 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLMs on the Massive Sound Embedding Benchmark (MSEB)
May 06, 2026The Massive Sound Embedding Benchmark (MSEB) has emerged as a standard for evaluating the functional breadth of audio models. While initial baselines focused on specialized encoders, the shift toward "audio-native" Large Language Models (LLMs) suggests a new paradigm where a single multimodal backbone may replace complex, task-specific pipelines. This paper provides a rigorous empirical evaluation of leading LLMs - including members from the Gemini and GPT families - across the eight core MSEB capabilities to assess their efficacy and audio-text parity. Our results indicate that while a significant modality gap persists regarding performance and robustness, the empirical evidence for an "optimal" modeling approach remains inconclusive. Ultimately, the choice between audionative and cascaded architectures depends heavily on specific use-case requirements and the underlying assumptions regarding latency, cost, and reasoning depth.
Massive Sound Embedding Benchmark (MSEB)
Feb 06, 2026Audio is a critical component of multimodal perception, and any truly intelligent system must demonstrate a wide range of auditory capabilities. These capabilities include transcription, classification, retrieval, reasoning, segmentation, clustering, reranking, and reconstruction. Fundamentally, each task involves transforming a raw audio signal into a meaningful 'embedding' - be it a single vector, a sequence of continuous or discrete representations, or another structured form - which then serves as the basis for generating the task's final response. To accelerate progress towards robust machine auditory intelligence, we present the Massive Sound Embedding Benchmark (MSEB): an extensible framework designed to evaluate the auditory components of any multimodal system. In its first release, MSEB offers a comprehensive suite of eight core tasks, with more planned for the future, supported by diverse datasets, including the new, large-scale Simple Voice Questions (SVQ) dataset. Our initial experiments establish clear performance headrooms, highlighting the significant opportunity to improve real-world multimodal experiences where audio is a core signal. We encourage the research community to use MSEB to assess their algorithms and contribute to its growth. The library is publicly hosted at github.
LAST: Scalable Lattice-Based Speech Modelling in JAX
Apr 25, 2023We introduce LAST, a LAttice-based Speech Transducer library in JAX. With an emphasis on flexibility, ease-of-use, and scalability, LAST implements differentiable weighted finite state automaton (WFSA) algorithms needed for training \& inference that scale to a large WFSA such as a recognition lattice over the entire utterance. Despite these WFSA algorithms being well-known in the literature, new challenges arise from performance characteristics of modern architectures, and from nuances in automatic differentiation. We describe a suite of generally applicable techniques employed in LAST to address these challenges, and demonstrate their effectiveness with benchmarks on TPUv3 and V100 GPU.
JEIT: Joint End-to-End Model and Internal Language Model Training for Speech Recognition
Feb 16, 2023



We propose JEIT, a joint end-to-end (E2E) model and internal language model (ILM) training method to inject large-scale unpaired text into ILM during E2E training which improves rare-word speech recognition. With JEIT, the E2E model computes an E2E loss on audio-transcript pairs while its ILM estimates a cross-entropy loss on unpaired text. The E2E model is trained to minimize a weighted sum of E2E and ILM losses. During JEIT, ILM absorbs knowledge from unpaired text while the E2E training serves as regularization. Unlike ILM adaptation methods, JEIT does not require a separate adaptation step and avoids the need for Kullback-Leibler divergence regularization of ILM. We also show that modular hybrid autoregressive transducer (MHAT) performs better than HAT in the JEIT framework, and is much more robust than HAT during ILM adaptation. To push the limit of unpaired text injection, we further propose a combined JEIT and JOIST training (CJJT) that benefits from modality matching, encoder text injection and ILM training. Both JEIT and CJJT can foster a more effective LM fusion. With 100B unpaired sentences, JEIT/CJJT improves rare-word recognition accuracy by up to 16.4% over a model trained without unpaired text.
* 5 pages, 3 figures, in ICASSP 2023
Alignment Entropy Regularization
Dec 22, 2022



Existing training criteria in automatic speech recognition(ASR) permit the model to freely explore more than one time alignments between the feature and label sequences. In this paper, we use entropy to measure a model's uncertainty, i.e. how it chooses to distribute the probability mass over the set of allowed alignments. Furthermore, we evaluate the effect of entropy regularization in encouraging the model to distribute the probability mass only on a smaller subset of allowed alignments. Experiments show that entropy regularization enables a much simpler decoding method without sacrificing word error rate, and provides better time alignment quality.
Modular Hybrid Autoregressive Transducer
Oct 31, 2022



Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
UserLibri: A Dataset for ASR Personalization Using Only Text
Jul 02, 2022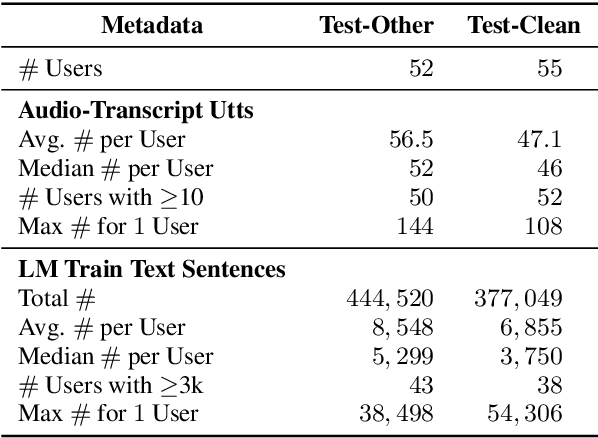
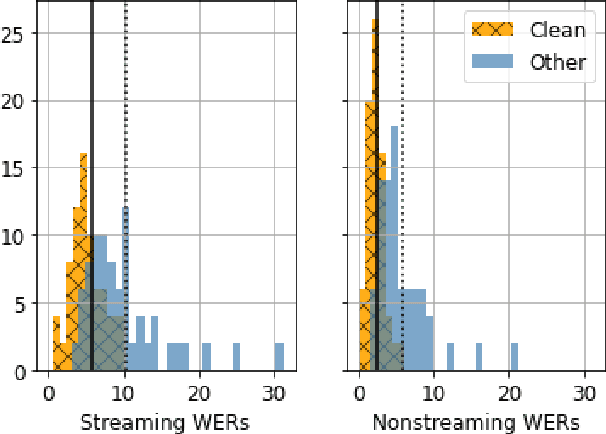
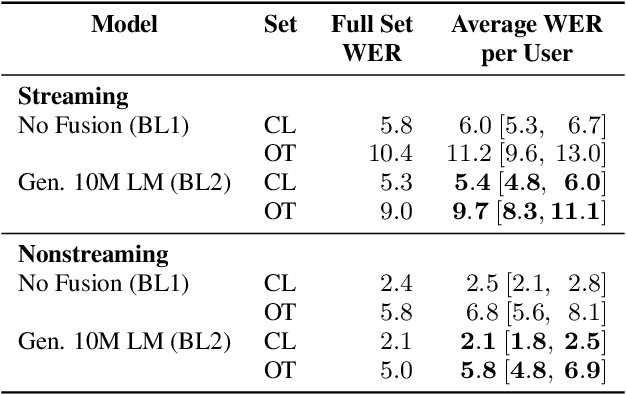
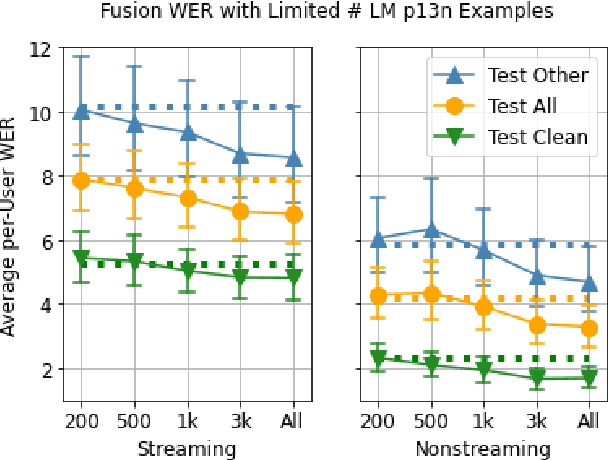
Personalization of speech models on mobile devices (on-device personalization) is an active area of research, but more often than not, mobile devices have more text-only data than paired audio-text data. We explore training a personalized language model on text-only data, used during inference to improve speech recognition performance for that user. We experiment on a user-clustered LibriSpeech corpus, supplemented with personalized text-only data for each user from Project Gutenberg. We release this User-Specific LibriSpeech (UserLibri) dataset to aid future personalization research. LibriSpeech audio-transcript pairs are grouped into 55 users from the test-clean dataset and 52 users from test-other. We are able to lower the average word error rate per user across both sets in streaming and nonstreaming models, including an improvement of 2.5 for the harder set of test-other users when streaming.
Global Normalization for Streaming Speech Recognition in a Modular Framework
May 26, 2022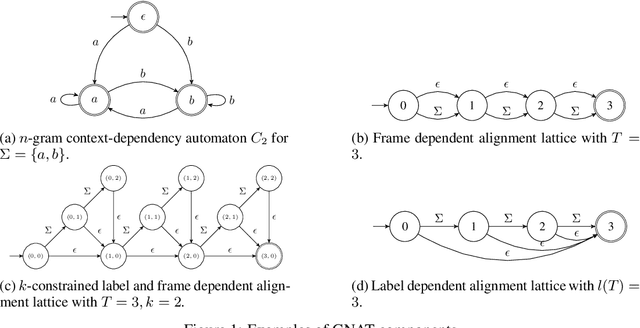
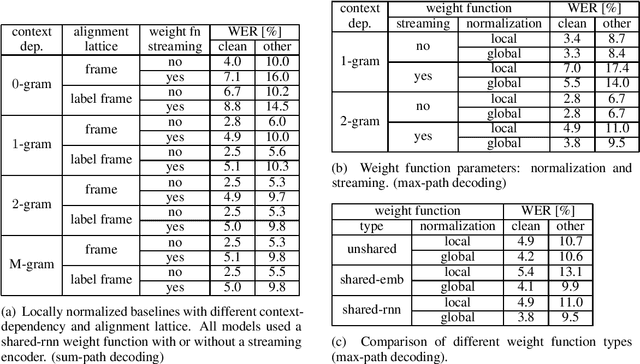
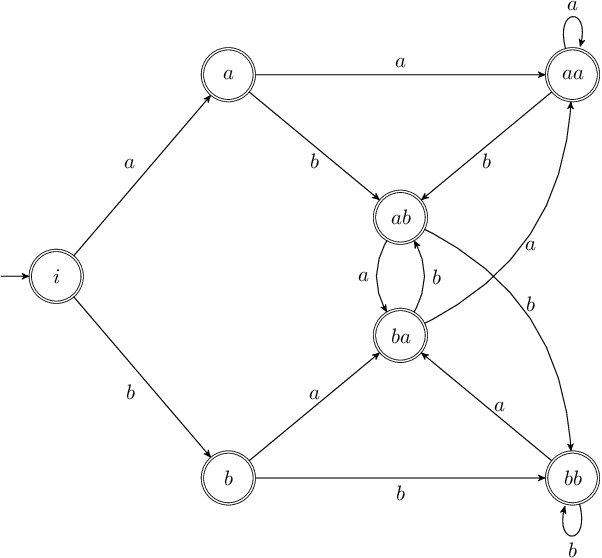
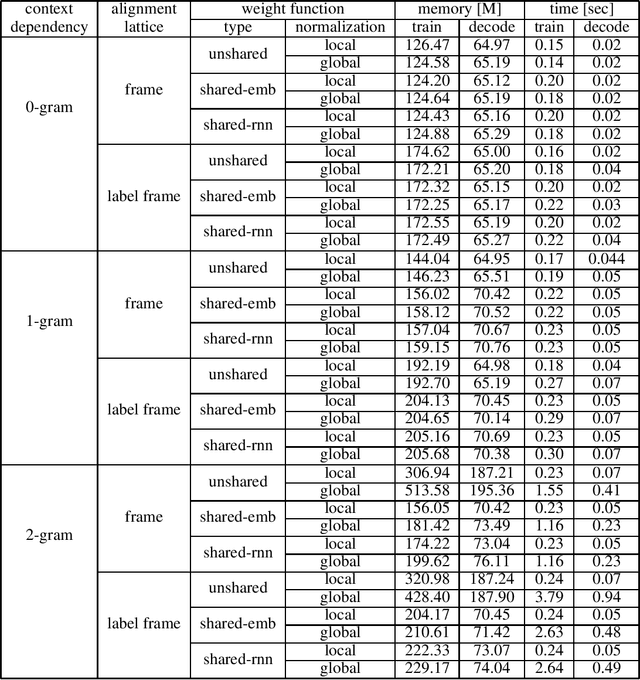
We introduce the Globally Normalized Autoregressive Transducer (GNAT) for addressing the label bias problem in streaming speech recognition. Our solution admits a tractable exact computation of the denominator for the sequence-level normalization. Through theoretical and empirical results, we demonstrate that by switching to a globally normalized model, the word error rate gap between streaming and non-streaming speech-recognition models can be greatly reduced (by more than 50\% on the Librispeech dataset). This model is developed in a modular framework which encompasses all the common neural speech recognition models. The modularity of this framework enables controlled comparison of modelling choices and creation of new models.
Improving Rare Word Recognition with LM-aware MWER Training
Apr 15, 2022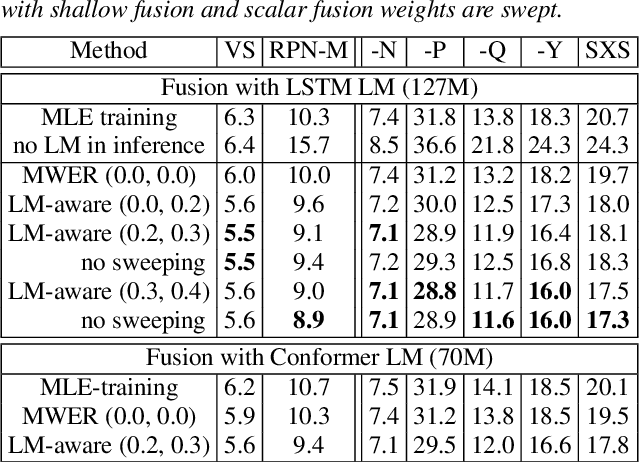
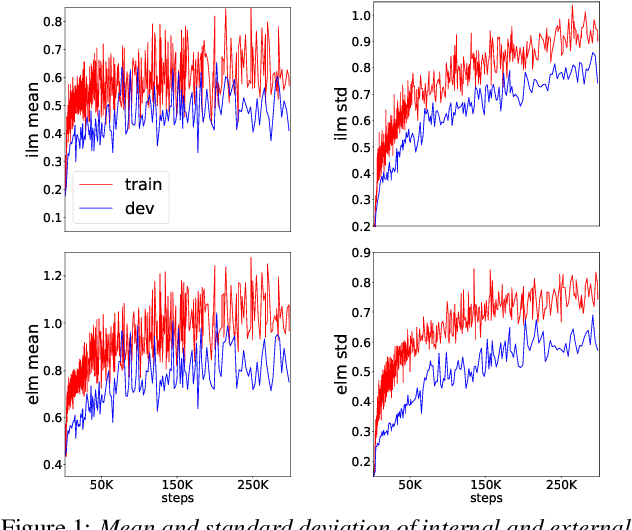

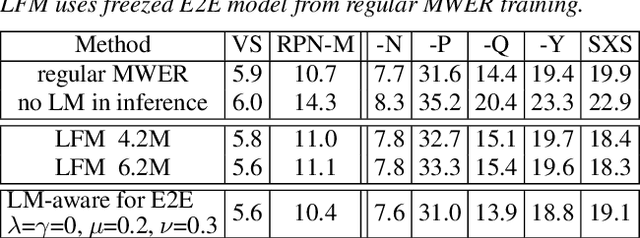
Language models (LMs) significantly improve the recognition accuracy of end-to-end (E2E) models on words rarely seen during training, when used in either the shallow fusion or the rescoring setups. In this work, we introduce LMs in the learning of hybrid autoregressive transducer (HAT) models in the discriminative training framework, to mitigate the training versus inference gap regarding the use of LMs. For the shallow fusion setup, we use LMs during both hypotheses generation and loss computation, and the LM-aware MWER-trained model achieves 10\% relative improvement over the model trained with standard MWER on voice search test sets containing rare words. For the rescoring setup, we learn a small neural module to generate per-token fusion weights in a data-dependent manner. This model achieves the same rescoring WER as regular MWER-trained model, but without the need for sweeping fusion weights.
Cascaded encoders for unifying streaming and non-streaming ASR
Oct 27, 2020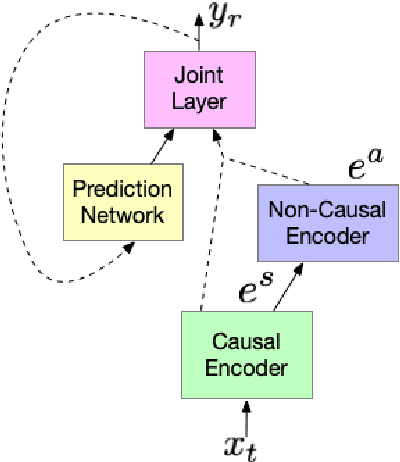
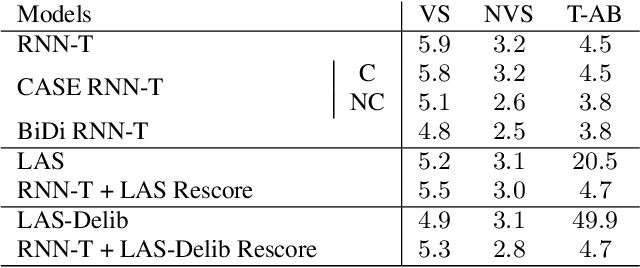
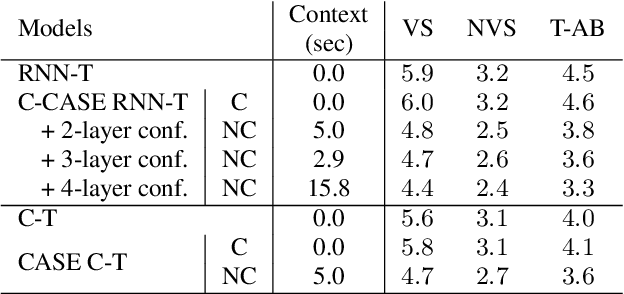
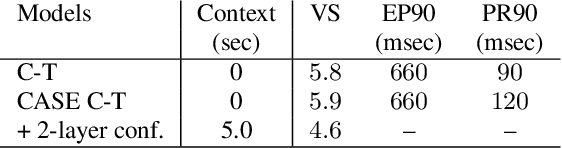
End-to-end (E2E) automatic speech recognition (ASR) models, by now, have shown competitive performance on several benchmarks. These models are structured to either operate in streaming or non-streaming mode. This work presents cascaded encoders for building a single E2E ASR model that can operate in both these modes simultaneously. The proposed model consists of streaming and non-streaming encoders. Input features are first processed by the streaming encoder; the non-streaming encoder operates exclusively on the output of the streaming encoder. A single decoder then learns to decode either using the output of the streaming or the non-streaming encoder. Results show that this model achieves similar word error rates (WER) as a standalone streaming model when operating in streaming mode, and obtains 10% -- 27% relative improvement when operating in non-streaming mode. Our results also show that the proposed approach outperforms existing E2E two-pass models, especially on long-form speech.