 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from the Irrecoverable: Error-Localized Policy Optimization for Tool-Integrated LLM Reasoning
Feb 10, 2026Tool-integrated reasoning (TIR) enables LLM agents to solve tasks through planning, tool use, and iterative revision, but outcome-only reinforcement learning in this setting suffers from sparse, delayed rewards and weak step-level credit assignment. In long-horizon TIR trajectories, an early irrecoverable mistake can determine success or failure, making it crucial to localize the first irrecoverable step and leverage it for fine-grained credit assignment. We propose Error-Localized Policy Optimization (ELPO), which localizes the first irrecoverable step via binary-search rollout trees under a fixed rollout budget, converts the resulting tree into stable learning signals through hierarchical advantage attribution, and applies error-localized adaptive clipping to strengthen corrective updates on the critical step and its suffix. Across TIR benchmarks in math, science QA, and code execution, ELPO consistently outperforms strong Agentic RL baselines under comparable sampling budgets, with additional gains in Pass@K and Major@K scaling, rollout ranking quality, and tool-call efficiency. Our code will be publicly released soon.
M3HG: Multimodal, Multi-scale, and Multi-type Node Heterogeneous Graph for Emotion Cause Triplet Extraction in Conversations
Aug 26, 2025



Emotion Cause Triplet Extraction in Multimodal Conversations (MECTEC) has recently gained significant attention in social media analysis, aiming to extract emotion utterances, cause utterances, and emotion categories simultaneously. However, the scarcity of related datasets, with only one published dataset featuring highly uniform dialogue scenarios, hinders model development in this field. To address this, we introduce MECAD, the first multimodal, multi-scenario MECTEC dataset, comprising 989 conversations from 56 TV series spanning a wide range of dialogue contexts. In addition, existing MECTEC methods fail to explicitly model emotional and causal contexts and neglect the fusion of semantic information at different levels, leading to performance degradation. In this paper, we propose M3HG, a novel model that explicitly captures emotional and causal contexts and effectively fuses contextual information at both inter- and intra-utterance levels via a multimodal heterogeneous graph. Extensive experiments demonstrate the effectiveness of M3HG compared with existing state-of-the-art methods. The codes and dataset are available at https://github.com/redifinition/M3HG.
* 16 pages, 8 figures. Accepted to Findings of ACL 2025
A Multifacet Hierarchical Sentiment-Topic Model with Application to Multi-Brand Online Review Analysis
Feb 26, 2025Multi-brand analysis based on review comments and ratings is a commonly used strategy to compare different brands in marketing. It can help consumers make more informed decisions and help marketers understand their brand's position in the market. In this work, we propose a multifacet hierarchical sentiment-topic model (MH-STM) to detect brand-associated sentiment polarities towards multiple comparative aspects from online customer reviews. The proposed method is built on a unified generative framework that explains review words with a hierarchical brand-associated topic model and the overall polarity score with a regression model on the empirical topic distribution. Moreover, a novel hierarchical Polya urn (HPU) scheme is proposed to enhance the topic-word association among topic hierarchy, such that the general topics shared by all brands are separated effectively from the unique topics specific to individual brands. The performance of the proposed method is evaluated on both synthetic data and two real-world review corpora. Experimental studies demonstrate that the proposed method can be effective in detecting reasonable topic hierarchy and deriving accurate brand-associated rankings on multi-aspects.
PerlDiff: Controllable Street View Synthesis Using Perspective-Layout Diffusion Models
Jul 08, 2024



Controllable generation is considered a potentially vital approach to address the challenge of annotating 3D data, and the precision of such controllable generation becomes particularly imperative in the context of data production for autonomous driving. Existing methods focus on the integration of diverse generative information into controlling inputs, utilizing frameworks such as GLIGEN or ControlNet, to produce commendable outcomes in controllable generation. However, such approaches intrinsically restrict generation performance to the learning capacities of predefined network architectures. In this paper, we explore the integration of controlling information and introduce PerlDiff (Perspective-Layout Diffusion Models), a method for effective street view image generation that fully leverages perspective 3D geometric information. Our PerlDiff employs 3D geometric priors to guide the generation of street view images with precise object-level control within the network learning process, resulting in a more robust and controllable output. Moreover, it demonstrates superior controllability compared to alternative layout control methods. Empirical results justify that our PerlDiff markedly enhances the precision of generation on the NuScenes and KITTI datasets. Our codes and models are publicly available at https://github.com/LabShuHangGU/PerlDiff.
CT3D++: Improving 3D Object Detection with Keypoint-induced Channel-wise Transformer
Jun 12, 2024



The field of 3D object detection from point clouds is rapidly advancing in computer vision, aiming to accurately and efficiently detect and localize objects in three-dimensional space. Current 3D detectors commonly fall short in terms of flexibility and scalability, with ample room for advancements in performance. In this paper, our objective is to address these limitations by introducing two frameworks for 3D object detection with minimal hand-crafted design. Firstly, we propose CT3D, which sequentially performs raw-point-based embedding, a standard Transformer encoder, and a channel-wise decoder for point features within each proposal. Secondly, we present an enhanced network called CT3D++, which incorporates geometric and semantic fusion-based embedding to extract more valuable and comprehensive proposal-aware information. Additionally, CT3D ++ utilizes a point-to-key bidirectional encoder for more efficient feature encoding with reduced computational cost. By replacing the corresponding components of CT3D with these novel modules, CT3D++ achieves state-of-the-art performance on both the KITTI dataset and the large-scale Way\-mo Open Dataset. The source code for our frameworks will be made accessible at https://github.com/hlsheng1/CT3D-plusplus.
RoScenes: A Large-scale Multi-view 3D Dataset for Roadside Perception
May 17, 2024



We introduce RoScenes, the largest multi-view roadside perception dataset, which aims to shed light on the development of vision-centric Bird's Eye View (BEV) approaches for more challenging traffic scenes. The highlights of RoScenes include significantly large perception area, full scene coverage and crowded traffic. More specifically, our dataset achieves surprising 21.13M 3D annotations within 64,000 $m^2$. To relieve the expensive costs of roadside 3D labeling, we present a novel BEV-to-3D joint annotation pipeline to efficiently collect such a large volume of data. After that, we organize a comprehensive study for current BEV methods on RoScenes in terms of effectiveness and efficiency. Tested methods suffer from the vast perception area and variation of sensor layout across scenes, resulting in performance levels falling below expectations. To this end, we propose RoBEV that incorporates feature-guided position embedding for effective 2D-3D feature assignment. With its help, our method outperforms state-of-the-art by a large margin without extra computational overhead on validation set. Our dataset and devkit will be made available at https://github.com/xiaosu-zhu/RoScenes.
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Jun 08, 2023



Enabling large language models to effectively utilize real-world tools is crucial for achieving embodied intelligence. Existing approaches to tool learning have primarily relied on either extremely large language models, such as GPT-4, to attain generalized tool-use abilities in a zero-shot manner, or have utilized supervised learning to train limited types of tools on compact models. However, it remains uncertain whether smaller language models can achieve generalized tool-use abilities without specific tool-specific training. To address this question, this paper introduces ToolAlpaca, a novel framework designed to automatically generate a tool-use corpus and learn generalized tool-use abilities on compact language models with minimal human intervention. Specifically, ToolAlpaca first collects a comprehensive dataset by building a multi-agent simulation environment, which contains 3938 tool-use instances from more than 400 real-world tool APIs spanning 50 distinct categories. Subsequently, the constructed corpus is employed to fine-tune compact language models, resulting in two models, namely ToolAlpaca-7B and ToolAlpaca-13B, respectively. Finally, we evaluate the ability of these models to utilize previously unseen tools without specific training. Experimental results demonstrate that ToolAlpaca achieves effective generalized tool-use capabilities comparable to those of extremely large language models like GPT-3.5. This validation supports the notion that learning generalized tool-use abilities is feasible for compact language models.
A Language Agnostic Multilingual Streaming On-Device ASR System
Aug 29, 2022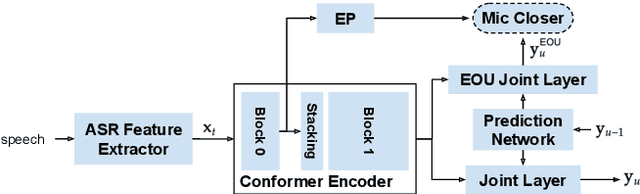
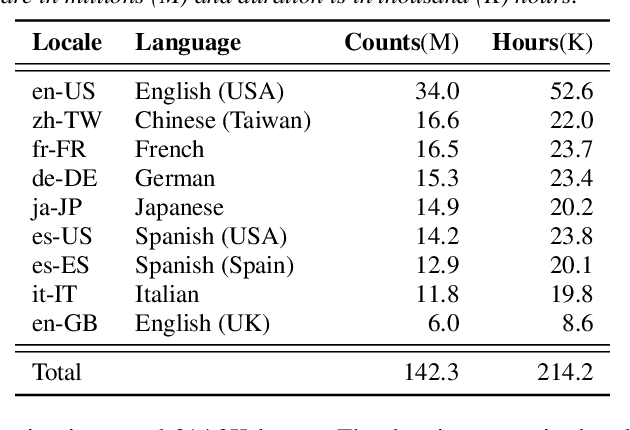
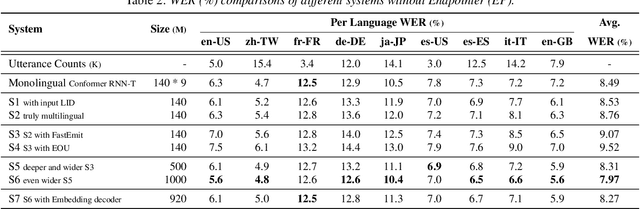
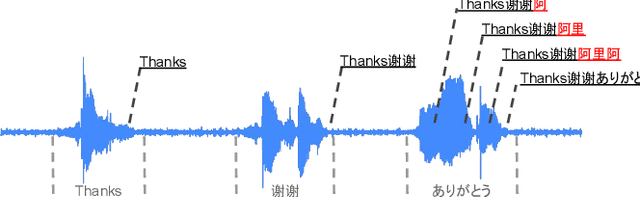
On-device end-to-end (E2E) models have shown improvements over a conventional model on English Voice Search tasks in both quality and latency. E2E models have also shown promising results for multilingual automatic speech recognition (ASR). In this paper, we extend our previous capacity solution to streaming applications and present a streaming multilingual E2E ASR system that runs fully on device with comparable quality and latency to individual monolingual models. To achieve that, we propose an Encoder Endpointer model and an End-of-Utterance (EOU) Joint Layer for a better quality and latency trade-off. Our system is built in a language agnostic manner allowing it to natively support intersentential code switching in real time. To address the feasibility concerns on large models, we conducted on-device profiling and replaced the time consuming LSTM decoder with the recently developed Embedding decoder. With these changes, we managed to run such a system on a mobile device in less than real time.
Streaming Intended Query Detection using E2E Modeling for Continued Conversation
Aug 29, 2022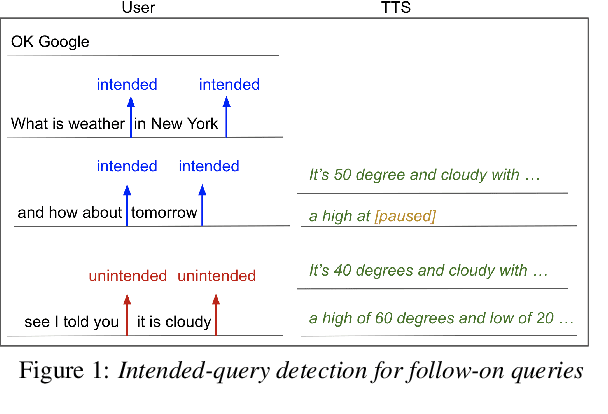

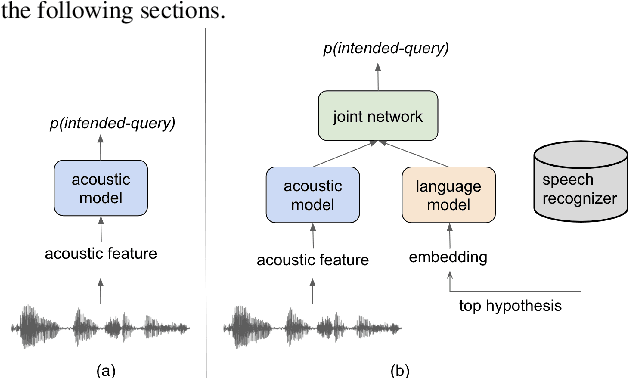
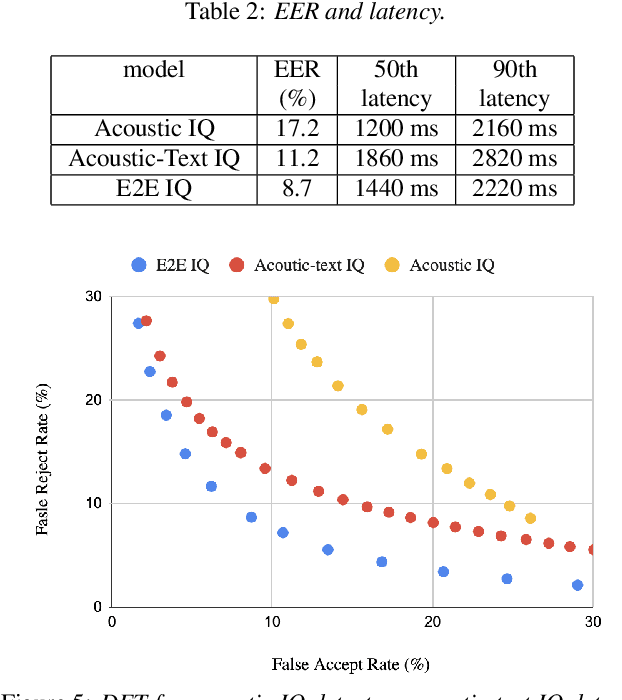
In voice-enabled applications, a predetermined hotword isusually used to activate a device in order to attend to the query.However, speaking queries followed by a hotword each timeintroduces a cognitive burden in continued conversations. Toavoid repeating a hotword, we propose a streaming end-to-end(E2E) intended query detector that identifies the utterancesdirected towards the device and filters out other utterancesnot directed towards device. The proposed approach incor-porates the intended query detector into the E2E model thatalready folds different components of the speech recognitionpipeline into one neural network.The E2E modeling onspeech decoding and intended query detection also allows us todeclare a quick intended query detection based on early partialrecognition result, which is important to decrease latencyand make the system responsive. We demonstrate that theproposed E2E approach yields a 22% relative improvement onequal error rate (EER) for the detection accuracy and 600 mslatency improvement compared with an independent intendedquery detector. In our experiment, the proposed model detectswhether the user is talking to the device with a 8.7% EERwithin 1.4 seconds of median latency after user starts speaking.
Turn-Taking Prediction for Natural Conversational Speech
Aug 29, 2022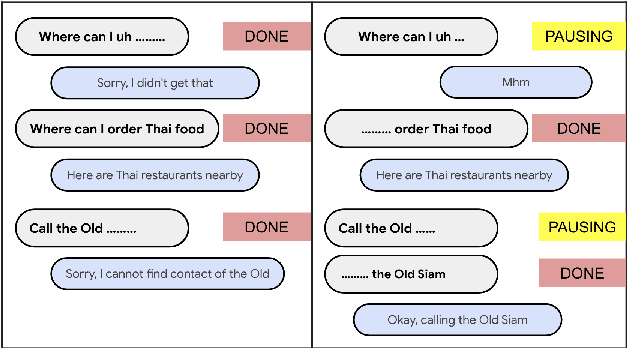
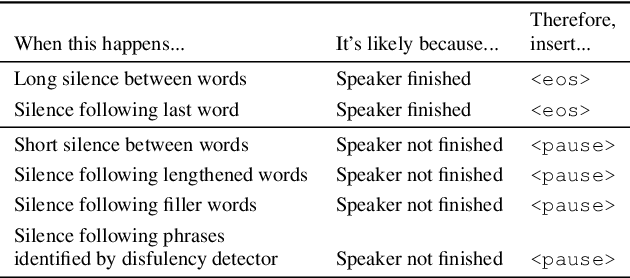
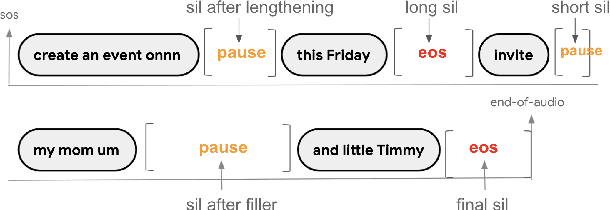
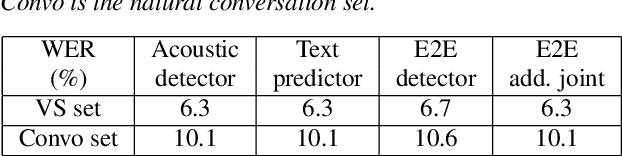
While a streaming voice assistant system has been used in many applications, this system typically focuses on unnatural, one-shot interactions assuming input from a single voice query without hesitation or disfluency. However, a common conversational utterance often involves multiple queries with turn-taking, in addition to disfluencies. These disfluencies include pausing to think, hesitations, word lengthening, filled pauses and repeated phrases. This makes doing speech recognition with conversational speech, including one with multiple queries, a challenging task. To better model the conversational interaction, it is critical to discriminate disfluencies and end of query in order to allow the user to hold the floor for disfluencies while having the system respond as quickly as possible when the user has finished speaking. In this paper, we present a turntaking predictor built on top of the end-to-end (E2E) speech recognizer. Our best system is obtained by jointly optimizing for ASR task and detecting when the user is paused to think or finished speaking. The proposed approach demonstrates over 97% recall rate and 85% precision rate on predicting true turn-taking with only 100 ms latency on a test set designed with 4 types of disfluencies inserted in conversational utterances.