 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
Apr 21, 2026Synthesizing human--object interaction (HOI) videos has broad practical value in e-commerce, digital advertising, and virtual marketing. However, current diffusion models, despite their photorealistic rendering capability, still frequently fail on (i) the structural stability of sensitive regions such as hands and faces and (ii) physically plausible contact (e.g., avoiding hand--object interpenetration). We present CoInteract, an end-to-end framework for HOI video synthesis conditioned on a person reference image, a product reference image, text prompts, and speech audio. CoInteract introduces two complementary designs embedded into a Diffusion Transformer (DiT) backbone. First, we propose a Human-Aware Mixture-of-Experts (MoE) that routes tokens to lightweight, region-specialized experts via spatially supervised routing, improving fine-grained structural fidelity with minimal parameter overhead. Second, we propose Spatially-Structured Co-Generation, a dual-stream training paradigm that jointly models an RGB appearance stream and an auxiliary HOI structure stream to inject interaction geometry priors. During training, the HOI stream attends to RGB tokens and its supervision regularizes shared backbone weights; at inference, the HOI branch is removed for zero-overhead RGB generation. Experimental results demonstrate that CoInteract significantly outperforms existing methods in structural stability, logical consistency, and interaction realism.
Attention Grounded Enhancement for Visual Document Retrieval
Nov 17, 2025Visual document retrieval requires understanding heterogeneous and multi-modal content to satisfy information needs. Recent advances use screenshot-based document encoding with fine-grained late interaction, significantly improving retrieval performance. However, retrievers are still trained with coarse global relevance labels, without revealing which regions support the match. As a result, retrievers tend to rely on surface-level cues and struggle to capture implicit semantic connections, hindering their ability to handle non-extractive queries. To alleviate this problem, we propose a \textbf{A}ttention-\textbf{G}rounded \textbf{RE}triever \textbf{E}nhancement (AGREE) framework. AGREE leverages cross-modal attention from multimodal large language models as proxy local supervision to guide the identification of relevant document regions. During training, AGREE combines local signals with the global signals to jointly optimize the retriever, enabling it to learn not only whether documents match, but also which content drives relevance. Experiments on the challenging ViDoRe V2 benchmark show that AGREE significantly outperforms the global-supervision-only baseline. Quantitative and qualitative analyses further demonstrate that AGREE promotes deeper alignment between query terms and document regions, moving beyond surface-level matching toward more accurate and interpretable retrieval. Our code is available at: https://anonymous.4open.science/r/AGREE-2025.
LiveThinking: Enabling Real-Time Efficient Reasoning for AI-Powered Livestreaming via Reinforcement Learning
Oct 09, 2025



In AI-powered e-commerce livestreaming, digital avatars require real-time responses to drive engagement, a task for which high-latency Large Reasoning Models (LRMs) are ill-suited. We introduce LiveThinking, a practical two-stage optimization framework to bridge this gap. First, we address computational cost by distilling a 670B teacher LRM into a lightweight 30B Mixture-of-Experts (MoE) model (3B active) using Rejection Sampling Fine-Tuning (RFT). This reduces deployment overhead but preserves the teacher's verbose reasoning, causing latency. To solve this, our second stage employs reinforcement learning with Group Relative Policy Optimization (GRPO) to compress the model's reasoning path, guided by a multi-objective reward function balancing correctness, helpfulness, and brevity. LiveThinking achieves a 30-fold reduction in computational cost, enabling sub-second latency. In real-world application on Taobao Live, it improved response correctness by 3.3% and helpfulness by 21.8%. Tested by hundreds of thousands of viewers, our system led to a statistically significant increase in Gross Merchandise Volume (GMV), demonstrating its effectiveness in enhancing user experience and commercial performance in live, interactive settings.
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Apr 09, 2024



Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
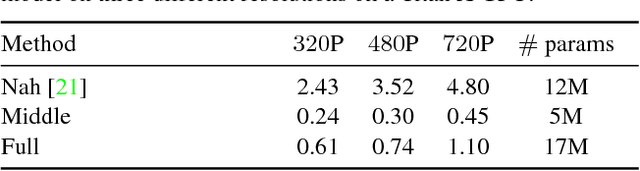
MFDNet: Towards Real-time Image Denoising On Mobile Devices
Nov 09, 2022



Deep convolutional neural networks have achieved great progress in image denoising tasks. However, their complicated architectures and heavy computational cost hinder their deployments on a mobile device. Some recent efforts in designing lightweight denoising networks focus on reducing either FLOPs (floating-point operations) or the number of parameters. However, these metrics are not directly correlated with the on-device latency. By performing extensive analysis and experiments, we identify the network architectures that can fully utilize powerful neural processing units (NPUs) and thus enjoy both low latency and excellent denoising performance. To this end, we propose a mobile-friendly denoising network, namely MFDNet. The experiments show that MFDNet achieves state-of-the-art performance on real-world denoising benchmarks SIDD and DND under real-time latency on mobile devices. The code and pre-trained models will be released.
SepLUT: Separable Image-adaptive Lookup Tables for Real-time Image Enhancement
Jul 18, 2022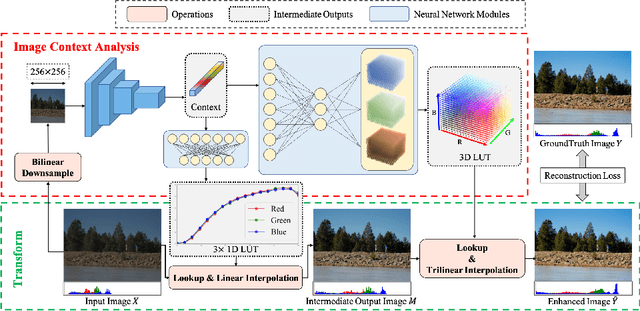
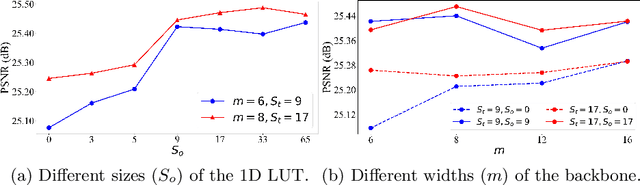
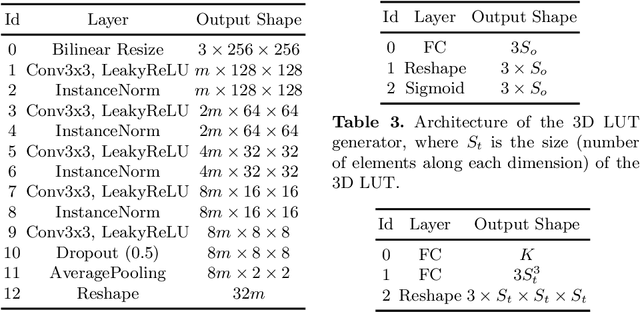
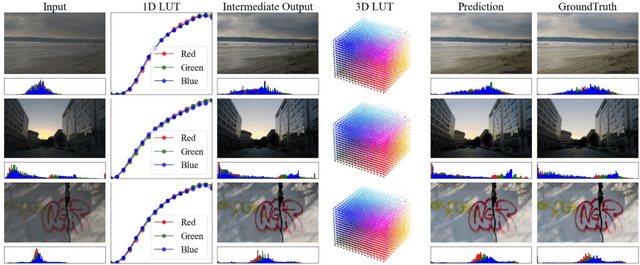
Image-adaptive lookup tables (LUTs) have achieved great success in real-time image enhancement tasks due to their high efficiency for modeling color transforms. However, they embed the complete transform, including the color component-independent and the component-correlated parts, into only a single type of LUTs, either 1D or 3D, in a coupled manner. This scheme raises a dilemma of improving model expressiveness or efficiency due to two factors. On the one hand, the 1D LUTs provide high computational efficiency but lack the critical capability of color components interaction. On the other, the 3D LUTs present enhanced component-correlated transform capability but suffer from heavy memory footprint, high training difficulty, and limited cell utilization. Inspired by the conventional divide-and-conquer practice in the image signal processor, we present SepLUT (separable image-adaptive lookup table) to tackle the above limitations. Specifically, we separate a single color transform into a cascade of component-independent and component-correlated sub-transforms instantiated as 1D and 3D LUTs, respectively. In this way, the capabilities of two sub-transforms can facilitate each other, where the 3D LUT complements the ability to mix up color components, and the 1D LUT redistributes the input colors to increase the cell utilization of the 3D LUT and thus enable the use of a more lightweight 3D LUT. Experiments demonstrate that the proposed method presents enhanced performance on photo retouching benchmark datasets than the current state-of-the-art and achieves real-time processing on both GPUs and CPUs.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
AdaInt: Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement
Apr 29, 2022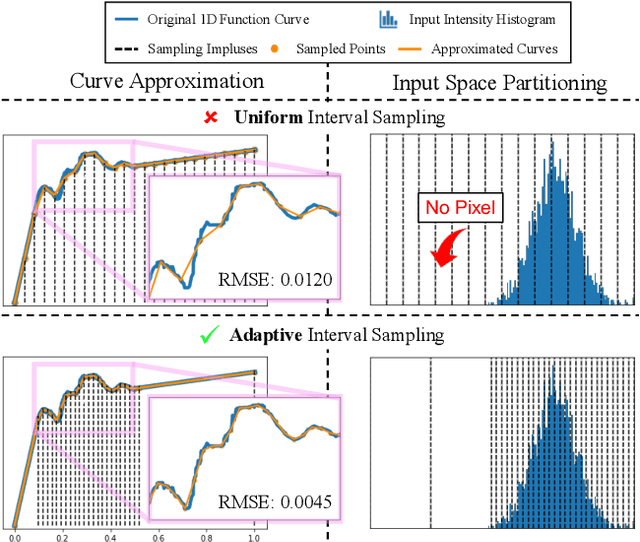

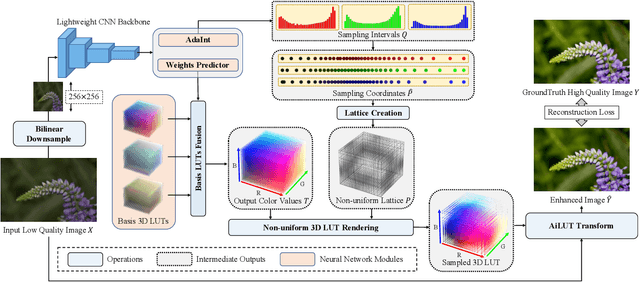
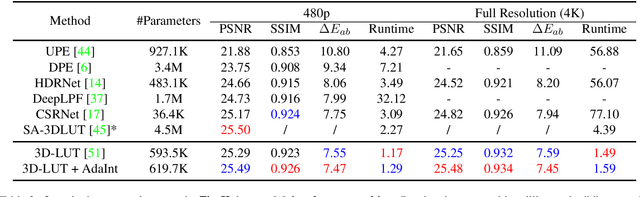
The 3D Lookup Table (3D LUT) is a highly-efficient tool for real-time image enhancement tasks, which models a non-linear 3D color transform by sparsely sampling it into a discretized 3D lattice. Previous works have made efforts to learn image-adaptive output color values of LUTs for flexible enhancement but neglect the importance of sampling strategy. They adopt a sub-optimal uniform sampling point allocation, limiting the expressiveness of the learned LUTs since the (tri-)linear interpolation between uniform sampling points in the LUT transform might fail to model local non-linearities of the color transform. Focusing on this problem, we present AdaInt (Adaptive Intervals Learning), a novel mechanism to achieve a more flexible sampling point allocation by adaptively learning the non-uniform sampling intervals in the 3D color space. In this way, a 3D LUT can increase its capability by conducting dense sampling in color ranges requiring highly non-linear transforms and sparse sampling for near-linear transforms. The proposed AdaInt could be implemented as a compact and efficient plug-and-play module for a 3D LUT-based method. To enable the end-to-end learning of AdaInt, we design a novel differentiable operator called AiLUT-Transform (Adaptive Interval LUT Transform) to locate input colors in the non-uniform 3D LUT and provide gradients to the sampling intervals. Experiments demonstrate that methods equipped with AdaInt can achieve state-of-the-art performance on two public benchmark datasets with a negligible overhead increase. Our source code is available at https://github.com/ImCharlesY/AdaInt.
Learning to Extract a Video Sequence from a Single Motion-Blurred Image
Apr 11, 2018


We present a method to extract a video sequence from a single motion-blurred image. Motion-blurred images are the result of an averaging process, where instant frames are accumulated over time during the exposure of the sensor. Unfortunately, reversing this process is nontrivial. Firstly, averaging destroys the temporal ordering of the frames. Secondly, the recovery of a single frame is a blind deconvolution task, which is highly ill-posed. We present a deep learning scheme that gradually reconstructs a temporal ordering by sequentially extracting pairs of frames. Our main contribution is to introduce loss functions invariant to the temporal order. This lets a neural network choose during training what frame to output among the possible combinations. We also address the ill-posedness of deblurring by designing a network with a large receptive field and implemented via resampling to achieve a higher computational efficiency. Our proposed method can successfully retrieve sharp image sequences from a single motion blurred image and can generalize well on synthetic and real datasets captured with different cameras.
Deep Mean-Shift Priors for Image Restoration
Oct 04, 2017

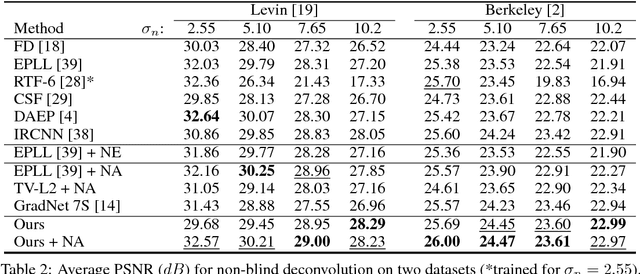

In this paper we introduce a natural image prior that directly represents a Gaussian-smoothed version of the natural image distribution. We include our prior in a formulation of image restoration as a Bayes estimator that also allows us to solve noise-blind image restoration problems. We show that the gradient of our prior corresponds to the mean-shift vector on the natural image distribution. In addition, we learn the mean-shift vector field using denoising autoencoders, and use it in a gradient descent approach to perform Bayes risk minimization. We demonstrate competitive results for noise-blind deblurring, super-resolution, and demosaicing.