 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hybrid SE(3)-Equivariant Visuomotor Flow Policy via Spherical Harmonics for Robot Manipulation
Mar 24, 2026While existing equivariant methods enhance data efficiency, they suffer from high computational intensity, reliance on single-modality inputs, and instability when combined with fast-sampling methods. In this work, we propose E3Flow, a novel framework that addresses the critical limitations of equivariant diffusion policies. E3Flow overcomes these challenges, successfully unifying efficient rectified flow with stable, multi-modal equivariant learning for the first time. Our framework is built upon spherical harmonic representations to ensure rigorous SO(3) equivariance. We introduce a novel invariant Feature Enhancement Module (FEM) that dynamically fuses hybrid visual modalities (point clouds and images), injecting rich visual cues into the spherical harmonic features. We evaluate E3Flow on 8 manipulation tasks from the MimicGen and further conduct 4 real-world experiments to validate its effectiveness in physical environments. Simulation results show that E3Flow achieves a 3.12% improvement in average success rate over the state-of-the-art Spherical Diffusion Policy (SDP) while simultaneously delivering a 7x inference speedup. E3Flow thus demonstrates a new and highly effective trade-off between performance, efficiency, and data efficiency for robotic policy learning. Code: https://github.com/zql-kk/E3Flow.
SeedPolicy: Horizon Scaling via Self-Evolving Diffusion Policy for Robot Manipulation
Mar 05, 2026Imitation Learning (IL) enables robots to acquire manipulation skills from expert demonstrations. Diffusion Policy (DP) models multi-modal expert behaviors but suffers performance degradation as observation horizons increase, limiting long-horizon manipulation. We propose Self-Evolving Gated Attention (SEGA), a temporal module that maintains a time-evolving latent state via gated attention, enabling efficient recurrent updates that compress long-horizon observations into a fixed-size representation while filtering irrelevant temporal information. Integrating SEGA into DP yields Self-Evolving Diffusion Policy (SeedPolicy), which resolves the temporal modeling bottleneck and enables scalable horizon extension with moderate overhead. On the RoboTwin 2.0 benchmark with 50 manipulation tasks, SeedPolicy outperforms DP and other IL baselines. Averaged across both CNN and Transformer backbones, SeedPolicy achieves 36.8% relative improvement in clean settings and 169% relative improvement in randomized challenging settings over the DP. Compared to vision-language-action models such as RDT with 1.2B parameters, SeedPolicy achieves competitive performance with one to two orders of magnitude fewer parameters, demonstrating strong efficiency and scalability. These results establish SeedPolicy as a state-of-the-art imitation learning method for long-horizon robotic manipulation. Code is available at: https://github.com/Youqiang-Gui/SeedPolicy.
Action-Geometry Prediction with 3D Geometric Prior for Bimanual Manipulation
Feb 27, 2026Bimanual manipulation requires policies that can reason about 3D geometry, anticipate how it evolves under action, and generate smooth, coordinated motions. However, existing methods typically rely on 2D features with limited spatial awareness, or require explicit point clouds that are difficult to obtain reliably in real-world settings. At the same time, recent 3D geometric foundation models show that accurate and diverse 3D structure can be reconstructed directly from RGB images in a fast and robust manner. We leverage this opportunity and propose a framework that builds bimanual manipulation directly on a pre-trained 3D geometric foundation model. Our policy fuses geometry-aware latents, 2D semantic features, and proprioception into a unified state representation, and uses diffusion model to jointly predict a future action chunk and a future 3D latent that decodes into a dense pointmap. By explicitly predicting how the 3D scene will evolve together with the action sequence, the policy gains strong spatial understanding and predictive capability using only RGB observations. We evaluate our method both in simulation on the RoboTwin benchmark and in real-world robot executions. Our approach consistently outperforms 2D-based and point-cloud-based baselines, achieving state-of-the-art performance in manipulation success, inter-arm coordination, and 3D spatial prediction accuracy. Code is available at https://github.com/Chongyang-99/GAP.git.
Blind-Spot Guided Diffusion for Self-supervised Real-World Denoising
Sep 19, 2025In this work, we present Blind-Spot Guided Diffusion, a novel self-supervised framework for real-world image denoising. Our approach addresses two major challenges: the limitations of blind-spot networks (BSNs), which often sacrifice local detail and introduce pixel discontinuities due to spatial independence assumptions, and the difficulty of adapting diffusion models to self-supervised denoising. We propose a dual-branch diffusion framework that combines a BSN-based diffusion branch, generating semi-clean images, with a conventional diffusion branch that captures underlying noise distributions. To enable effective training without paired data, we use the BSN-based branch to guide the sampling process, capturing noise structure while preserving local details. Extensive experiments on the SIDD and DND datasets demonstrate state-of-the-art performance, establishing our method as a highly effective self-supervised solution for real-world denoising. Code and pre-trained models are released at: https://github.com/Sumching/BSGD.
Estimating 2D Camera Motion with Hybrid Motion Basis
Jul 30, 2025Estimating 2D camera motion is a fundamental computer vision task that models the projection of 3D camera movements onto the 2D image plane. Current methods rely on either homography-based approaches, limited to planar scenes, or meshflow techniques that use grid-based local homographies but struggle with complex non-linear transformations. A key insight of our work is that combining flow fields from different homographies creates motion patterns that cannot be represented by any single homography. We introduce CamFlow, a novel framework that represents camera motion using hybrid motion bases: physical bases derived from camera geometry and stochastic bases for complex scenarios. Our approach includes a hybrid probabilistic loss function based on the Laplace distribution that enhances training robustness. For evaluation, we create a new benchmark by masking dynamic objects in existing optical flow datasets to isolate pure camera motion. Experiments show CamFlow outperforms state-of-the-art methods across diverse scenarios, demonstrating superior robustness and generalization in zero-shot settings. Code and datasets are available at our project page: https://lhaippp.github.io/CamFlow/.
You Only Look Around: Learning Illumination Invariant Feature for Low-light Object Detection
Oct 24, 2024In this paper, we introduce YOLA, a novel framework for object detection in low-light scenarios. Unlike previous works, we propose to tackle this challenging problem from the perspective of feature learning. Specifically, we propose to learn illumination-invariant features through the Lambertian image formation model. We observe that, under the Lambertian assumption, it is feasible to approximate illumination-invariant feature maps by exploiting the interrelationships between neighboring color channels and spatially adjacent pixels. By incorporating additional constraints, these relationships can be characterized in the form of convolutional kernels, which can be trained in a detection-driven manner within a network. Towards this end, we introduce a novel module dedicated to the extraction of illumination-invariant features from low-light images, which can be easily integrated into existing object detection frameworks. Our empirical findings reveal significant improvements in low-light object detection tasks, as well as promising results in both well-lit and over-lit scenarios. Code is available at \url{https://github.com/MingboHong/YOLA}.
Neural Spectral Decomposition for Dataset Distillation
Aug 29, 2024
In this paper, we propose Neural Spectrum Decomposition, a generic decomposition framework for dataset distillation. Unlike previous methods, we consider the entire dataset as a high-dimensional observation that is low-rank across all dimensions. We aim to discover the low-rank representation of the entire dataset and perform distillation efficiently. Toward this end, we learn a set of spectrum tensors and transformation matrices, which, through simple matrix multiplication, reconstruct the data distribution. Specifically, a spectrum tensor can be mapped back to the image space by a transformation matrix, and efficient information sharing during the distillation learning process is achieved through pairwise combinations of different spectrum vectors and transformation matrices. Furthermore, we integrate a trajectory matching optimization method guided by a real distribution. Our experimental results demonstrate that our approach achieves state-of-the-art performance on benchmarks, including CIFAR10, CIFAR100, Tiny Imagenet, and ImageNet Subset. Our code are available at \url{https://github.com/slyang2021/NSD}.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
BSRT: Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment
Apr 22, 2022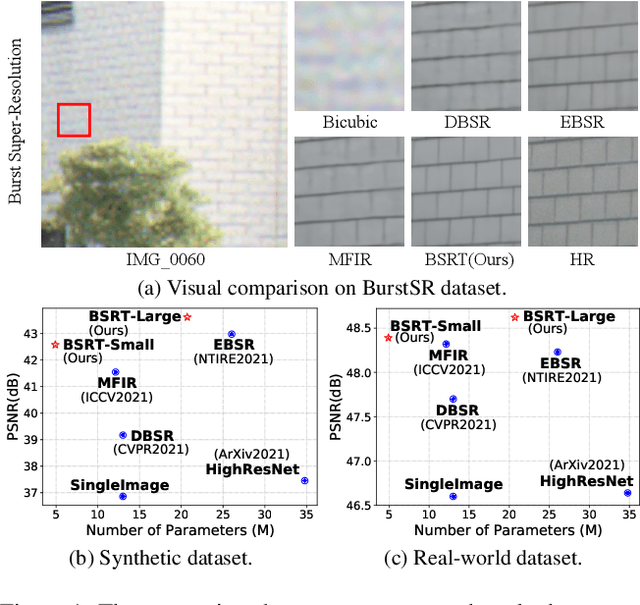
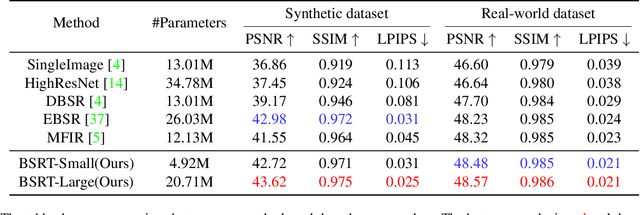
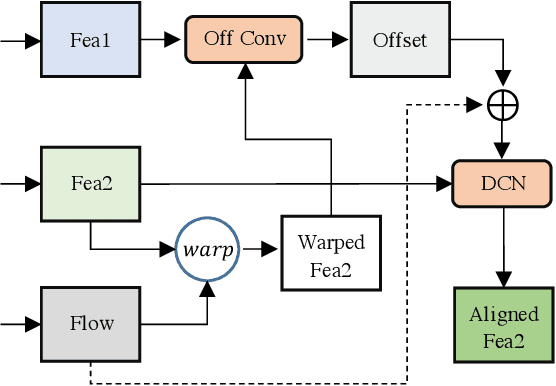
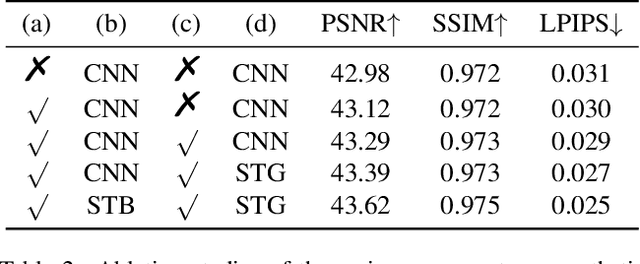
This work addresses the Burst Super-Resolution (BurstSR) task using a new architecture, which requires restoring a high-quality image from a sequence of noisy, misaligned, and low-resolution RAW bursts. To overcome the challenges in BurstSR, we propose a Burst Super-Resolution Transformer (BSRT), which can significantly improve the capability of extracting inter-frame information and reconstruction. To achieve this goal, we propose a Pyramid Flow-Guided Deformable Convolution Network (Pyramid FG-DCN) and incorporate Swin Transformer Blocks and Groups as our main backbone. More specifically, we combine optical flows and deformable convolutions, hence our BSRT can handle misalignment and aggregate the potential texture information in multi-frames more efficiently. In addition, our Transformer-based structure can capture long-range dependency to further improve the performance. The evaluation on both synthetic and real-world tracks demonstrates that our approach achieves a new state-of-the-art in BurstSR task. Further, our BSRT wins the championship in the NTIRE2022 Burst Super-Resolution Challenge.
Fast Camera Image Denoising on Mobile GPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

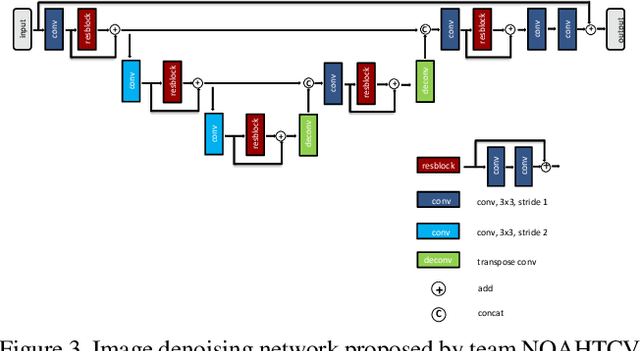
Image denoising is one of the most critical problems in mobile photo processing. While many solutions have been proposed for this task, they are usually working with synthetic data and are too computationally expensive to run on mobile devices. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image denoising solution that can demonstrate high efficiency on smartphone GPUs. For this, the participants were provided with a novel large-scale dataset consisting of noisy-clean image pairs captured in the wild. The runtime of all models was evaluated on the Samsung Exynos 2100 chipset with a powerful Mali GPU capable of accelerating floating-point and quantized neural networks. The proposed solutions are fully compatible with any mobile GPU and are capable of processing 480p resolution images under 40-80 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.