 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Video Flare Synthesis and Removal Leveraging Motion Independence between Flare and Scene
Dec 12, 2025Lens flare is a degradation phenomenon caused by strong light sources. Existing researches on flare removal have mainly focused on images, while the spatiotemporal characteristics of video flare remain largely unexplored. Video flare synthesis and removal pose significantly greater challenges than in image, owing to the complex and mutually independent motion of flare, light sources, and scene content. This motion independence further affects restoration performance, often resulting in flicker and artifacts. To address this issue, we propose a physics-informed dynamic flare synthesis pipeline, which simulates light source motion using optical flow and models the temporal behaviors of both scattering and reflective flares. Meanwhile, we design a video flare removal network that employs an attention module to spatially suppress flare regions and incorporates a Mamba-based temporal modeling component to capture long range spatio-temporal dependencies. This motion-independent spatiotemporal representation effectively eliminates the need for multi-frame alignment, alleviating temporal aliasing between flares and scene content and thereby improving video flare removal performance. Building upon this, we construct the first video flare dataset to comprehensively evaluate our method, which includes a large set of synthetic paired videos and additional real-world videos collected from the Internet to assess generalization capability. Extensive experiments demonstrate that our method consistently outperforms existing video-based restoration and image-based flare removal methods on both real and synthetic videos, effectively removing dynamic flares while preserving light source integrity and maintaining spatiotemporal consistency of scene.
Beyond Image Prior: Embedding Noise Prior into Conditional Denoising Transformer
Jul 12, 2024



Existing learning-based denoising methods typically train models to generalize the image prior from large-scale datasets, suffering from the variability in noise distributions encountered in real-world scenarios. In this work, we propose a new perspective on the denoising challenge by highlighting the distinct separation between noise and image priors. This insight forms the basis for our development of conditional optimization framework, designed to overcome the constraints of traditional denoising framework. To this end, we introduce a Locally Noise Prior Estimation (LoNPE) algorithm, which accurately estimates the noise prior directly from a single raw noisy image. This estimation acts as an explicit prior representation of the camera sensor's imaging environment, distinct from the image prior of scenes. Additionally, we design an auxiliary learnable LoNPE network tailored for practical application to sRGB noisy images. Leveraging the estimated noise prior, we present a novel Conditional Denoising Transformer (Condformer), by incorporating the noise prior into a conditional self-attention mechanism. This integration allows the Condformer to segment the optimization process into multiple explicit subspaces, significantly enhancing the model's generalization and flexibility. Extensive experimental evaluations on both synthetic and real-world datasets, demonstrate that the proposed method achieves superior performance over current state-of-the-art methods. The source code is available at https://github.com/YuanfeiHuang/Condformer.
Weak Generative Sampler to Efficiently Sample Invariant Distribution of Stochastic Differential Equation
May 29, 2024



Sampling invariant distributions from an Ito diffusion process presents a significant challenge in stochastic simulation. Traditional numerical solvers for stochastic differential equations require both a fine step size and a lengthy simulation period, resulting in both biased and correlated samples. Current deep learning-based method solves the stationary Fokker--Planck equation to determine the invariant probability density function in form of deep neural networks, but they generally do not directly address the problem of sampling from the computed density function. In this work, we introduce a framework that employs a weak generative sampler (WGS) to directly generate independent and identically distributed (iid) samples induced by a transformation map derived from the stationary Fokker--Planck equation. Our proposed loss function is based on the weak form of the Fokker--Planck equation, integrating normalizing flows to characterize the invariant distribution and facilitate sample generation from the base distribution. Our randomized test function circumvents the need for mini-max optimization in the traditional weak formulation. Distinct from conventional generative models, our method neither necessitates the computationally intensive calculation of the Jacobian determinant nor the invertibility of the transformation map. A crucial component of our framework is the adaptively chosen family of test functions in the form of Gaussian kernel functions with centres selected from the generated data samples. Experimental results on several benchmark examples demonstrate the effectiveness of our method, which offers both low computational costs and excellent capability in exploring multiple metastable states.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Image-specific Convolutional Kernel Modulation for Single Image Super-resolution
Nov 16, 2021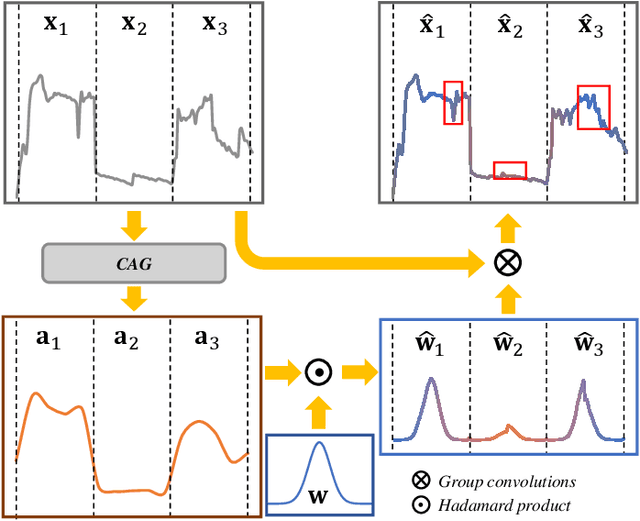
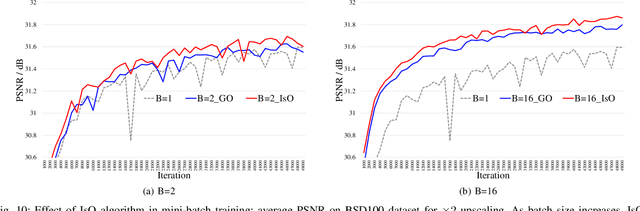
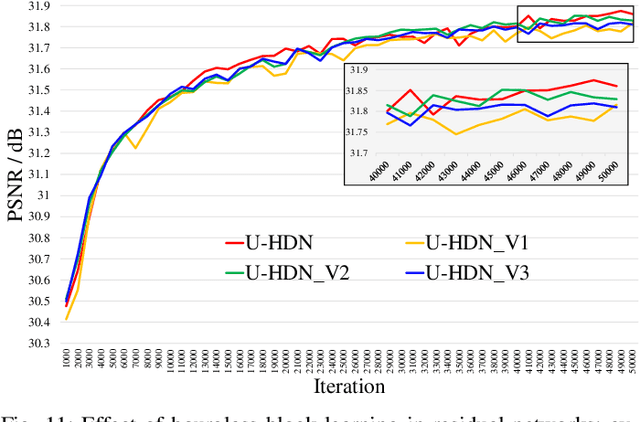
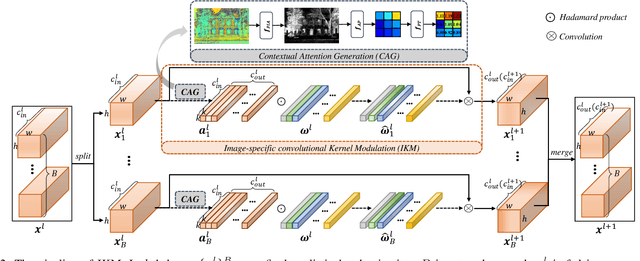
Recently, deep-learning-based super-resolution methods have achieved excellent performances, but mainly focus on training a single generalized deep network by feeding numerous samples. Yet intuitively, each image has its representation, and is expected to acquire an adaptive model. For this issue, we propose a novel image-specific convolutional kernel modulation (IKM) by exploiting the global contextual information of image or feature to generate an attention weight for adaptively modulating the convolutional kernels, which outperforms the vanilla convolution and several existing attention mechanisms while embedding into the state-of-the-art architectures without any additional parameters. Particularly, to optimize our IKM in mini-batch training, we introduce an image-specific optimization (IsO) algorithm, which is more effective than the conventional mini-batch SGD optimization. Furthermore, we investigate the effect of IKM on the state-of-the-art architectures and exploit a new backbone with U-style residual learning and hourglass dense block learning, terms U-Hourglass Dense Network (U-HDN), which is an appropriate architecture to utmost improve the effectiveness of IKM theoretically and experimentally. Extensive experiments on single image super-resolution show that the proposed methods achieve superior performances over state-of-the-art methods. Code is available at github.com/YuanfeiHuang/IKM.
Transitive Learning: Exploring the Transitivity of Degradations for Blind Super-Resolution
Mar 29, 2021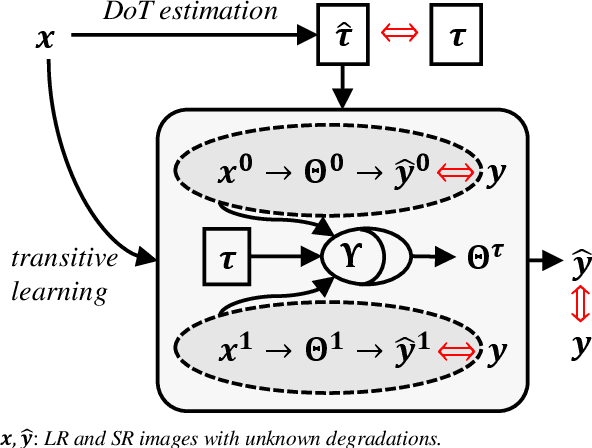
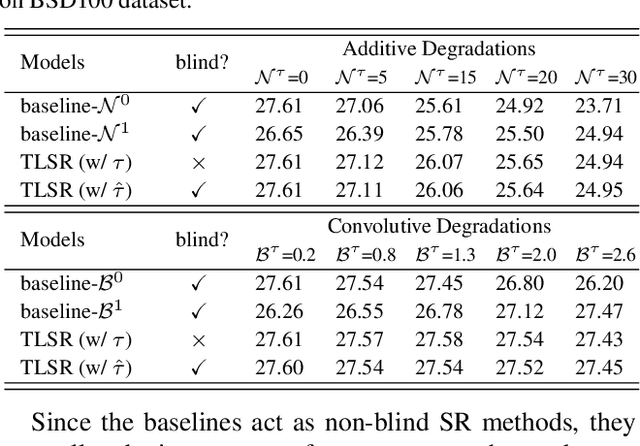
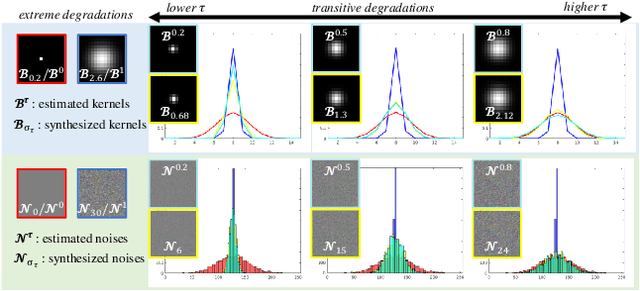
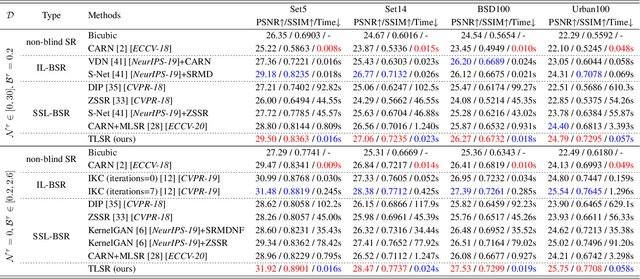
Being extremely dependent on the iterative estimation and correction of data or models, the existing blind super-resolution (SR) methods are generally time-consuming and less effective. To address it, this paper proposes a transitive learning method for blind SR using an end-to-end network without any additional iterations in inference. To begin with, we analyze and demonstrate the transitivity of degradations, including the widely used additive and convolutive degradations. We then propose a novel Transitive Learning method for blind Super-Resolution on transitive degradations (TLSR), by adaptively inferring a transitive transformation function to solve the unknown degradations without any iterative operations in inference. Specifically, the end-to-end TLSR network consists of a degree of transitivity (DoT) estimation network, a homogeneous feature extraction network, and a transitive learning module. Quantitative and qualitative evaluations on blind SR tasks demonstrate that the proposed TLSR achieves superior performance and consumes less time against the state-of-the-art blind SR methods. The code is available at https://github.com/YuanfeiHuang/TLSR.
Interpretable Detail-Fidelity Attention Network for Single Image Super-Resolution
Sep 28, 2020

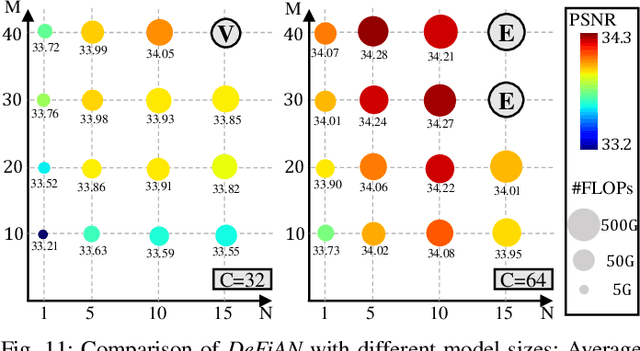
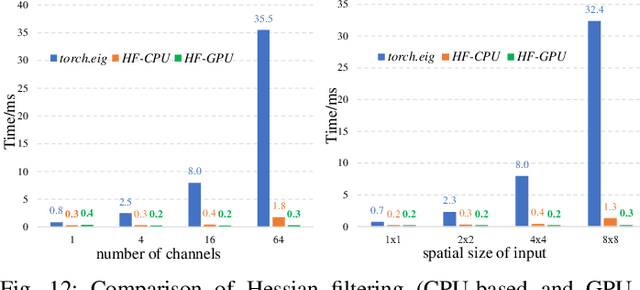
Benefiting from the strong capabilities of deep CNNs for feature representation and nonlinear mapping, deep-learning-based methods have achieved excellent performance in single image super-resolution. However, most existing SR methods depend on the high capacity of networks which is initially designed for visual recognition, and rarely consider the initial intention of super-resolution for detail fidelity. Aiming at pursuing this intention, there are two challenging issues to be solved: (1) learning appropriate operators which is adaptive to the diverse characteristics of smoothes and details; (2) improving the ability of model to preserve the low-frequency smoothes and reconstruct the high-frequency details. To solve them, we propose a purposeful and interpretable detail-fidelity attention network to progressively process these smoothes and details in divide-and-conquer manner, which is a novel and specific prospect of image super-resolution for the purpose on improving the detail fidelity, instead of blindly designing or employing the deep CNNs architectures for merely feature representation in local receptive fields. Particularly, we propose a Hessian filtering for interpretable feature representation which is high-profile for detail inference, a dilated encoder-decoder and a distribution alignment cell to improve the inferred Hessian features in morphological manner and statistical manner respectively. Extensive experiments demonstrate that the proposed methods achieve superior performances over the state-of-the-art methods quantitatively and qualitatively. Code is available at https://github.com/YuanfeiHuang/DeFiAN.
AIM 2019 Challenge on Real-World Image Super-Resolution: Methods and Results
Nov 19, 2019
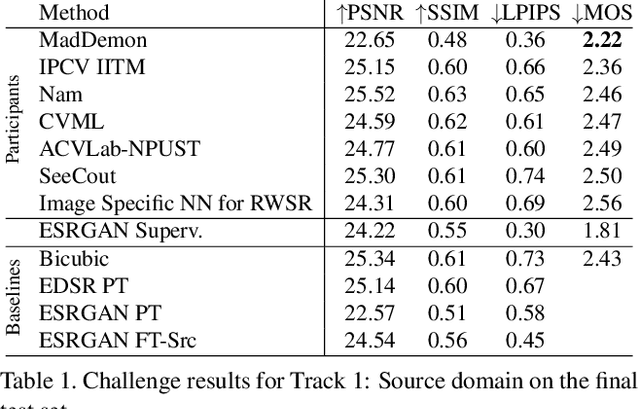
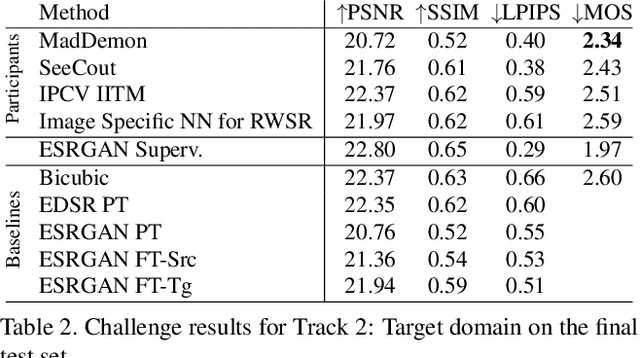

This paper reviews the AIM 2019 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided in the challenge. In Track 1: Source Domain the aim is to super-resolve such images while preserving the low level image characteristics of the source input domain. In Track 2: Target Domain a set of high-quality images is also provided for training, that defines the output domain and desired quality of the super-resolved images. To allow for quantitative evaluation, the source input images in both tracks are constructed using artificial, but realistic, image degradations. The challenge is the first of its kind, aiming to advance the state-of-the-art and provide a standard benchmark for this newly emerging task. In total 7 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Channel-wise and Spatial Feature Modulation Network for Single Image Super-Resolution
Sep 28, 2018



The performance of single image super-resolution has achieved significant improvement by utilizing deep convolutional neural networks (CNNs). The features in deep CNN contain different types of information which make different contributions to image reconstruction. However, most CNN-based models lack discriminative ability for different types of information and deal with them equally, which results in the representational capacity of the models being limited. On the other hand, as the depth of neural networks grows, the long-term information coming from preceding layers is easy to be weaken or lost in late layers, which is adverse to super-resolving image. To capture more informative features and maintain long-term information for image super-resolution, we propose a channel-wise and spatial feature modulation (CSFM) network in which a sequence of feature-modulation memory (FMM) modules is cascaded with a densely connected structure to transform low-resolution features to high informative features. In each FMM module, we construct a set of channel-wise and spatial attention residual (CSAR) blocks and stack them in a chain structure to dynamically modulate multi-level features in a global-and-local manner. This feature modulation strategy enables the high contribution information to be enhanced and the redundant information to be suppressed. Meanwhile, for long-term information persistence, a gated fusion (GF) node is attached at the end of the FMM module to adaptively fuse hierarchical features and distill more effective information via the dense skip connections and the gating mechanism. Extensive quantitative and qualitative evaluations on benchmark datasets illustrate the superiority of our proposed method over the state-of-the-art methods.
Single Image Super-Resolution via Cascaded Multi-Scale Cross Network
Feb 24, 2018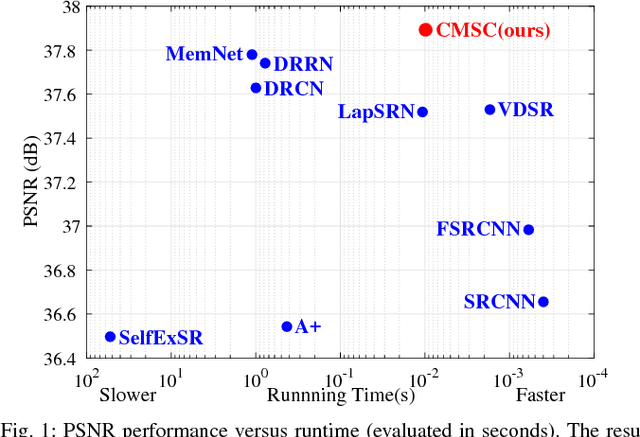

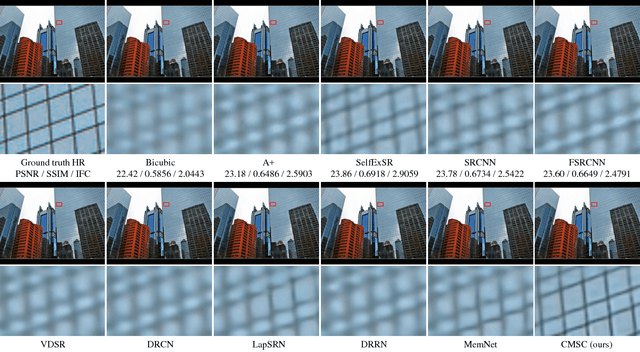
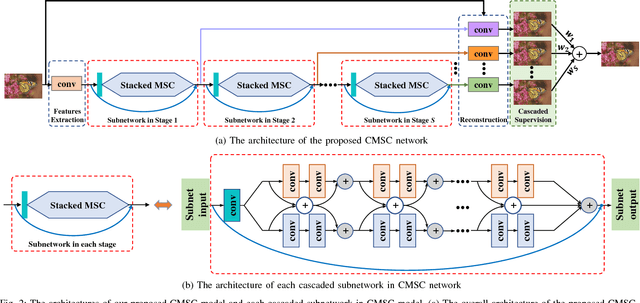
The deep convolutional neural networks have achieved significant improvements in accuracy and speed for single image super-resolution. However, as the depth of network grows, the information flow is weakened and the training becomes harder and harder. On the other hand, most of the models adopt a single-stream structure with which integrating complementary contextual information under different receptive fields is difficult. To improve information flow and to capture sufficient knowledge for reconstructing the high-frequency details, we propose a cascaded multi-scale cross network (CMSC) in which a sequence of subnetworks is cascaded to infer high resolution features in a coarse-to-fine manner. In each cascaded subnetwork, we stack multiple multi-scale cross (MSC) modules to fuse complementary multi-scale information in an efficient way as well as to improve information flow across the layers. Meanwhile, by introducing residual-features learning in each stage, the relative information between high-resolution and low-resolution features is fully utilized to further boost reconstruction performance. We train the proposed network with cascaded-supervision and then assemble the intermediate predictions of the cascade to achieve high quality image reconstruction. Extensive quantitative and qualitative evaluations on benchmark datasets illustrate the superiority of our proposed method over state-of-the-art super-resolution methods.