 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetectiveQA: Evaluating Long-Context Reasoning on Detective Novels
Sep 04, 2024



With the rapid advancement of Large Language Models (LLMs), long-context information understanding and processing have become a hot topic in academia and industry. However, benchmarks for evaluating the ability of LLMs to handle long-context information do not seem to have kept pace with the development of LLMs. Despite the emergence of various long-context evaluation benchmarks, the types of capability assessed are still limited, without new capability dimensions. In this paper, we introduce DetectiveQA, a narrative reasoning benchmark featured with an average context length of over 100K tokens. DetectiveQA focuses on evaluating the long-context reasoning ability of LLMs, which not only requires a full understanding of context but also requires extracting important evidences from the context and reasoning according to extracted evidences to answer the given questions. This is a new dimension of capability evaluation, which is more in line with the current intelligence level of LLMs. We use detective novels as data sources, which naturally have various reasoning elements. Finally, we manually annotated 600 questions in Chinese and then also provided an English edition of the context information and questions. We evaluate many long-context LLMs on DetectiveQA, including commercial and open-sourced models, and the results indicate that existing long-context LLMs still require significant advancements to effectively process true long-context dependency questions.
Can AI Assistants Know What They Don't Know?
Jan 28, 2024



Recently, AI assistants based on large language models (LLMs) show surprising performance in many tasks, such as dialogue, solving math problems, writing code, and using tools. Although LLMs possess intensive world knowledge, they still make factual errors when facing some knowledge intensive tasks, like open-domain question answering. These untruthful responses from the AI assistant may cause significant risks in practical applications. We believe that an AI assistant's refusal to answer questions it does not know is a crucial method for reducing hallucinations and making the assistant truthful. Therefore, in this paper, we ask the question "Can AI assistants know what they don't know and express them through natural language?" To answer this question, we construct a model-specific "I don't know" (Idk) dataset for an assistant, which contains its known and unknown questions, based on existing open-domain question answering datasets. Then we align the assistant with its corresponding Idk dataset and observe whether it can refuse to answer its unknown questions after alignment. Experimental results show that after alignment with Idk datasets, the assistant can refuse to answer most its unknown questions. For questions they attempt to answer, the accuracy is significantly higher than before the alignment.
Flames: Benchmarking Value Alignment of Chinese Large Language Models
Nov 12, 2023



The widespread adoption of large language models (LLMs) across various regions underscores the urgent need to evaluate their alignment with human values. Current benchmarks, however, fall short of effectively uncovering safety vulnerabilities in LLMs. Despite numerous models achieving high scores and 'topping the chart' in these evaluations, there is still a significant gap in LLMs' deeper alignment with human values and achieving genuine harmlessness. To this end, this paper proposes the first highly adversarial benchmark named Flames, consisting of 2,251 manually crafted prompts, ~18.7K model responses with fine-grained annotations, and a specified scorer. Our framework encompasses both common harmlessness principles, such as fairness, safety, legality, and data protection, and a unique morality dimension that integrates specific Chinese values such as harmony. Based on the framework, we carefully design adversarial prompts that incorporate complex scenarios and jailbreaking methods, mostly with implicit malice. By prompting mainstream LLMs with such adversarially constructed prompts, we obtain model responses, which are then rigorously annotated for evaluation. Our findings indicate that all the evaluated LLMs demonstrate relatively poor performance on Flames, particularly in the safety and fairness dimensions. Claude emerges as the best-performing model overall, but with its harmless rate being only 63.08% while GPT-4 only scores 39.04%. The complexity of Flames has far exceeded existing benchmarks, setting a new challenge for contemporary LLMs and highlighting the need for further alignment of LLMs. To efficiently evaluate new models on the benchmark, we develop a specified scorer capable of scoring LLMs across multiple dimensions, achieving an accuracy of 77.4%. The Flames Benchmark is publicly available on https://github.com/AIFlames/Flames.
Evaluating Hallucinations in Chinese Large Language Models
Oct 05, 2023



In this paper, we establish a benchmark named HalluQA (Chinese Hallucination Question-Answering) to measure the hallucination phenomenon in Chinese large language models. HalluQA contains 450 meticulously designed adversarial questions, spanning multiple domains, and takes into account Chinese historical culture, customs, and social phenomena. During the construction of HalluQA, we consider two types of hallucinations: imitative falsehoods and factual errors, and we construct adversarial samples based on GLM-130B and ChatGPT. For evaluation, we design an automated evaluation method using GPT-4 to judge whether a model output is hallucinated. We conduct extensive experiments on 24 large language models, including ERNIE-Bot, Baichuan2, ChatGLM, Qwen, SparkDesk and etc. Out of the 24 models, 18 achieved non-hallucination rates lower than 50%. This indicates that HalluQA is highly challenging. We analyze the primary types of hallucinations in different types of models and their causes. Additionally, we discuss which types of hallucinations should be prioritized for different types of models.
The Rise and Potential of Large Language Model Based Agents: A Survey
Sep 19, 2023



For a long time, humanity has pursued artificial intelligence (AI) equivalent to or surpassing the human level, with AI agents considered a promising vehicle for this pursuit. AI agents are artificial entities that sense their environment, make decisions, and take actions. Many efforts have been made to develop intelligent agents, but they mainly focus on advancement in algorithms or training strategies to enhance specific capabilities or performance on particular tasks. Actually, what the community lacks is a general and powerful model to serve as a starting point for designing AI agents that can adapt to diverse scenarios. Due to the versatile capabilities they demonstrate, large language models (LLMs) are regarded as potential sparks for Artificial General Intelligence (AGI), offering hope for building general AI agents. Many researchers have leveraged LLMs as the foundation to build AI agents and have achieved significant progress. In this paper, we perform a comprehensive survey on LLM-based agents. We start by tracing the concept of agents from its philosophical origins to its development in AI, and explain why LLMs are suitable foundations for agents. Building upon this, we present a general framework for LLM-based agents, comprising three main components: brain, perception, and action, and the framework can be tailored for different applications. Subsequently, we explore the extensive applications of LLM-based agents in three aspects: single-agent scenarios, multi-agent scenarios, and human-agent cooperation. Following this, we delve into agent societies, exploring the behavior and personality of LLM-based agents, the social phenomena that emerge from an agent society, and the insights they offer for human society. Finally, we discuss several key topics and open problems within the field. A repository for the related papers at https://github.com/WooooDyy/LLM-Agent-Paper-List.
Federated Prompting and Chain-of-Thought Reasoning for Improving LLMs Answering
Apr 27, 2023



We investigate how to enhance answer precision in frequently asked questions posed by distributed users using cloud-based Large Language Models (LLMs). Our study focuses on a typical situations where users ask similar queries that involve identical mathematical reasoning steps and problem-solving procedures. Due to the unsatisfactory accuracy of LLMs' zero-shot prompting with standalone questions, we propose to improve the distributed synonymous questions using Self-Consistency (SC) and Chain-of-Thought (CoT) techniques. Specifically, we first retrieve synonymous questions from a crowd-sourced database and create a federated question pool. We call these federated synonymous questions with the same or different parameters SP-questions or DP-questions, respectively. We refer to our methods as Fed-SP-SC and Fed-DP-CoT, which can generate significantly more accurate answers for all user queries without requiring sophisticated model-tuning. Through extensive experiments, we demonstrate that our proposed methods can significantly enhance question accuracy by fully exploring the synonymous nature of the questions and the consistency of the answers.
OmniForce: On Human-Centered, Large Model Empowered and Cloud-Edge Collaborative AutoML System
Mar 01, 2023



Automated machine learning (AutoML) seeks to build ML models with minimal human effort. While considerable research has been conducted in the area of AutoML in general, aiming to take humans out of the loop when building artificial intelligence (AI) applications, scant literature has focused on how AutoML works well in open-environment scenarios such as the process of training and updating large models, industrial supply chains or the industrial metaverse, where people often face open-loop problems during the search process: they must continuously collect data, update data and models, satisfy the requirements of the development and deployment environment, support massive devices, modify evaluation metrics, etc. Addressing the open-environment issue with pure data-driven approaches requires considerable data, computing resources, and effort from dedicated data engineers, making current AutoML systems and platforms inefficient and computationally intractable. Human-computer interaction is a practical and feasible way to tackle the problem of open-environment AI. In this paper, we introduce OmniForce, a human-centered AutoML (HAML) system that yields both human-assisted ML and ML-assisted human techniques, to put an AutoML system into practice and build adaptive AI in open-environment scenarios. Specifically, we present OmniForce in terms of ML version management; pipeline-driven development and deployment collaborations; a flexible search strategy framework; and widely provisioned and crowdsourced application algorithms, including large models. Furthermore, the (large) models constructed by OmniForce can be automatically turned into remote services in a few minutes; this process is dubbed model as a service (MaaS). Experimental results obtained in multiple search spaces and real-world use cases demonstrate the efficacy and efficiency of OmniForce.
Late Prompt Tuning: A Late Prompt Could Be Better Than Many Prompts
Oct 20, 2022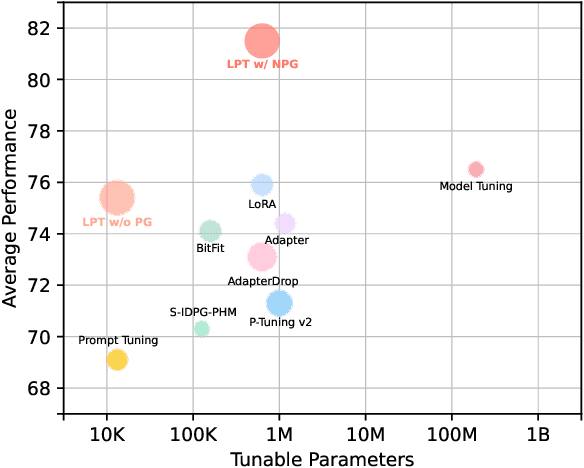
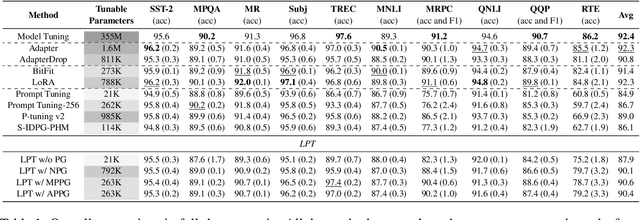
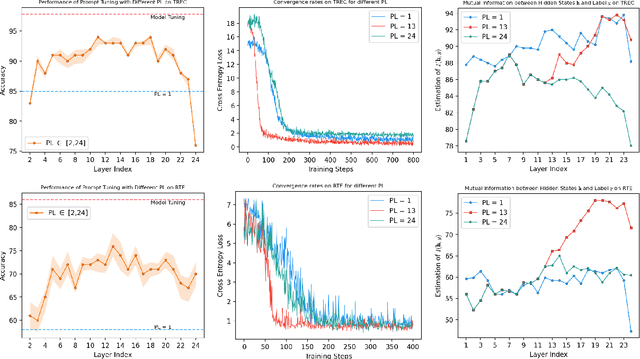
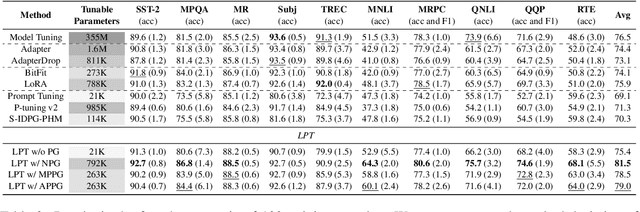
Prompt tuning is a parameter-efficient tuning (PETuning) method for utilizing pre-trained models (PTMs) that simply prepends a soft prompt to the input and only optimizes the prompt to adapt PTMs to downstream tasks. Although it is parameter- and deployment-efficient, its performance still lags behind other state-of-the-art PETuning methods. Besides, the training cost of prompt tuning is not significantly reduced due to the back-propagation through the entire model. Through empirical analyses, we shed some light on the lagging performance of prompt tuning and recognize a trade-off between the propagation distance from label signals to the inserted prompt and the influence of the prompt on model outputs. Further, we present Late Prompt Tuning (LPT) that inserts a late prompt into an intermediate layer of the PTM instead of the input layer or all layers. The late prompt is obtained by a neural prompt generator conditioned on the hidden states before the prompt insertion layer and therefore is instance-dependent. Through extensive experimental results across various tasks and PTMs, we show that LPT can achieve competitive performance to full model tuning and other PETuning methods under both full-data and few-shot scenarios while possessing faster training speed and lower memory cost.
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
Mar 03, 2022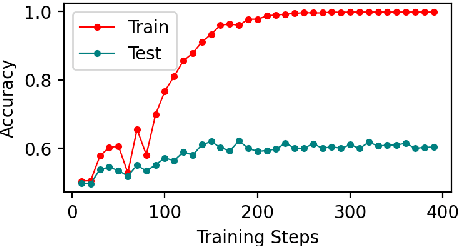
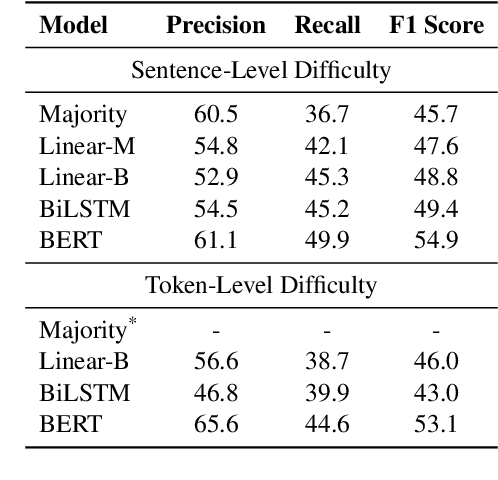
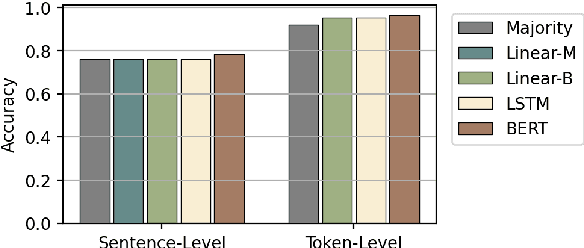
Early exiting allows instances to exit at different layers according to the estimation of difficulty. Previous works usually adopt heuristic metrics such as the entropy of internal outputs to measure instance difficulty, which suffers from generalization and threshold-tuning. In contrast, learning to exit, or learning to predict instance difficulty is a more appealing way. Though some effort has been devoted to employing such "learn-to-exit" modules, it is still unknown whether and how well the instance difficulty can be learned. As a response, we first conduct experiments on the learnability of instance difficulty, which demonstrates that modern neural models perform poorly on predicting instance difficulty. Based on this observation, we propose a simple-yet-effective Hash-based Early Exiting approach (HashEE) that replaces the learn-to-exit modules with hash functions to assign each token to a fixed exiting layer. Different from previous methods, HashEE requires no internal classifiers nor extra parameters, and therefore is more efficient. Experimental results on classification, regression, and generation tasks demonstrate that HashEE can achieve higher performance with fewer FLOPs and inference time compared with previous state-of-the-art early exiting methods.
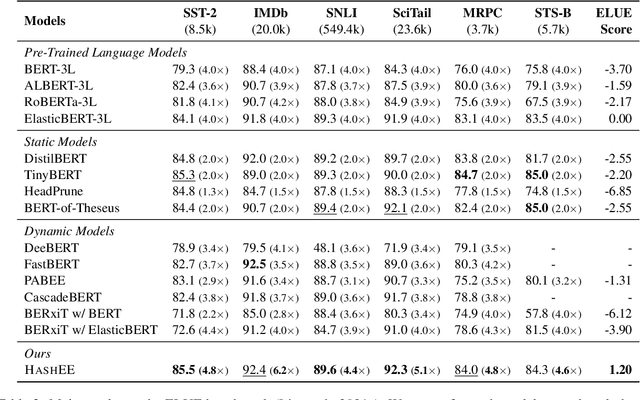
Towards Efficient NLP: A Standard Evaluation and A Strong Baseline
Oct 13, 2021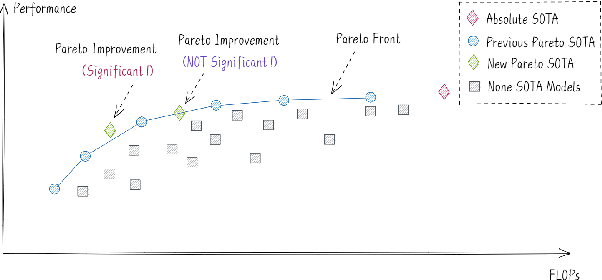
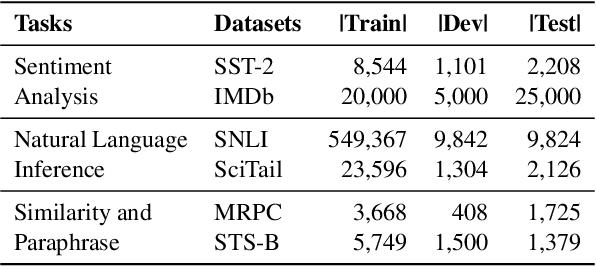
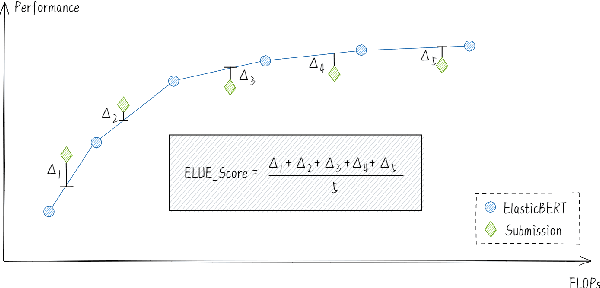
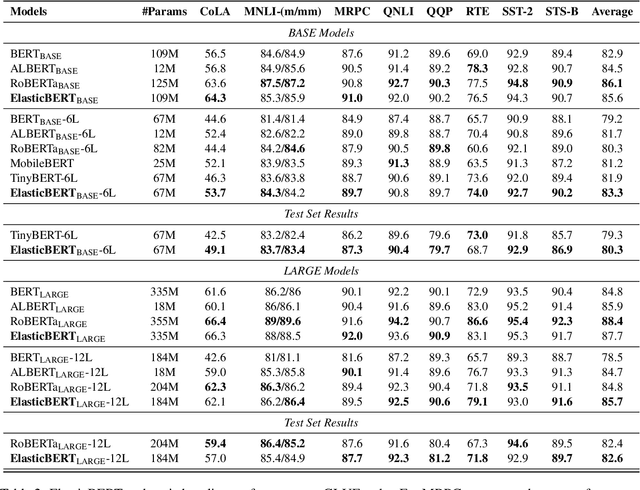
Supersized pre-trained language models have pushed the accuracy of various NLP tasks to a new state-of-the-art (SOTA). Rather than pursuing the reachless SOTA accuracy, most works are pursuing improvement on other dimensions such as efficiency, leading to "Pareto SOTA". Different from accuracy, the metric for efficiency varies across different studies, making them hard to be fairly compared. To that end, this work presents ELUE (Efficient Language Understanding Evaluation), a standard evaluation, and a public leaderboard for efficient NLP models. ELUE is dedicated to depicting the Pareto Front for various language understanding tasks, such that it can tell whether and how much a method achieves Pareto improvement. Along with the benchmark, we also pre-train and release a strong baseline, ElasticBERT, whose elasticity is both static and dynamic. ElasticBERT is static in that it allows reducing model layers on demand. ElasticBERT is dynamic in that it selectively executes parts of model layers conditioned on the input. We demonstrate the ElasticBERT, despite its simplicity, outperforms or performs on par with SOTA compressed and early exiting models. The ELUE benchmark is publicly available at http://eluebenchmark.fastnlp.top/.