 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal2SAM2Real: Generative 3D Caches as Complementary Context for Video Diffusion
May 29, 2026While Video Diffusion Models (VDMs) excel at synthesizing high-fidelity videos, enabling precise camera and scene control remains challenging. Existing methods predominantly rely on implicit diffusion priors to generate unobserved regions, inevitably leading to structural collapse during high-dynamic movements or complex occlusions. To address this challenge, we propose Real2SAM2Real, a framework that leverages 3D lifting models (e.g., SAM3D) to extract an explicitly editable 3D cache, serving as a robust geometric scaffold for the VDM. By capturing the entire 3D volume of foreground entities rather than just their visible shells, this cache injects holistic spatial priors into the VDM, providing dependable 3D-aware guidance for complex scene dynamics. To effectively leverage this 3D guidance while preserving pre-trained priors, we design a Soft Spatial-Aligned Injection mechanism alongside a minimally invasive fine-tuning strategy tailored for VDMs. Furthermore, we employ masked normal maps as a cross-modal bridge to construct a 3D-free data curation and perturbation pipeline. Extensive experiments demonstrate that Real2SAM2Real enables precise, decoupled control over both camera trajectories and multi-entity motions. By utilizing the complementary context from generative 3D caches, our framework overcomes typical breakdowns caused by over-reliance on diffusion priors, maintaining exceptional spatiotemporal consistency under large camera shifts and severe occlusions. Crucially, by decoupling geometry from appearance, our VDM-tailored 3D cache eradicates perspective ambiguities caused by structural holes and erroneous facades, as well as misleading cues from reflections and refractions. Project website is available at https://jiayi-wu-leo.github.io/real2sam2real
Parametric Shadow Control for Portrait Generationin Text-to-Image Diffusion Models
Mar 27, 2025Text-to-image diffusion models excel at generating diverse portraits, but lack intuitive shadow control. Existing editing approaches, as post-processing, struggle to offer effective manipulation across diverse styles. Additionally, these methods either rely on expensive real-world light-stage data collection or require extensive computational resources for training. To address these limitations, we introduce Shadow Director, a method that extracts and manipulates hidden shadow attributes within well-trained diffusion models. Our approach uses a small estimation network that requires only a few thousand synthetic images and hours of training-no costly real-world light-stage data needed. Shadow Director enables parametric and intuitive control over shadow shape, placement, and intensity during portrait generation while preserving artistic integrity and identity across diverse styles. Despite training only on synthetic data built on real-world identities, it generalizes effectively to generated portraits with diverse styles, making it a more accessible and resource-friendly solution.
Flash-Split: 2D Reflection Removal with Flash Cues and Latent Diffusion Separation
Dec 31, 2024



Transparent surfaces, such as glass, create complex reflections that obscure images and challenge downstream computer vision applications. We introduce Flash-Split, a robust framework for separating transmitted and reflected light using a single (potentially misaligned) pair of flash/no-flash images. Our core idea is to perform latent-space reflection separation while leveraging the flash cues. Specifically, Flash-Split consists of two stages. Stage 1 separates apart the reflection latent and transmission latent via a dual-branch diffusion model conditioned on an encoded flash/no-flash latent pair, effectively mitigating the flash/no-flash misalignment issue. Stage 2 restores high-resolution, faithful details to the separated latents, via a cross-latent decoding process conditioned on the original images before separation. By validating Flash-Split on challenging real-world scenes, we demonstrate state-of-the-art reflection separation performance and significantly outperform the baseline methods.
Repurposing Pre-trained Video Diffusion Models for Event-based Video Interpolation
Dec 10, 2024



Video Frame Interpolation aims to recover realistic missing frames between observed frames, generating a high-frame-rate video from a low-frame-rate video. However, without additional guidance, the large motion between frames makes this problem ill-posed. Event-based Video Frame Interpolation (EVFI) addresses this challenge by using sparse, high-temporal-resolution event measurements as motion guidance. This guidance allows EVFI methods to significantly outperform frame-only methods. However, to date, EVFI methods have relied on a limited set of paired event-frame training data, severely limiting their performance and generalization capabilities. In this work, we overcome the limited data challenge by adapting pre-trained video diffusion models trained on internet-scale datasets to EVFI. We experimentally validate our approach on real-world EVFI datasets, including a new one that we introduce. Our method outperforms existing methods and generalizes across cameras far better than existing approaches.
Flash-Splat: 3D Reflection Removal with Flash Cues and Gaussian Splats
Oct 03, 2024We introduce a simple yet effective approach for separating transmitted and reflected light. Our key insight is that the powerful novel view synthesis capabilities provided by modern inverse rendering methods (e.g.,~3D Gaussian splatting) allow one to perform flash/no-flash reflection separation using unpaired measurements -- this relaxation dramatically simplifies image acquisition over conventional paired flash/no-flash reflection separation methods. Through extensive real-world experiments, we demonstrate our method, Flash-Splat, accurately reconstructs both transmitted and reflected scenes in 3D. Our method outperforms existing 3D reflection separation methods, which do not leverage illumination control, by a large margin. Our project webpage is at https://flash-splat.github.io/.
CodedEvents: Optimal Point-Spread-Function Engineering for 3D-Tracking with Event Cameras
Jun 13, 2024



Point-spread-function (PSF) engineering is a well-established computational imaging technique that uses phase masks and other optical elements to embed extra information (e.g., depth) into the images captured by conventional CMOS image sensors. To date, however, PSF-engineering has not been applied to neuromorphic event cameras; a powerful new image sensing technology that responds to changes in the log-intensity of light. This paper establishes theoretical limits (Cram\'er Rao bounds) on 3D point localization and tracking with PSF-engineered event cameras. Using these bounds, we first demonstrate that existing Fisher phase masks are already near-optimal for localizing static flashing point sources (e.g., blinking fluorescent molecules). We then demonstrate that existing designs are sub-optimal for tracking moving point sources and proceed to use our theory to design optimal phase masks and binary amplitude masks for this task. To overcome the non-convexity of the design problem, we leverage novel implicit neural representation based parameterizations of the phase and amplitude masks. We demonstrate the efficacy of our designs through extensive simulations. We also validate our method with a simple prototype.
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Mar 20, 2024



This paper addresses the novel challenge of ``rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively ``rewind'' time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.
ConVRT: Consistent Video Restoration Through Turbulence with Test-time Optimization of Neural Video Representations
Dec 07, 2023



tmospheric turbulence presents a significant challenge in long-range imaging. Current restoration algorithms often struggle with temporal inconsistency, as well as limited generalization ability across varying turbulence levels and scene content different than the training data. To tackle these issues, we introduce a self-supervised method, Consistent Video Restoration through Turbulence (ConVRT) a test-time optimization method featuring a neural video representation designed to enhance temporal consistency in restoration. A key innovation of ConVRT is the integration of a pretrained vision-language model (CLIP) for semantic-oriented supervision, which steers the restoration towards sharp, photorealistic images in the CLIP latent space. We further develop a principled selection strategy of text prompts, based on their statistical correlation with a perceptual metric. ConVRT's test-time optimization allows it to adapt to a wide range of real-world turbulence conditions, effectively leveraging the insights gained from pre-trained models on simulated data. ConVRT offers a comprehensive and effective solution for mitigating real-world turbulence in dynamic videos.
Assessor360: Multi-sequence Network for Blind Omnidirectional Image Quality Assessment
May 24, 2023Blind Omnidirectional Image Quality Assessment (BOIQA) aims to objectively assess the human perceptual quality of omnidirectional images (ODIs) without relying on pristine-quality image information. It is becoming more significant with the increasing advancement of virtual reality (VR) technology. However, the quality assessment of ODIs is severely hampered by the fact that the existing BOIQA pipeline lacks the modeling of the observer's browsing process. To tackle this issue, we propose a novel multi-sequence network for BOIQA called Assessor360, which is derived from the realistic multi-assessor ODI quality assessment procedure. Specifically, we propose a generalized Recursive Probability Sampling (RPS) method for the BOIQA task, combining content and detailed information to generate multiple pseudo viewport sequences from a given starting point. Additionally, we design a Multi-scale Feature Aggregation (MFA) module with Distortion-aware Block (DAB) to fuse distorted and semantic features of each viewport. We also devise TMM to learn the viewport transition in the temporal domain. Extensive experimental results demonstrate that Assessor360 outperforms state-of-the-art methods on multiple OIQA datasets.
Efficient Image Super-Resolution using Vast-Receptive-Field Attention
Oct 12, 2022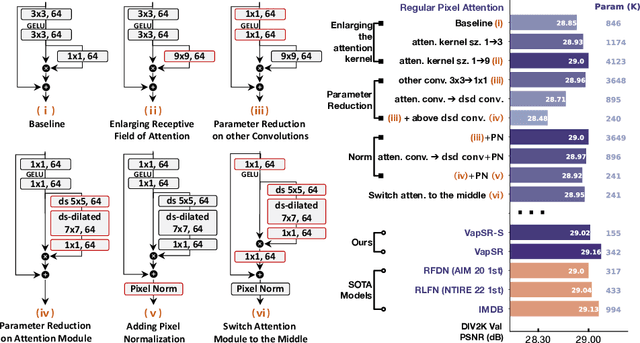
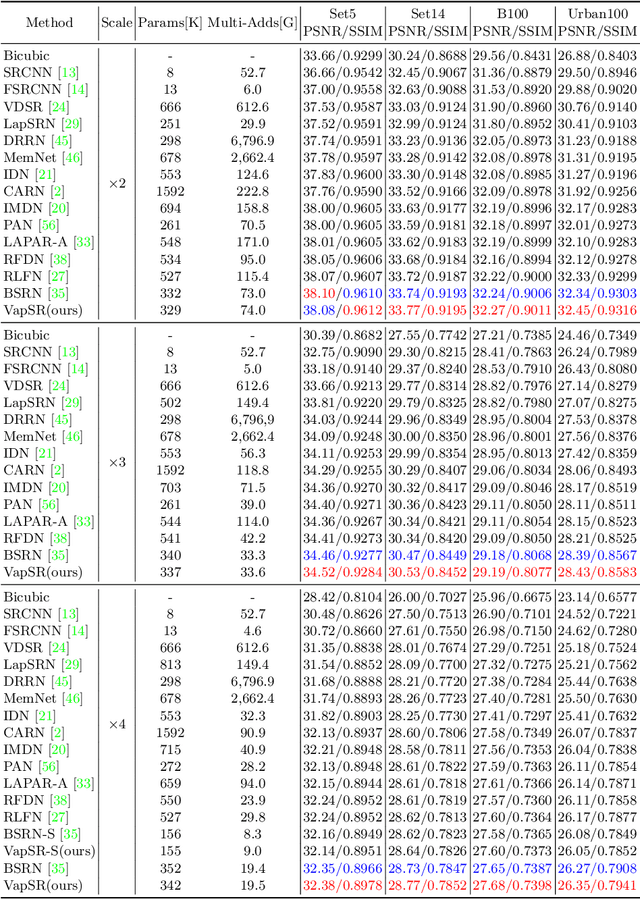
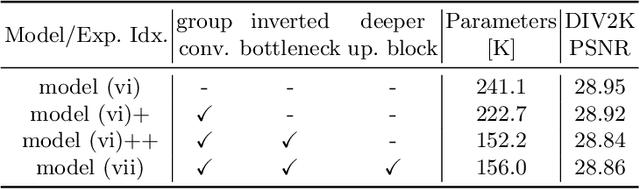
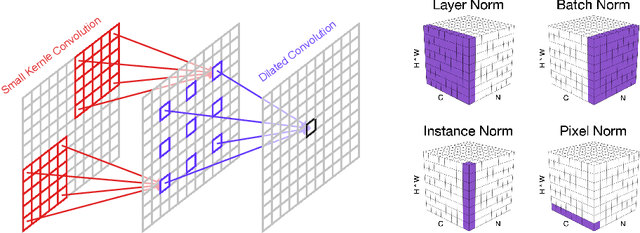
The attention mechanism plays a pivotal role in designing advanced super-resolution (SR) networks. In this work, we design an efficient SR network by improving the attention mechanism. We start from a simple pixel attention module and gradually modify it to achieve better super-resolution performance with reduced parameters. The specific approaches include: (1) increasing the receptive field of the attention branch, (2) replacing large dense convolution kernels with depth-wise separable convolutions, and (3) introducing pixel normalization. These approaches paint a clear evolutionary roadmap for the design of attention mechanisms. Based on these observations, we propose VapSR, the VAst-receptive-field Pixel attention network. Experiments demonstrate the superior performance of VapSR. VapSR outperforms the present lightweight networks with even fewer parameters. And the light version of VapSR can use only 21.68% and 28.18% parameters of IMDB and RFDN to achieve similar performances to those networks. The code and models are available at url{https://github.com/zhoumumu/VapSR.