 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR Teach, Radar Repeat: Robust Cross-Modal Navigation in Degenerate and Varying Environments
May 04, 2026Long-term autonomy requires robust navigation in environments subject to dynamic and static changes, as well as adverse weather conditions. Teach-and-Repeat (T\&R) navigation offers a reliable and cost-effective solution by avoiding the need for consistent global mapping; however, existing T\&R systems lack a systematic solution to tackle various environmental variations such as weather degradation, ephemeral dynamics, and structural changes. This work proposes LTR$^2$, the first cross-modal, cross-platform LiDAR-Teach-and-Radar-Repeat system that systematically addresses these challenges. LTR$^2$ leverages LiDAR during the teaching phase to capture precise structural information under normal conditions and utilizes 4D millimeter-wave radar during the repeating phase for robust operation under environmental degradations. To align sparse and noisy forward-looking 4D radar with dense and accurate omnidirectional 3D LiDAR data, we introduce a Cross-Modal Registration (CMR) network that jointly exploits Doppler-based motion priors and the physical laws governing LiDAR intensity and radar power density. Furthermore, we propose an adaptive fine-tuning strategy that incrementally updates the CMR network based on localization errors, enabling long-term adaptability to static environmental changes without ground-truth labels. We demonstrate that the proposed CMR network achieves state-of-the-art cross-modal registration performance on the open-access dataset. Then we validate LTR$^2$ across three robot platforms over a large-scale, long-term deployment (40+ km over 6 months), including challenging conditions such as nighttime smoke. Experimental results and ablation studies demonstrate centimeter-level accuracy and strong robustness against diverse environmental disturbances, significantly outperforming existing approaches.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Real Image Restoration via Structure-preserving Complementarity Attention
Jul 28, 2022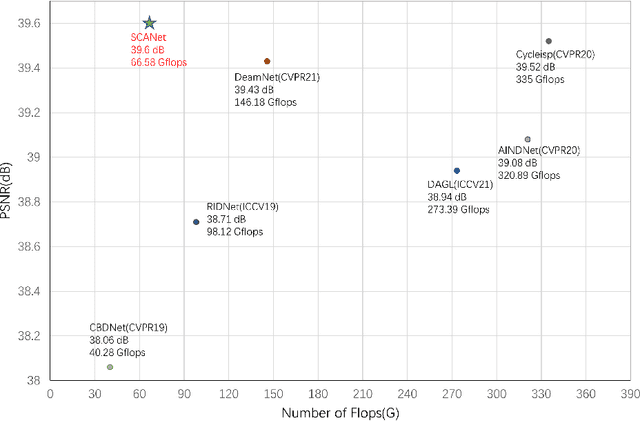
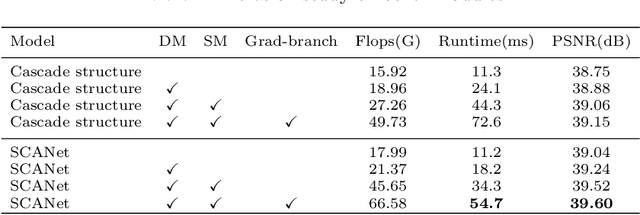
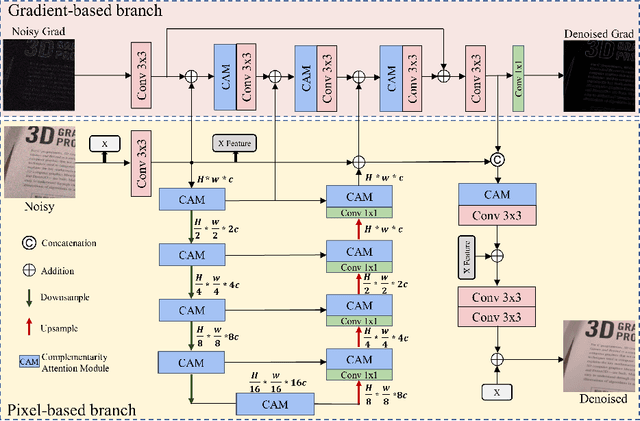

Since convolutional neural networks perform well in learning generalizable image priors from large-scale data, these models have been widely used in image denoising tasks. However, the computational complexity increases dramatically as well on complex model. In this paper, We propose a novel lightweight Complementary Attention Module, which includes a density module and a sparse module, which can cooperatively mine dense and sparse features for feature complementary learning to build an efficient lightweight architecture. Moreover, to reduce the loss of details caused by denoising, this paper constructs a gradient-based structure-preserving branch. We utilize gradient-based branches to obtain additional structural priors for denoising, and make the model pay more attention to image geometric details through gradient loss optimization.Based on the above, we propose an efficiently Unet structured network with dual branch, the visual results show that can effectively preserve the structural details of the original image, we evaluate benchmarks including SIDD and DND, where SCANet achieves state-of-the-art performance in PSNR and SSIM while significantly reducing computational cost.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.