 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Fast and Memory-Efficient Network Towards Efficient Image Super-Resolution
Apr 18, 2022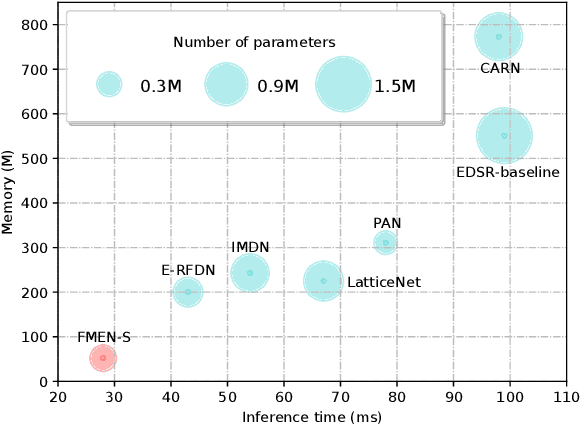

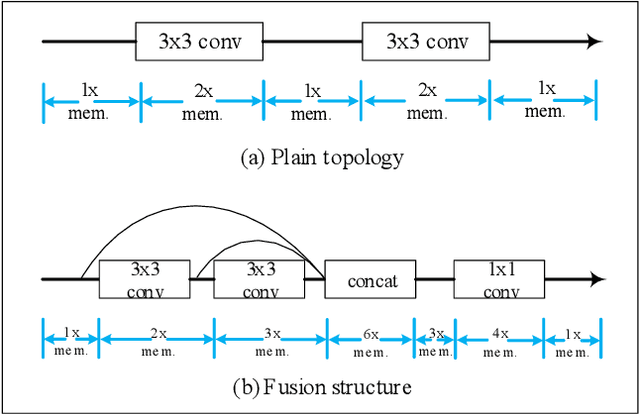
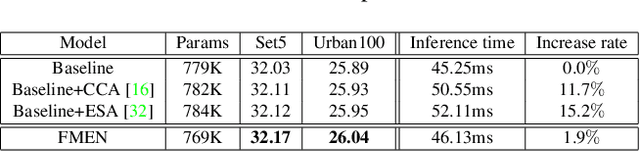
Runtime and memory consumption are two important aspects for efficient image super-resolution (EISR) models to be deployed on resource-constrained devices. Recent advances in EISR exploit distillation and aggregation strategies with plenty of channel split and concatenation operations to make full use of limited hierarchical features. In contrast, sequential network operations avoid frequently accessing preceding states and extra nodes, and thus are beneficial to reducing the memory consumption and runtime overhead. Following this idea, we design our lightweight network backbone by mainly stacking multiple highly optimized convolution and activation layers and decreasing the usage of feature fusion. We propose a novel sequential attention branch, where every pixel is assigned an important factor according to local and global contexts, to enhance high-frequency details. In addition, we tailor the residual block for EISR and propose an enhanced residual block (ERB) to further accelerate the network inference. Finally, combining all the above techniques, we construct a fast and memory-efficient network (FMEN) and its small version FMEN-S, which runs 33% faster and reduces 74% memory consumption compared with the state-of-the-art EISR model: E-RFDN, the champion in AIM 2020 efficient super-resolution challenge. Besides, FMEN-S achieves the lowest memory consumption and the second shortest runtime in NTIRE 2022 challenge on efficient super-resolution. Code is available at https://github.com/NJU-Jet/FMEN.
Anchor-based Plain Net for Mobile Image Super-Resolution
May 20, 2021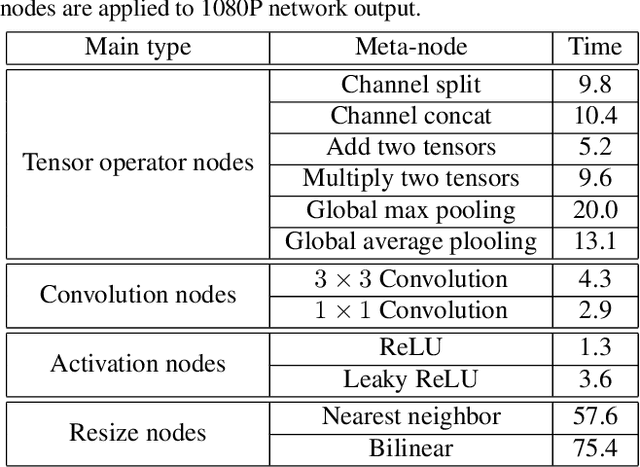
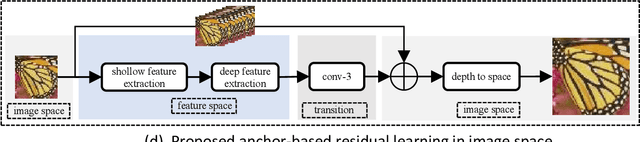
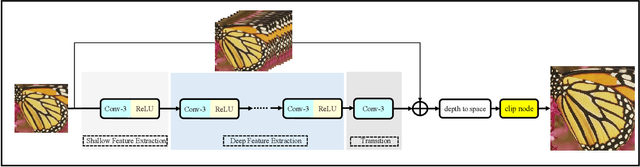
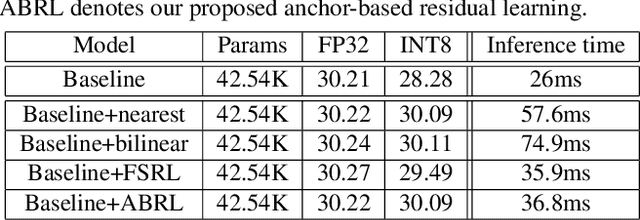
Along with the rapid development of real-world applications, higher requirements on the accuracy and efficiency of image super-resolution (SR) are brought forward. Though existing methods have achieved remarkable success, the majority of them demand plenty of computational resources and large amount of RAM, and thus they can not be well applied to mobile device. In this paper, we aim at designing efficient architecture for 8-bit quantization and deploy it on mobile device. First, we conduct an experiment about meta-node latency by decomposing lightweight SR architectures, which determines the portable operations we can utilize. Then, we dig deeper into what kind of architecture is beneficial to 8-bit quantization and propose anchor-based plain net (ABPN). Finally, we adopt quantization-aware training strategy to further boost the performance. Our model can outperform 8-bit quantized FSRCNN by nearly 2dB in terms of PSNR, while satisfying realistic needs at the same time. Code is avaliable at https://github.com/NJU- Jet/SR_Mobile_Quantization.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
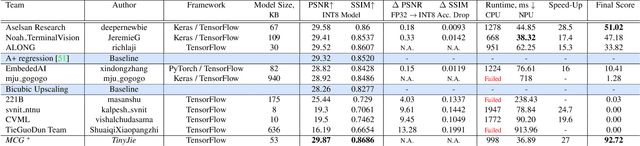
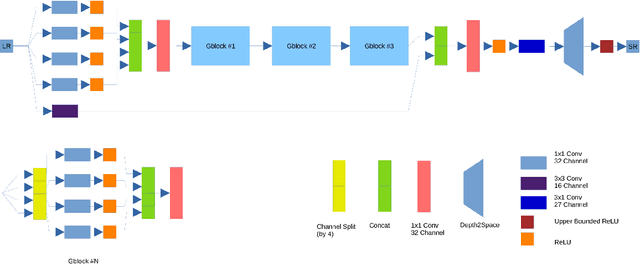
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.