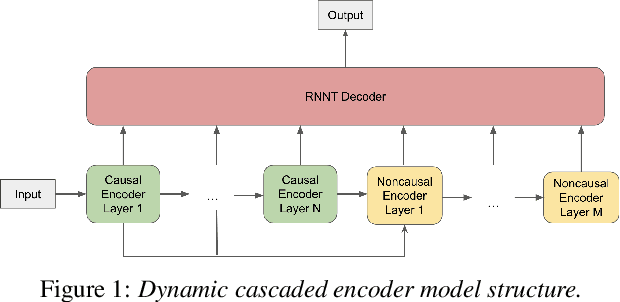
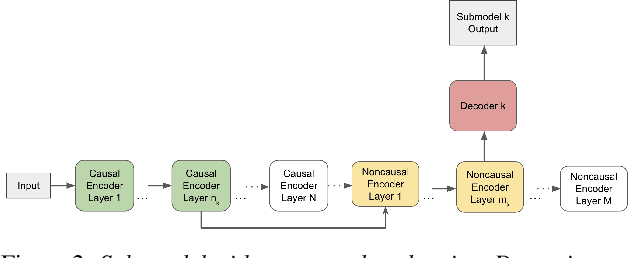
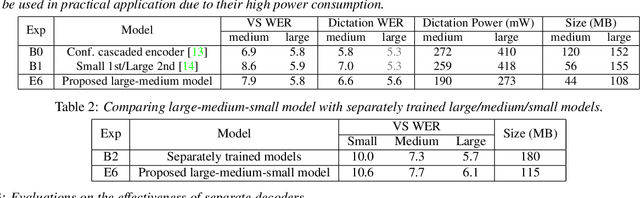
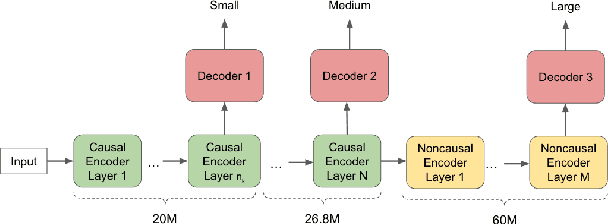
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.