 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCon: Unidirectional Information Flow for Effective Control of Large-Scale Diffusion Models
Mar 21, 2025We introduce UniCon, a novel architecture designed to enhance control and efficiency in training adapters for large-scale diffusion models. Unlike existing methods that rely on bidirectional interaction between the diffusion model and control adapter, UniCon implements a unidirectional flow from the diffusion network to the adapter, allowing the adapter alone to generate the final output. UniCon reduces computational demands by eliminating the need for the diffusion model to compute and store gradients during adapter training. Our results indicate that UniCon reduces GPU memory usage by one-third and increases training speed by 2.3 times, while maintaining the same adapter parameter size. Additionally, without requiring extra computational resources, UniCon enables the training of adapters with double the parameter volume of existing ControlNets. In a series of image conditional generation tasks, UniCon has demonstrated precise responsiveness to control inputs and exceptional generation capabilities.
Interpreting Low-level Vision Models with Causal Effect Maps
Jul 29, 2024



Deep neural networks have significantly improved the performance of low-level vision tasks but also increased the difficulty of interpretability. A deep understanding of deep models is beneficial for both network design and practical reliability. To take up this challenge, we introduce causality theory to interpret low-level vision models and propose a model-/task-agnostic method called Causal Effect Map (CEM). With CEM, we can visualize and quantify the input-output relationships on either positive or negative effects. After analyzing various low-level vision tasks with CEM, we have reached several interesting insights, such as: (1) Using more information of input images (e.g., larger receptive field) does NOT always yield positive outcomes. (2) Attempting to incorporate mechanisms with a global receptive field (e.g., channel attention) into image denoising may prove futile. (3) Integrating multiple tasks to train a general model could encourage the network to prioritize local information over global context. Based on the causal effect theory, the proposed diagnostic tool can refresh our common knowledge and bring a deeper understanding of low-level vision models. Codes are available at https://github.com/J-FHu/CEM.
Descriptive Image Quality Assessment in the Wild
May 29, 2024



With the rapid advancement of Vision Language Models (VLMs), VLM-based Image Quality Assessment (IQA) seeks to describe image quality linguistically to align with human expression and capture the multifaceted nature of IQA tasks. However, current methods are still far from practical usage. First, prior works focus narrowly on specific sub-tasks or settings, which do not align with diverse real-world applications. Second, their performance is sub-optimal due to limitations in dataset coverage, scale, and quality. To overcome these challenges, we introduce Depicted image Quality Assessment in the Wild (DepictQA-Wild). Our method includes a multi-functional IQA task paradigm that encompasses both assessment and comparison tasks, brief and detailed responses, full-reference and non-reference scenarios. We introduce a ground-truth-informed dataset construction approach to enhance data quality, and scale up the dataset to 495K under the brief-detail joint framework. Consequently, we construct a comprehensive, large-scale, and high-quality dataset, named DQ-495K. We also retain image resolution during training to better handle resolution-related quality issues, and estimate a confidence score that is helpful to filter out low-quality responses. Experimental results demonstrate that DepictQA-Wild significantly outperforms traditional score-based methods, prior VLM-based IQA models, and proprietary GPT-4V in distortion identification, instant rating, and reasoning tasks. Our advantages are further confirmed by real-world applications including assessing the web-downloaded images and ranking model-processed images. Datasets and codes will be released in https://depictqa.github.io/depictqa-wild/.
Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild
Jan 24, 2024



We introduce SUPIR (Scaling-UP Image Restoration), a groundbreaking image restoration method that harnesses generative prior and the power of model scaling up. Leveraging multi-modal techniques and advanced generative prior, SUPIR marks a significant advance in intelligent and realistic image restoration. As a pivotal catalyst within SUPIR, model scaling dramatically enhances its capabilities and demonstrates new potential for image restoration. We collect a dataset comprising 20 million high-resolution, high-quality images for model training, each enriched with descriptive text annotations. SUPIR provides the capability to restore images guided by textual prompts, broadening its application scope and potential. Moreover, we introduce negative-quality prompts to further improve perceptual quality. We also develop a restoration-guided sampling method to suppress the fidelity issue encountered in generative-based restoration. Experiments demonstrate SUPIR's exceptional restoration effects and its novel capacity to manipulate restoration through textual prompts.
Depicting Beyond Scores: Advancing Image Quality Assessment through Multi-modal Language Models
Dec 14, 2023



We introduce a Depicted image Quality Assessment method (DepictQA), overcoming the constraints of traditional score-based approaches. DepictQA leverages Multi-modal Large Language Models (MLLMs), allowing for detailed, language-based, human-like evaluation of image quality. Unlike conventional Image Quality Assessment (IQA) methods relying on scores, DepictQA interprets image content and distortions descriptively and comparatively, aligning closely with humans' reasoning process. To build the DepictQA model, we establish a hierarchical task framework, and collect a multi-modal IQA training dataset, named M-BAPPS. To navigate the challenges in limited training data and processing multiple images, we propose to use multi-source training data and specialized image tags. Our DepictQA demonstrates a better performance than score-based methods on the BAPPS benchmark. Moreover, compared with general MLLMs, our DepictQA can generate more accurate reasoning descriptive languages. Our research indicates that language-based IQA methods have the potential to be customized for individual preferences. Datasets and codes will be released publicly.
A Comparative Study of Image Restoration Networks for General Backbone Network Design
Oct 18, 2023Despite the significant progress made by deep models in various image restoration tasks, existing image restoration networks still face challenges in terms of task generality. An intuitive manifestation is that networks which excel in certain tasks often fail to deliver satisfactory results in others. To illustrate this point, we select five representative image restoration networks and conduct a comparative study on five classic image restoration tasks. First, we provide a detailed explanation of the characteristics of different image restoration tasks and backbone networks. Following this, we present the benchmark results and analyze the reasons behind the performance disparity of different models across various tasks. Drawing from this comparative study, we propose that a general image restoration backbone network needs to meet the functional requirements of diverse tasks. Based on this principle, we design a new general image restoration backbone network, X-Restormer. Extensive experiments demonstrate that X-Restormer possesses good task generality and achieves state-of-the-art performance across a variety of tasks.
Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation
Sep 08, 2023



Modern displays are capable of rendering video content with high dynamic range (HDR) and wide color gamut (WCG). However, the majority of available resources are still in standard dynamic range (SDR). As a result, there is significant value in transforming existing SDR content into the HDRTV standard. In this paper, we define and analyze the SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Our analysis and observations indicate that a naive end-to-end supervised training pipeline suffers from severe gamut transition errors. To address this issue, we propose a novel three-step solution pipeline called HDRTVNet++, which includes adaptive global color mapping, local enhancement, and highlight refinement. The adaptive global color mapping step uses global statistics as guidance to perform image-adaptive color mapping. A local enhancement network is then deployed to enhance local details. Finally, we combine the two sub-networks above as a generator and achieve highlight consistency through GAN-based joint training. Our method is primarily designed for ultra-high-definition TV content and is therefore effective and lightweight for processing 4K resolution images. We also construct a dataset using HDR videos in the HDR10 standard, named HDRTV1K that contains 1235 and 117 training images and 117 testing images, all in 4K resolution. Besides, we select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Our final results demonstrate state-of-the-art performance both quantitatively and visually. The code, model and dataset are available at https://github.com/xiaom233/HDRTVNet-plus.
GET3D--: Learning GET3D from Unconstrained Image Collections
Jul 27, 2023



The demand for efficient 3D model generation techniques has grown exponentially, as manual creation of 3D models is time-consuming and requires specialized expertise. While generative models have shown potential in creating 3D textured shapes from 2D images, their applicability in 3D industries is limited due to the lack of a well-defined camera distribution in real-world scenarios, resulting in low-quality shapes. To overcome this limitation, we propose GET3D--, the first method that directly generates textured 3D shapes from 2D images with unknown pose and scale. GET3D-- comprises a 3D shape generator and a learnable camera sampler that captures the 6D external changes on the camera. In addition, We propose a novel training schedule to stably optimize both the shape generator and camera sampler in a unified framework. By controlling external variations using the learnable camera sampler, our method can generate aligned shapes with clear textures. Extensive experiments demonstrate the efficacy of GET3D--, which precisely fits the 6D camera pose distribution and generates high-quality shapes on both synthetic and realistic unconstrained datasets.
Efficient Image Super-Resolution using Vast-Receptive-Field Attention
Oct 12, 2022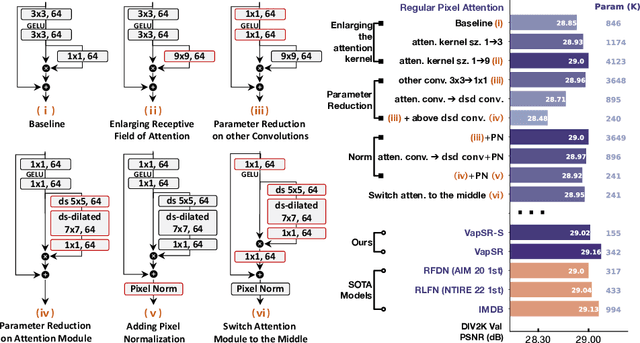
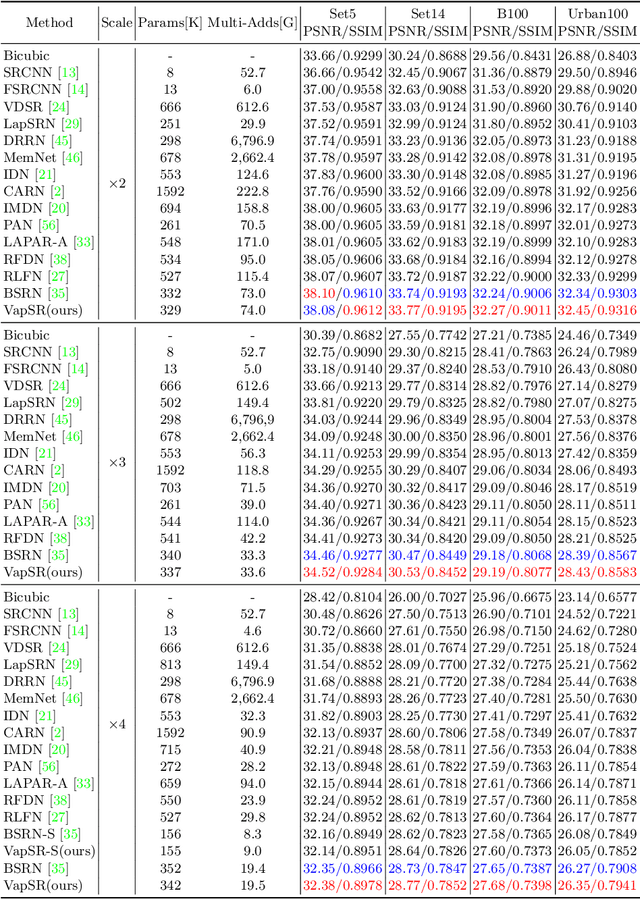
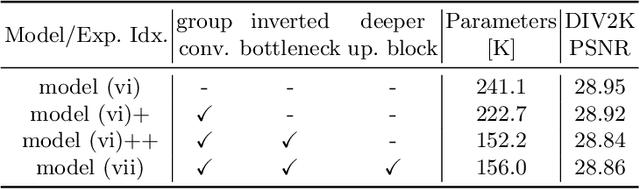
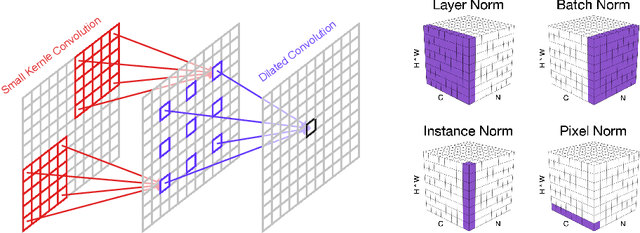
The attention mechanism plays a pivotal role in designing advanced super-resolution (SR) networks. In this work, we design an efficient SR network by improving the attention mechanism. We start from a simple pixel attention module and gradually modify it to achieve better super-resolution performance with reduced parameters. The specific approaches include: (1) increasing the receptive field of the attention branch, (2) replacing large dense convolution kernels with depth-wise separable convolutions, and (3) introducing pixel normalization. These approaches paint a clear evolutionary roadmap for the design of attention mechanisms. Based on these observations, we propose VapSR, the VAst-receptive-field Pixel attention network. Experiments demonstrate the superior performance of VapSR. VapSR outperforms the present lightweight networks with even fewer parameters. And the light version of VapSR can use only 21.68% and 28.18% parameters of IMDB and RFDN to achieve similar performances to those networks. The code and models are available at url{https://github.com/zhoumumu/VapSR.
Blueprint Separable Residual Network for Efficient Image Super-Resolution
May 12, 2022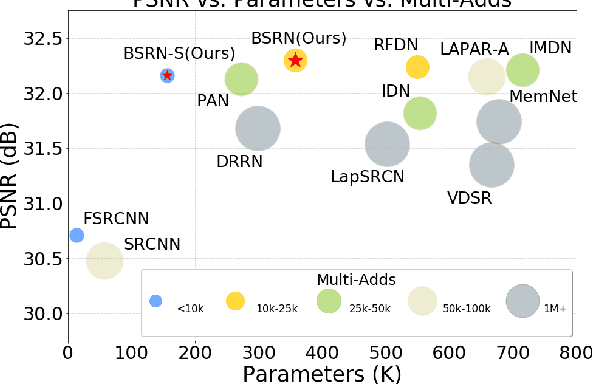



Recent advances in single image super-resolution (SISR) have achieved extraordinary performance, but the computational cost is too heavy to apply in edge devices. To alleviate this problem, many novel and effective solutions have been proposed. Convolutional neural network (CNN) with the attention mechanism has attracted increasing attention due to its efficiency and effectiveness. However, there is still redundancy in the convolution operation. In this paper, we propose Blueprint Separable Residual Network (BSRN) containing two efficient designs. One is the usage of blueprint separable convolution (BSConv), which takes place of the redundant convolution operation. The other is to enhance the model ability by introducing more effective attention modules. The experimental results show that BSRN achieves state-of-the-art performance among existing efficient SR methods. Moreover, a smaller variant of our model BSRN-S won the first place in model complexity track of NTIRE 2022 Efficient SR Challenge. The code is available at https://github.com/xiaom233/BSRN.