 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Low Rank Conformer Weights for Tiny Always-On Ambient Speech Recognition Models
Mar 15, 2023Continued improvements in machine learning techniques offer exciting new opportunities through the use of larger models and larger training datasets. However, there is a growing need to offer these new capabilities on-board low-powered devices such as smartphones, wearables and other embedded environments where only low memory is available. Towards this, we consider methods to reduce the model size of Conformer-based speech recognition models which typically require models with greater than 100M parameters down to just $5$M parameters while minimizing impact on model quality. Such a model allows us to achieve always-on ambient speech recognition on edge devices with low-memory neural processors. We propose model weight reuse at different levels within our model architecture: (i) repeating full conformer block layers, (ii) sharing specific conformer modules across layers, (iii) sharing sub-components per conformer module, and (iv) sharing decomposed sub-component weights after low-rank decomposition. By sharing weights at different levels of our model, we can retain the full model in-memory while increasing the number of virtual transformations applied to the input. Through a series of ablation studies and evaluations, we find that with weight sharing and a low-rank architecture, we can achieve a WER of 2.84 and 2.94 for Librispeech dev-clean and test-clean respectively with a $5$M parameter model.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022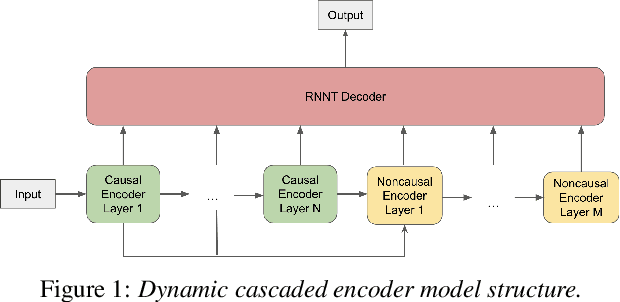
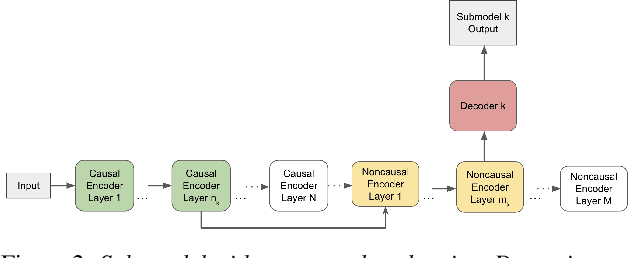
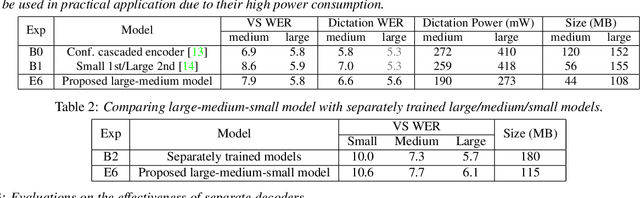
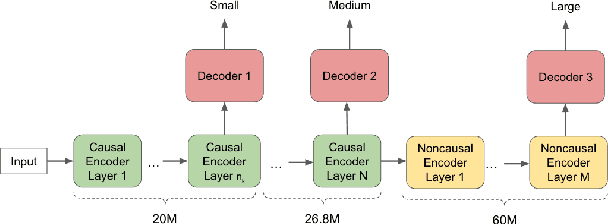
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022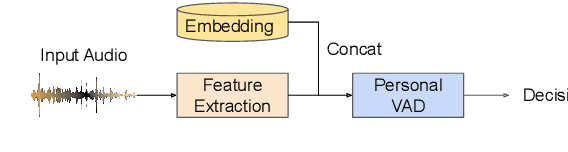
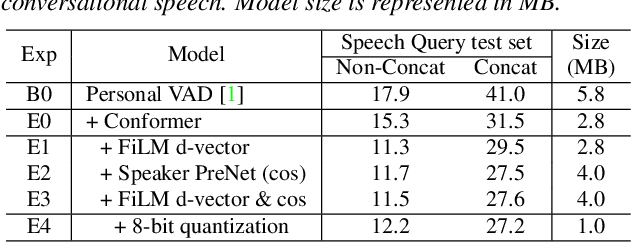
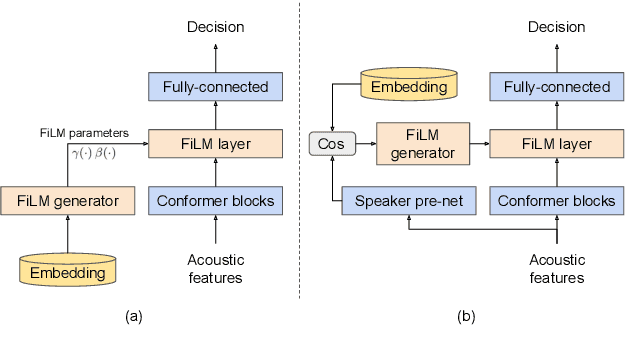
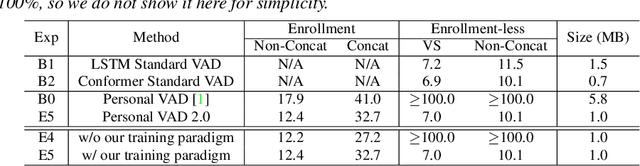
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
Closing the Gap between Single-User and Multi-User VoiceFilter-Lite
Feb 24, 2022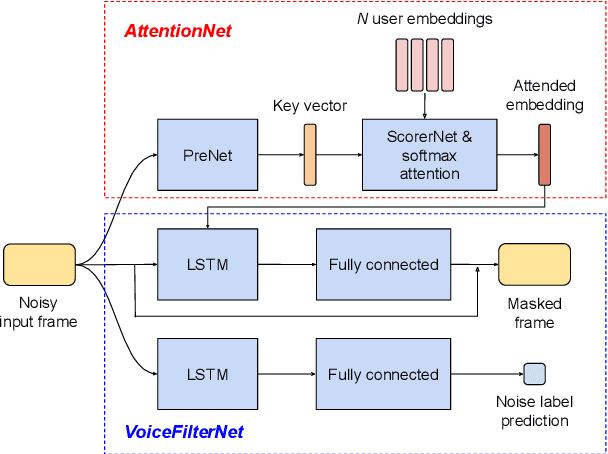
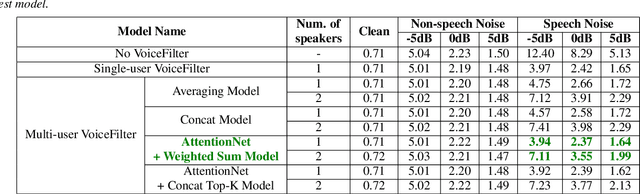
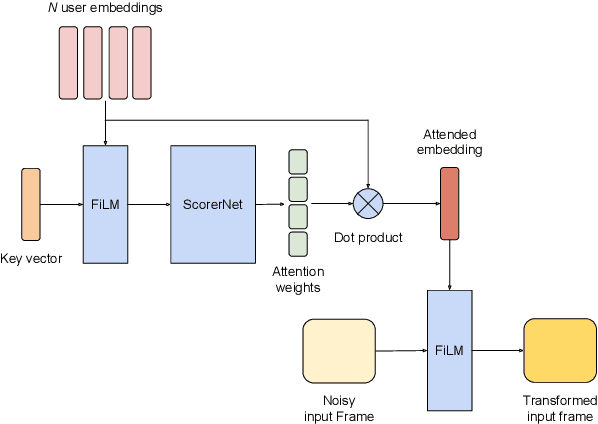
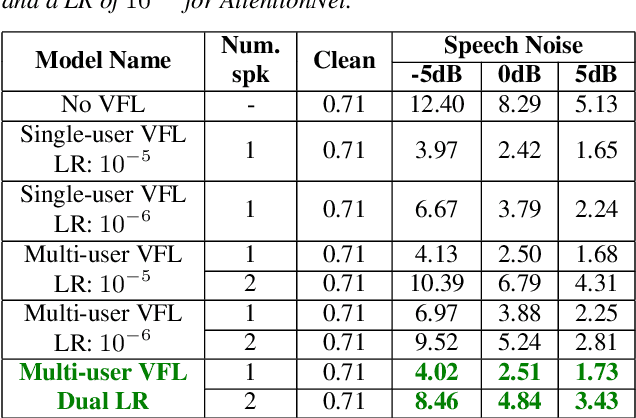
VoiceFilter-Lite is a speaker-conditioned voice separation model that plays a crucial role in improving speech recognition and speaker verification by suppressing overlapping speech from non-target speakers. However, one limitation of VoiceFilter-Lite, and other speaker-conditioned speech models in general, is that these models are usually limited to a single target speaker. This is undesirable as most smart home devices now support multiple enrolled users. In order to extend the benefits of personalization to multiple users, we previously developed an attention-based speaker selection mechanism and applied it to VoiceFilter-Lite. However, the original multi-user VoiceFilter-Lite model suffers from significant performance degradation compared with single-user models. In this paper, we devised a series of experiments to improve the multi-user VoiceFilter-Lite model. By incorporating a dual learning rate schedule and by using feature-wise linear modulation (FiLM) to condition the model with the attended speaker embedding, we successfully closed the performance gap between multi-user and single-user VoiceFilter-Lite models on single-speaker evaluations. At the same time, the new model can also be easily extended to support any number of users, and significantly outperforms our previously published model on multi-speaker evaluations.
Multi-user VoiceFilter-Lite via Attentive Speaker Embedding
Jul 02, 2021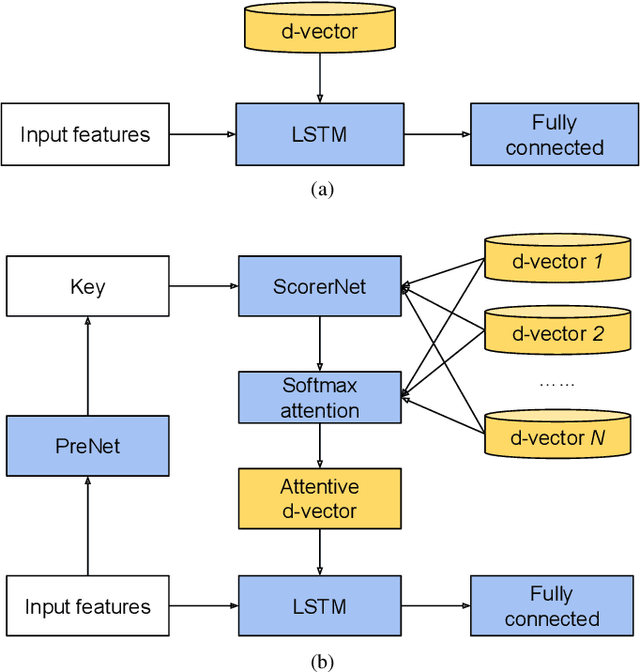
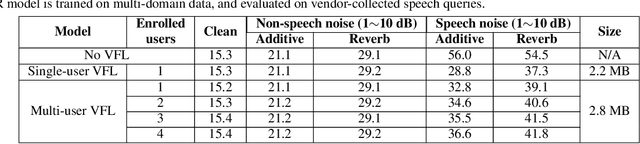
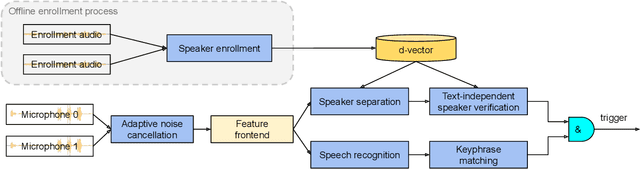
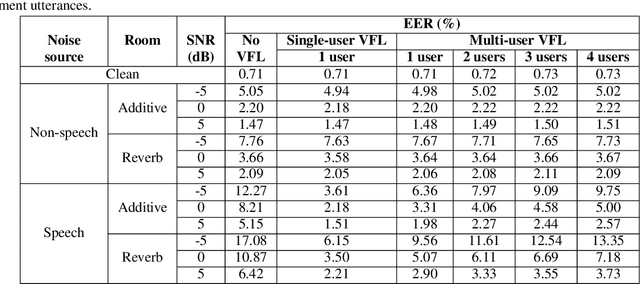
In this paper, we propose a solution to allow speaker conditioned speech models, such as VoiceFilter-Lite, to support an arbitrary number of enrolled users in a single pass. This is achieved by using an attention mechanism on multiple speaker embeddings to compute a single attentive embedding, which is then used as a side input to the model. We implemented multi-user VoiceFilter-Lite and evaluated it for three tasks: (1) a streaming automatic speech recognition (ASR) task; (2) a text-independent speaker verification task; and (3) a personalized keyphrase detection task, where ASR has to detect keyphrases from multiple enrolled users in a noisy environment. Our experiments show that, with up to four enrolled users, multi-user VoiceFilter-Lite is able to significantly reduce speech recognition and speaker verification errors when there is overlapping speech, without affecting performance under other acoustic conditions. This attentive speaker embedding approach can also be easily applied to other speaker-conditioned models such as personal VAD and personalized ASR.
Personalized Keyphrase Detection using Speaker and Environment Information
Apr 28, 2021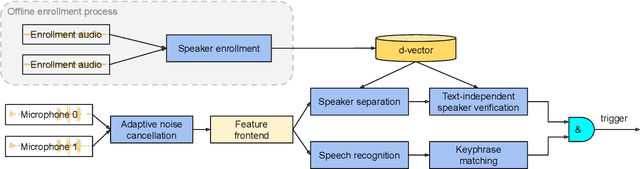
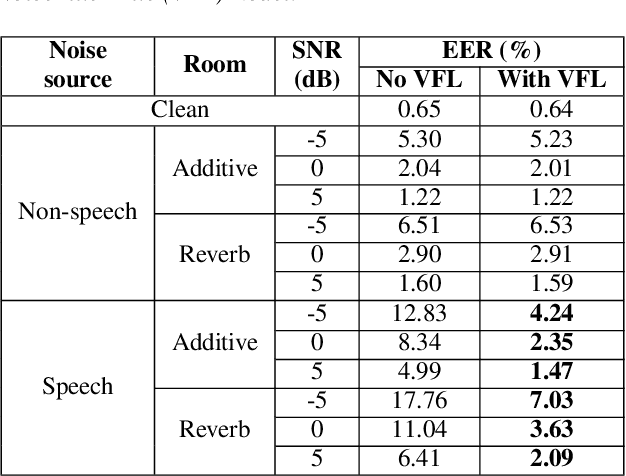
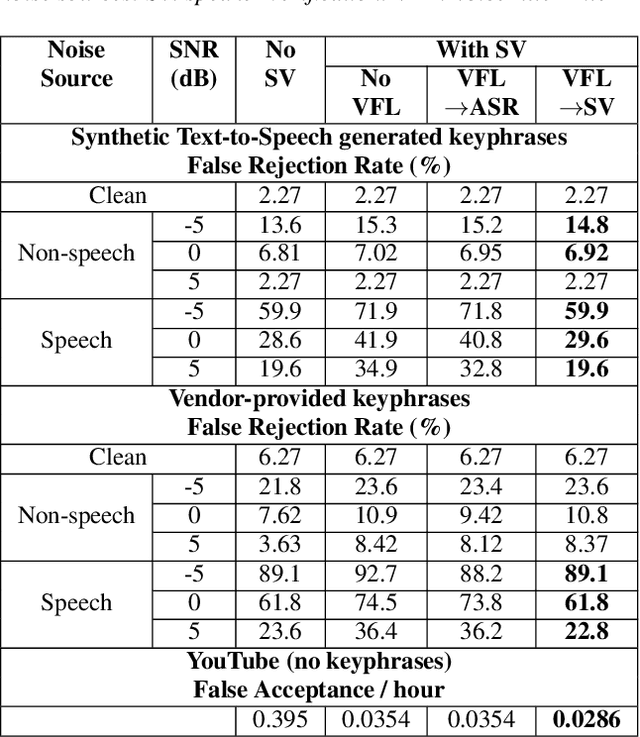
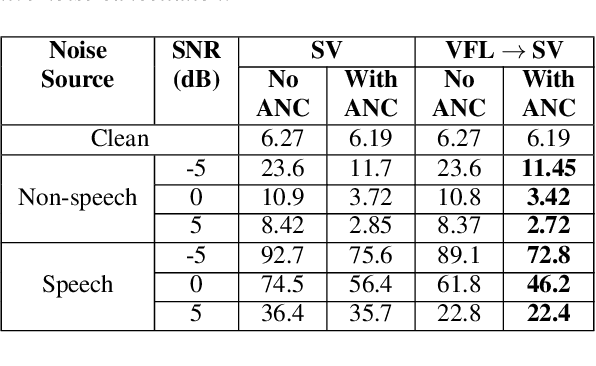
In this paper, we introduce a streaming keyphrase detection system that can be easily customized to accurately detect any phrase composed of words from a large vocabulary. The system is implemented with an end-to-end trained automatic speech recognition (ASR) model and a text-independent speaker verification model. To address the challenge of detecting these keyphrases under various noisy conditions, a speaker separation model is added to the feature frontend of the speaker verification model, and an adaptive noise cancellation (ANC) algorithm is included to exploit cross-microphone noise coherence. Our experiments show that the text-independent speaker verification model largely reduces the false triggering rate of the keyphrase detection, while the speaker separation model and adaptive noise cancellation largely reduce false rejections.
Multi-Task Learning for End-to-End ASR Word and Utterance Confidence with Deletion Prediction
Apr 26, 2021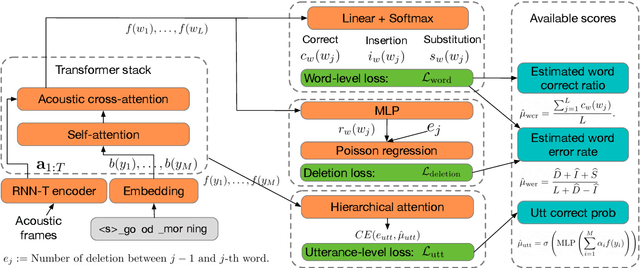
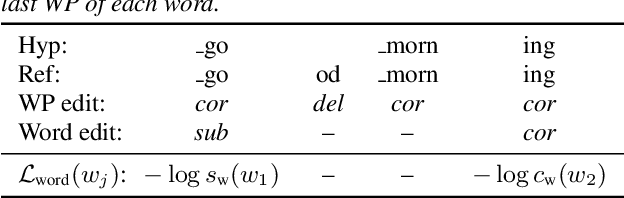
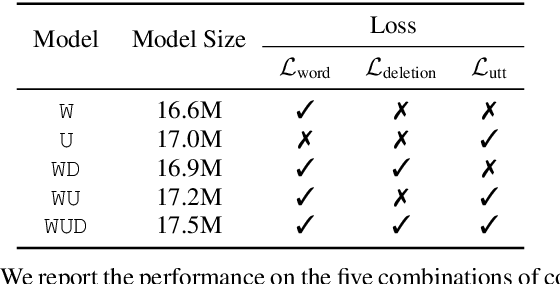
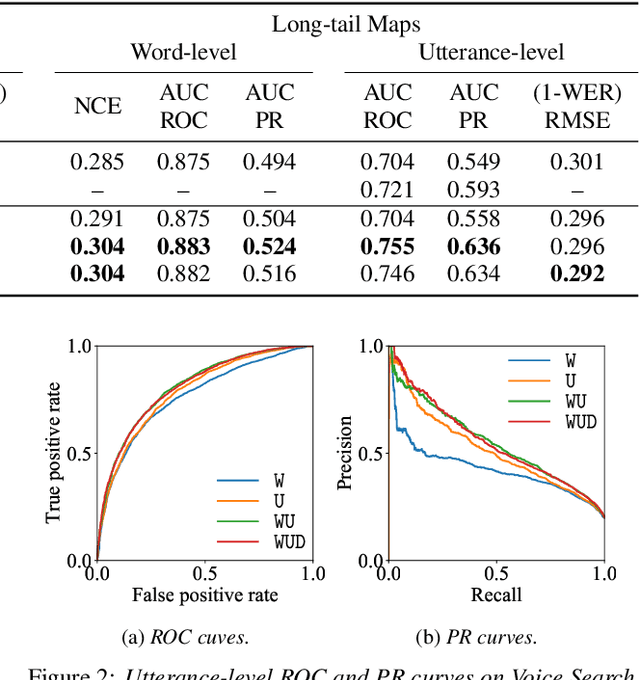
Confidence scores are very useful for downstream applications of automatic speech recognition (ASR) systems. Recent works have proposed using neural networks to learn word or utterance confidence scores for end-to-end ASR. In those studies, word confidence by itself does not model deletions, and utterance confidence does not take advantage of word-level training signals. This paper proposes to jointly learn word confidence, word deletion, and utterance confidence. Empirical results show that multi-task learning with all three objectives improves confidence metrics (NCE, AUC, RMSE) without the need for increasing the model size of the confidence estimation module. Using the utterance-level confidence for rescoring also decreases the word error rates on Google's Voice Search and Long-tail Maps datasets by 3-5% relative, without needing a dedicated neural rescorer.
Learning Word-Level Confidence For Subword End-to-End ASR
Mar 11, 2021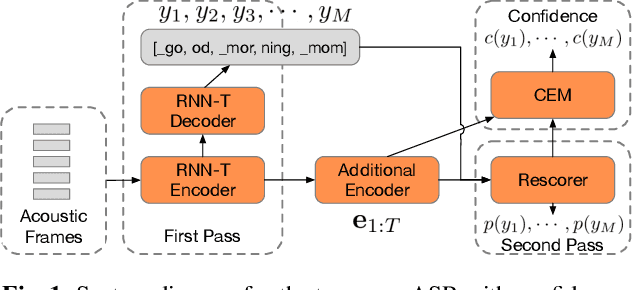

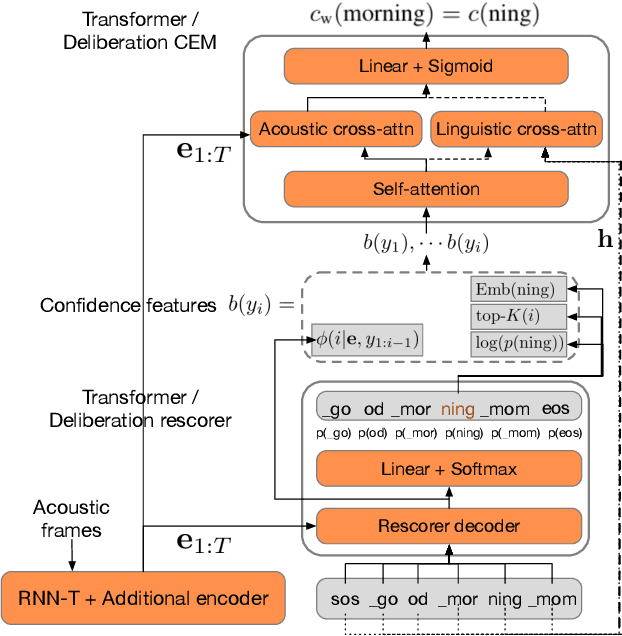
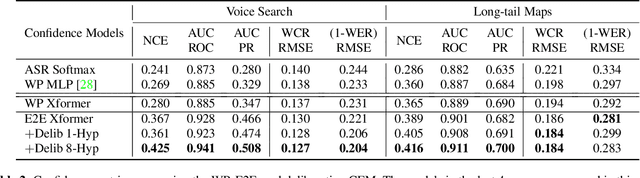
We study the problem of word-level confidence estimation in subword-based end-to-end (E2E) models for automatic speech recognition (ASR). Although prior works have proposed training auxiliary confidence models for ASR systems, they do not extend naturally to systems that operate on word-pieces (WP) as their vocabulary. In particular, ground truth WP correctness labels are needed for training confidence models, but the non-unique tokenization from word to WP causes inaccurate labels to be generated. This paper proposes and studies two confidence models of increasing complexity to solve this problem. The final model uses self-attention to directly learn word-level confidence without needing subword tokenization, and exploits full context features from multiple hypotheses to improve confidence accuracy. Experiments on Voice Search and long-tail test sets show standard metrics (e.g., NCE, AUC, RMSE) improving substantially. The proposed confidence module also enables a model selection approach to combine an on-device E2E model with a hybrid model on the server to address the rare word recognition problem for the E2E model.
Analyzing the Quality and Stability of a Streaming End-to-End On-Device Speech Recognizer
Jun 02, 2020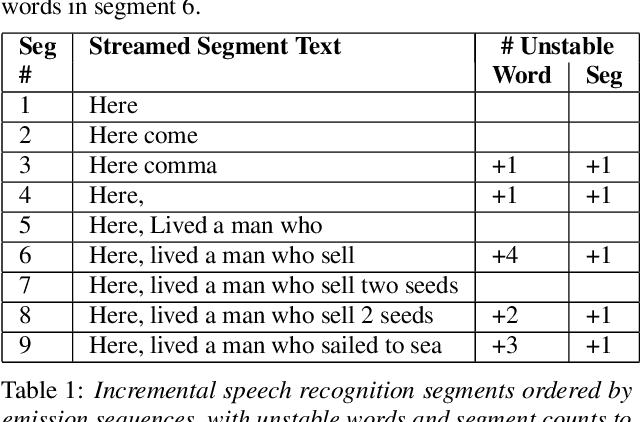
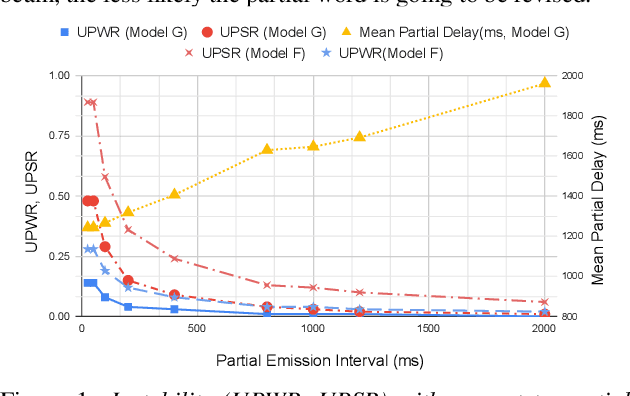
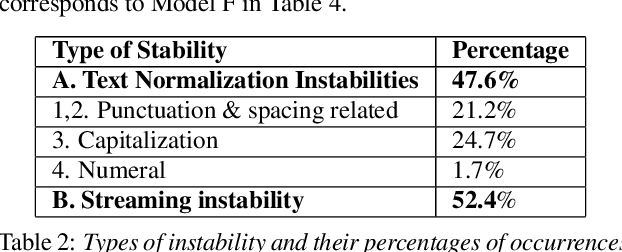
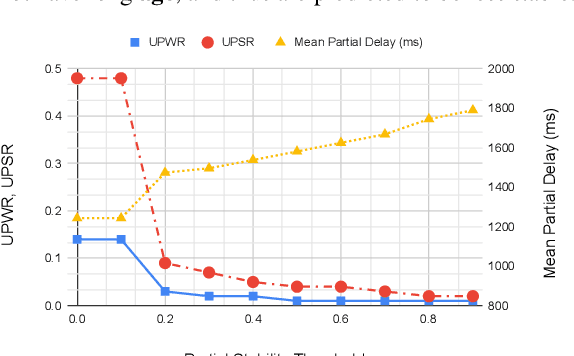
The demand for fast and accurate incremental speech recognition increases as the applications of automatic speech recognition (ASR) proliferate. Incremental speech recognizers output chunks of partially recognized words while the user is still talking. Partial results can be revised before the ASR finalizes its hypothesis, causing instability issues. We analyze the quality and stability of on-device streaming end-to-end (E2E) ASR models. We first introduce a novel set of metrics that quantify the instability at word and segment levels. We study the impact of several model training techniques that improve E2E model qualities but degrade model stability. We categorize the causes of instability and explore various solutions to mitigate them in a streaming E2E ASR system. Index Terms: ASR, stability, end-to-end, text normalization,on-device, RNN-T
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020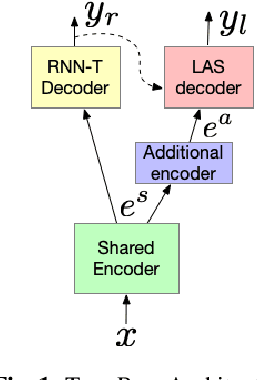
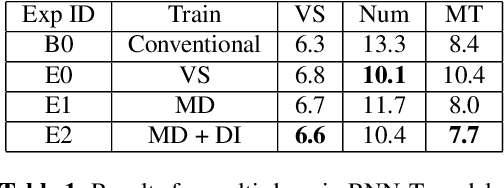
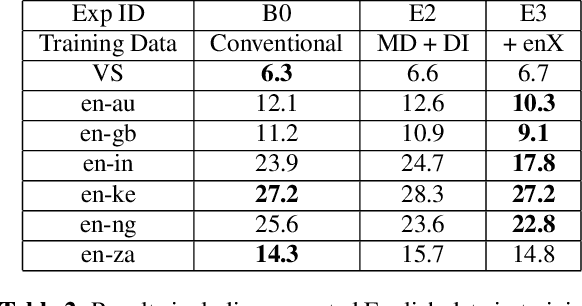
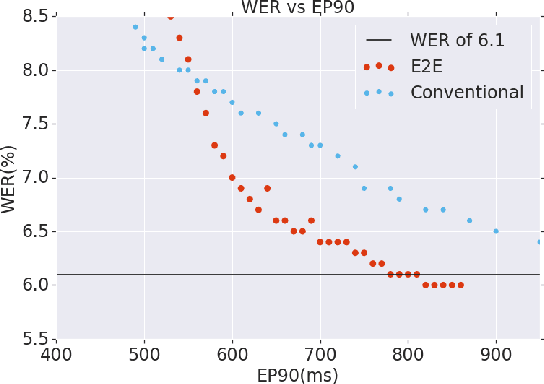
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.