 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mechanistic View on Video Generation as World Models: State and Dynamics
Jan 22, 2026Large-scale video generation models have demonstrated emergent physical coherence, positioning them as potential world models. However, a gap remains between contemporary "stateless" video architectures and classic state-centric world model theories. This work bridges this gap by proposing a novel taxonomy centered on two pillars: State Construction and Dynamics Modeling. We categorize state construction into implicit paradigms (context management) and explicit paradigms (latent compression), while dynamics modeling is analyzed through knowledge integration and architectural reformulation. Furthermore, we advocate for a transition in evaluation from visual fidelity to functional benchmarks, testing physical persistence and causal reasoning. We conclude by identifying two critical frontiers: enhancing persistence via data-driven memory and compressed fidelity, and advancing causality through latent factor decoupling and reasoning-prior integration. By addressing these challenges, the field can evolve from generating visually plausible videos to building robust, general-purpose world simulators.
AnimateAnywhere: Rouse the Background in Human Image Animation
Apr 28, 2025



Human image animation aims to generate human videos of given characters and backgrounds that adhere to the desired pose sequence. However, existing methods focus more on human actions while neglecting the generation of background, which typically leads to static results or inharmonious movements. The community has explored camera pose-guided animation tasks, yet preparing the camera trajectory is impractical for most entertainment applications and ordinary users. As a remedy, we present an AnimateAnywhere framework, rousing the background in human image animation without requirements on camera trajectories. In particular, based on our key insight that the movement of the human body often reflects the motion of the background, we introduce a background motion learner (BML) to learn background motions from human pose sequences. To encourage the model to learn more accurate cross-frame correspondences, we further deploy an epipolar constraint on the 3D attention map. Specifically, the mask used to suppress geometrically unreasonable attention is carefully constructed by combining an epipolar mask and the current 3D attention map. Extensive experiments demonstrate that our AnimateAnywhere effectively learns the background motion from human pose sequences, achieving state-of-the-art performance in generating human animation results with vivid and realistic backgrounds. The source code and model will be available at https://github.com/liuxiaoyu1104/AnimateAnywhere.
DiffuEraser: A Diffusion Model for Video Inpainting
Jan 17, 2025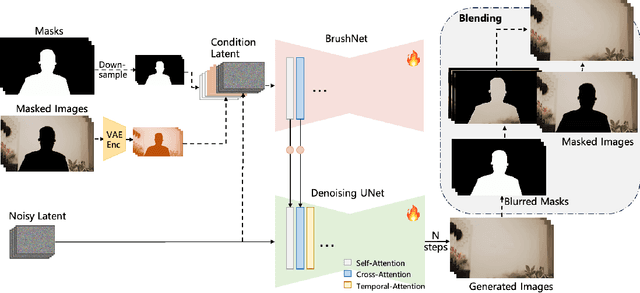

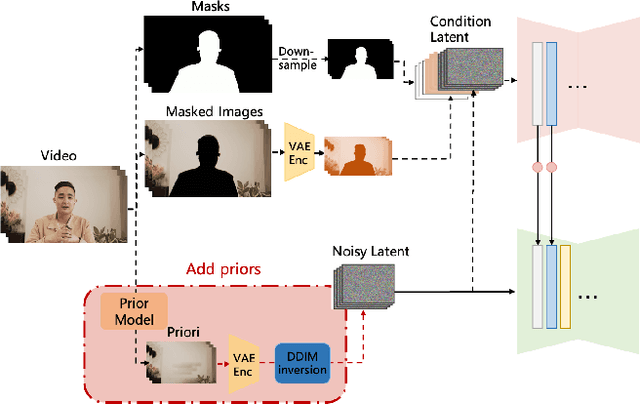

Recent video inpainting algorithms integrate flow-based pixel propagation with transformer-based generation to leverage optical flow for restoring textures and objects using information from neighboring frames, while completing masked regions through visual Transformers. However, these approaches often encounter blurring and temporal inconsistencies when dealing with large masks, highlighting the need for models with enhanced generative capabilities. Recently, diffusion models have emerged as a prominent technique in image and video generation due to their impressive performance. In this paper, we introduce DiffuEraser, a video inpainting model based on stable diffusion, designed to fill masked regions with greater details and more coherent structures. We incorporate prior information to provide initialization and weak conditioning,which helps mitigate noisy artifacts and suppress hallucinations. Additionally, to improve temporal consistency during long-sequence inference, we expand the temporal receptive fields of both the prior model and DiffuEraser, and further enhance consistency by leveraging the temporal smoothing property of Video Diffusion Models. Experimental results demonstrate that our proposed method outperforms state-of-the-art techniques in both content completeness and temporal consistency while maintaining acceptable efficiency.
Multi-modal Learnable Queries for Image Aesthetics Assessment
May 02, 2024



Image aesthetics assessment (IAA) is attracting wide interest with the prevalence of social media. The problem is challenging due to its subjective and ambiguous nature. Instead of directly extracting aesthetic features solely from the image, user comments associated with an image could potentially provide complementary knowledge that is useful for IAA. With existing large-scale pre-trained models demonstrating strong capabilities in extracting high-quality transferable visual and textual features, learnable queries are shown to be effective in extracting useful features from the pre-trained visual features. Therefore, in this paper, we propose MMLQ, which utilizes multi-modal learnable queries to extract aesthetics-related features from multi-modal pre-trained features. Extensive experimental results demonstrate that MMLQ achieves new state-of-the-art performance on multi-modal IAA, beating previous methods by 7.7% and 8.3% in terms of SRCC and PLCC, respectively.
SmartControl: Enhancing ControlNet for Handling Rough Visual Conditions
Apr 09, 2024



Human visual imagination usually begins with analogies or rough sketches. For example, given an image with a girl playing guitar before a building, one may analogously imagine how it seems like if Iron Man playing guitar before Pyramid in Egypt. Nonetheless, visual condition may not be precisely aligned with the imaginary result indicated by text prompt, and existing layout-controllable text-to-image (T2I) generation models is prone to producing degraded generated results with obvious artifacts. To address this issue, we present a novel T2I generation method dubbed SmartControl, which is designed to modify the rough visual conditions for adapting to text prompt. The key idea of our SmartControl is to relax the visual condition on the areas that are conflicted with text prompts. In specific, a Control Scale Predictor (CSP) is designed to identify the conflict regions and predict the local control scales, while a dataset with text prompts and rough visual conditions is constructed for training CSP. It is worth noting that, even with a limited number (e.g., 1,000~2,000) of training samples, our SmartControl can generalize well to unseen objects. Extensive experiments on four typical visual condition types clearly show the efficacy of our SmartControl against state-of-the-arts. Source code, pre-trained models, and datasets are available at https://github.com/liuxiaoyu1104/SmartControl.
VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
Mar 08, 2024Text-to-image diffusion models (T2I) have demonstrated unprecedented capabilities in creating realistic and aesthetic images. On the contrary, text-to-video diffusion models (T2V) still lag far behind in frame quality and text alignment, owing to insufficient quality and quantity of training videos. In this paper, we introduce VideoElevator, a training-free and plug-and-play method, which elevates the performance of T2V using superior capabilities of T2I. Different from conventional T2V sampling (i.e., temporal and spatial modeling), VideoElevator explicitly decomposes each sampling step into temporal motion refining and spatial quality elevating. Specifically, temporal motion refining uses encapsulated T2V to enhance temporal consistency, followed by inverting to the noise distribution required by T2I. Then, spatial quality elevating harnesses inflated T2I to directly predict less noisy latent, adding more photo-realistic details. We have conducted experiments in extensive prompts under the combination of various T2V and T2I. The results show that VideoElevator not only improves the performance of T2V baselines with foundational T2I, but also facilitates stylistic video synthesis with personalized T2I. Our code is available at https://github.com/YBYBZhang/VideoElevator.
DreaMoving: A Human Video Generation Framework based on Diffusion Models
Dec 11, 2023



In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identity moving or dancing anywhere driven by the posture sequences. To this end, we propose a Video ControlNet for motion-controlling and a Content Guider for identity preserving. The proposed model is easy to use and can be adapted to most stylized diffusion models to generate diverse results. The project page is available at https://dreamoving.github.io/dreamoving
Pixel-Aware Stable Diffusion for Realistic Image Super-resolution and Personalized Stylization
Sep 07, 2023Realistic image super-resolution (Real-ISR) aims to reproduce perceptually realistic image details from a low-quality input. The commonly used adversarial training based Real-ISR methods often introduce unnatural visual artifacts and fail to generate realistic textures for natural scene images. The recently developed generative stable diffusion models provide a potential solution to Real-ISR with pre-learned strong image priors. However, the existing methods along this line either fail to keep faithful pixel-wise image structures or resort to extra skipped connections to reproduce details, which requires additional training in image space and limits their extension to other related tasks in latent space such as image stylization. In this work, we propose a pixel-aware stable diffusion (PASD) network to achieve robust Real-ISR as well as personalized stylization. In specific, a pixel-aware cross attention module is introduced to enable diffusion models perceiving image local structures in pixel-wise level, while a degradation removal module is used to extract degradation insensitive features to guide the diffusion process together with image high level information. By simply replacing the base diffusion model with a personalized one, our method can generate diverse stylized images without the need to collect pairwise training data. PASD can be easily integrated into existing diffusion models such as Stable Diffusion. Experiments on Real-ISR and personalized stylization demonstrate the effectiveness of our proposed approach. The source code and models can be found at \url{https://github.com/yangxy/PASD}.
Image Aesthetics Assessment via Learnable Queries
Sep 06, 2023



Image aesthetics assessment (IAA) aims to estimate the aesthetics of images. Depending on the content of an image, diverse criteria need to be selected to assess its aesthetics. Existing works utilize pre-trained vision backbones based on content knowledge to learn image aesthetics. However, training those backbones is time-consuming and suffers from attention dispersion. Inspired by learnable queries in vision-language alignment, we propose the Image Aesthetics Assessment via Learnable Queries (IAA-LQ) approach. It adapts learnable queries to extract aesthetic features from pre-trained image features obtained from a frozen image encoder. Extensive experiments on real-world data demonstrate the advantages of IAA-LQ, beating the best state-of-the-art method by 2.2% and 2.1% in terms of SRCC and PLCC, respectively.
FastLLVE: Real-Time Low-Light Video Enhancement with Intensity-Aware Lookup Table
Aug 13, 2023Low-Light Video Enhancement (LLVE) has received considerable attention in recent years. One of the critical requirements of LLVE is inter-frame brightness consistency, which is essential for maintaining the temporal coherence of the enhanced video. However, most existing single-image-based methods fail to address this issue, resulting in flickering effect that degrades the overall quality after enhancement. Moreover, 3D Convolution Neural Network (CNN)-based methods, which are designed for video to maintain inter-frame consistency, are computationally expensive, making them impractical for real-time applications. To address these issues, we propose an efficient pipeline named FastLLVE that leverages the Look-Up-Table (LUT) technique to maintain inter-frame brightness consistency effectively. Specifically, we design a learnable Intensity-Aware LUT (IA-LUT) module for adaptive enhancement, which addresses the low-dynamic problem in low-light scenarios. This enables FastLLVE to perform low-latency and low-complexity enhancement operations while maintaining high-quality results. Experimental results on benchmark datasets demonstrate that our method achieves the State-Of-The-Art (SOTA) performance in terms of both image quality and inter-frame brightness consistency. More importantly, our FastLLVE can process 1,080p videos at $\mathit{50+}$ Frames Per Second (FPS), which is $\mathit{2 \times}$ faster than SOTA CNN-based methods in inference time, making it a promising solution for real-time applications. The code is available at https://github.com/Wenhao-Li-777/FastLLVE.