 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
Jun 03, 2026We present AAD-1, an Asymmetric Adversarial Distillation framework for One-step autoregressive image-to-video generation. State-of-the-art methods adopt adversarial distillation but suffer from motion collapse and training instability, resulting in static videos. AAD-1 addresses these challenges through two key designs in architecture and training strategy. Our key architectural insight is to break the symmetry between generator and discriminator. While the generator remains causal to preserve autoregressive sampling capability, the discriminator attends bidirectionally over the full spatiotemporal context and produces a single holistic realism score for the entire video sequence. This asymmetric design enables the discriminator to effectively detect global temporal failures and long-range drift that cause motion collapse in autoregressive generation. To stabilize training, we introduce a phased strategy that first uses distribution matching to bootstrap a stable one-step generator, providing a warm-up phase that brings the student distribution closer to the teacher before adversarial distillation begins. Extensive experiments on VBench demonstrate that AAD-1 achieves state-of-the-art performance in one-step autoregressive video generation.
Can Retrieval Heads See Images? Multimodal Retrieval Heads in Long-Context Vision-Language Models
May 26, 2026Large vision-language models increasingly rely on long-context modeling to reason over documents, hour-level videos, and long-horizon agent trajectories, requiring them to locate relevant evidence across interleaved text and images. Prior work has studied this behavior using retrieval heads in large language models, but its copy-based criterion does not directly apply when evidence appears in images. We introduce a multimodal retrieval head detection method that scores attention from question tokens to textual or visual evidence. With this method, we show that multimodal retrieval heads are sparse, intrinsic, and causally important: only 4.4-10.2% of attention heads account for 50% of the positive retrieval-score mass, and masking the top-5% selected heads drops MMLongBench-Doc from 48.2% to 5.7% and SlideVQA from 71.2% to 8.9%, while random-head masking is far less damaging. Further analysis shows that these heads are partly shared across modalities yet remain dynamic within each modality, with image retrieval heads changing more than text retrieval heads as context length and haystack modality change. Without further training, we find that these heads can also be used directly to rank visually rich documents: on MMDocIR, Qwen3-VL-8B selected-head scoring improves Recall@1 by 7.7/7.4 macro/micro points for page retrieval and 6.3/6.8 points for layout retrieval over the strongest reported baseline.
Are Agents Ready to Teach? A Multi-Stage Benchmark for Real-World Teaching Workflows
May 14, 2026Language agents are increasingly deployed in complex professional workflows, with tutoring emerging as a particularly high-stakes capability that remains largely unmeasured in existing benchmarks. Effective tutor agents require more than producing correct answers or executing accurate tool calls: a robust tutor must diagnose learner state, adapt support over time, make pedagogically justified decisions grounded in educational evidence, and execute interventions within realistic learning-management systems. We introduce EduAgentBench, a source-grounded benchmark for holistically evaluating tutor agents across the full scope of teaching work. It contains 150 quality-controlled tasks across three capability surfaces: professional pedagogical judgment, situated multi-turn tutoring, and Canvas-style teaching workflow completion. Tasks are constructed through a pedagogical-insight-driven pipeline and evaluated with complementary verification signals and human review. Across a comprehensive evaluation of frontier models, our findings reveal that current models are generally capable of bounded pedagogical judgment, but still fall short of professional teaching standards in situated tutoring and autonomous teaching-workflow execution. To our knowledge, EduAgentBench is the first theory-grounded and realistic benchmark for evaluating the holistic teaching capability of tutor agents, providing a measurement foundation for developing future tutor agents that can support realistic teaching work.
CausalCine: Real-Time Autoregressive Generation for Multi-Shot Video Narratives
May 12, 2026Autoregressive video generation aims at real-time, open-ended synthesis. Yet, cinematic storytelling is not merely the endless extension of a single scene; it requires progressing through evolving events, viewpoint shifts, and discrete shot boundaries. Existing autoregressive models often struggle in this setting. Trained primarily for short-horizon continuation, they treat long sequences as extended single shots, inevitably suffering from motion stagnation and semantic drift during long rollouts. To bridge this gap, we introduce CausalCine, an interactive autoregressive framework that transforms multi-shot video generation into an online directing process. CausalCine generates causally across shot changes, accepts dynamic prompts on the fly, and reuses context without regenerating previous shots. To achieve this, we first train a causal base model on native multi-shot sequences to learn complex shot transitions prior to acceleration. We then propose Content-Aware Memory Routing (CAMR), which dynamically retrieves historical KV entries according to attention-based relevance scores rather than temporal proximity, preserving cross-shot coherence under bounded active memory. Finally, we distill the causal base model into a few-step generator for real-time interactive generation. Extensive experiments demonstrate that CausalCine significantly outperforms autoregressive baselines and approaches the capability of bidirectional models while unlocking the streaming interactivity of causal generation. Demo available at https://yihao-meng.github.io/CausalCine/
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
CLLMate: A Multimodal LLM for Weather and Climate Events Forecasting
Sep 27, 2024



Forecasting weather and climate events is crucial for making appropriate measures to mitigate environmental hazards and minimize associated losses. Previous research on environmental forecasting focuses on predicting numerical meteorological variables related to closed-set events rather than forecasting open-set events directly, which limits the comprehensiveness of event forecasting. We propose Weather and Climate Event Forecasting (WCEF), a new task that leverages meteorological raster data and textual event data to predict potential weather and climate events. However, due to difficulties in aligning multimodal data and the lack of sufficient supervised datasets, this task is challenging to accomplish. Therefore, we first propose a framework to align historical meteorological data with past weather and climate events using the large language model (LLM). In this framework, we construct a knowledge graph by using LLM to extract information about weather and climate events from a corpus of over 41k highly environment-focused news articles. Subsequently, we mapped these events with meteorological raster data, creating a supervised dataset, which is the largest and most novel for LLM tuning on the WCEF task. Finally, we introduced our aligned models, CLLMate (LLM for climate), a multimodal LLM to forecast weather and climate events using meteorological raster data. In evaluating CLLMate, we conducted extensive experiments. The results indicate that CLLMate surpasses both the baselines and other multimodal LLMs, showcasing the potential of utilizing LLM to align weather and climate events with meteorological data and highlighting the promising future for research on the WCEF task.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Two-Factor Authentication Approach Based on Behavior Patterns for Defeating Puppet Attacks
Nov 17, 2023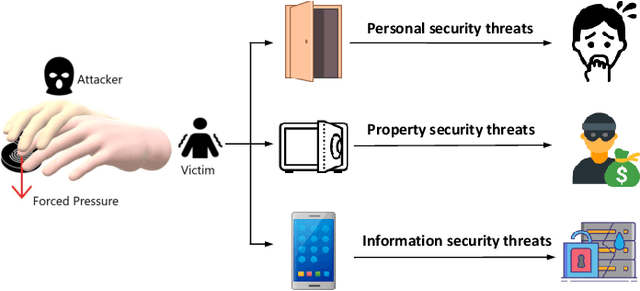
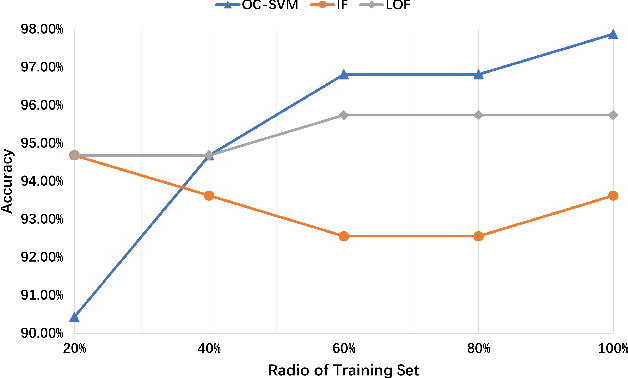

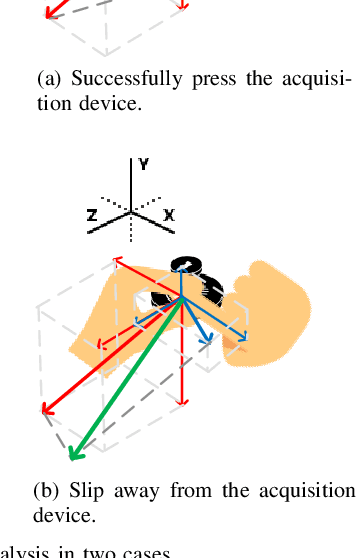
Fingerprint traits are widely recognized for their unique qualities and security benefits. Despite their extensive use, fingerprint features can be vulnerable to puppet attacks, where attackers manipulate a reluctant but genuine user into completing the authentication process. Defending against such attacks is challenging due to the coexistence of a legitimate identity and an illegitimate intent. In this paper, we propose PUPGUARD, a solution designed to guard against puppet attacks. This method is based on user behavioral patterns, specifically, the user needs to press the capture device twice successively with different fingers during the authentication process. PUPGUARD leverages both the image features of fingerprints and the timing characteristics of the pressing intervals to establish two-factor authentication. More specifically, after extracting image features and timing characteristics, and performing feature selection on the image features, PUPGUARD fuses these two features into a one-dimensional feature vector, and feeds it into a one-class classifier to obtain the classification result. This two-factor authentication method emphasizes dynamic behavioral patterns during the authentication process, thereby enhancing security against puppet attacks. To assess PUPGUARD's effectiveness, we conducted experiments on datasets collected from 31 subjects, including image features and timing characteristics. Our experimental results demonstrate that PUPGUARD achieves an impressive accuracy rate of 97.87% and a remarkably low false positive rate (FPR) of 1.89%. Furthermore, we conducted comparative experiments to validate the superiority of combining image features and timing characteristics within PUPGUARD for enhancing resistance against puppet attacks.
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023



Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.