 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman or LLM as Standardized Patients? A Comparative Study for Medical Education
Nov 12, 2025Standardized Patients (SP) are indispensable for clinical skills training but remain expensive, inflexible, and difficult to scale. Existing large-language-model (LLM)-based SP simulators promise lower cost yet show inconsistent behavior and lack rigorous comparison with human SP. We present EasyMED, a multi-agent framework combining a Patient Agent for realistic dialogue, an Auxiliary Agent for factual consistency, and an Evaluation Agent that delivers actionable feedback. To support systematic assessment, we introduce SPBench, a benchmark of real SP-doctor interactions spanning 14 specialties and eight expert-defined evaluation criteria. Experiments demonstrate that EasyMED matches human SP learning outcomes while producing greater skill gains for lower-baseline students and offering improved flexibility, psychological safety, and cost efficiency.
Large Language Models for Outpatient Referral: Problem Definition, Benchmarking and Challenges
Mar 11, 2025



Large language models (LLMs) are increasingly applied to outpatient referral tasks across healthcare systems. However, there is a lack of standardized evaluation criteria to assess their effectiveness, particularly in dynamic, interactive scenarios. In this study, we systematically examine the capabilities and limitations of LLMs in managing tasks within Intelligent Outpatient Referral (IOR) systems and propose a comprehensive evaluation framework specifically designed for such systems. This framework comprises two core tasks: static evaluation, which focuses on evaluating the ability of predefined outpatient referrals, and dynamic evaluation, which evaluates capabilities of refining outpatient referral recommendations through iterative dialogues. Our findings suggest that LLMs offer limited advantages over BERT-like models, but show promise in asking effective questions during interactive dialogues.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022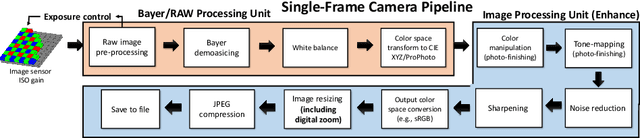
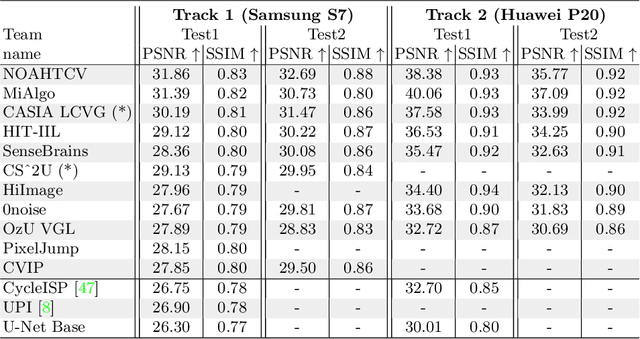
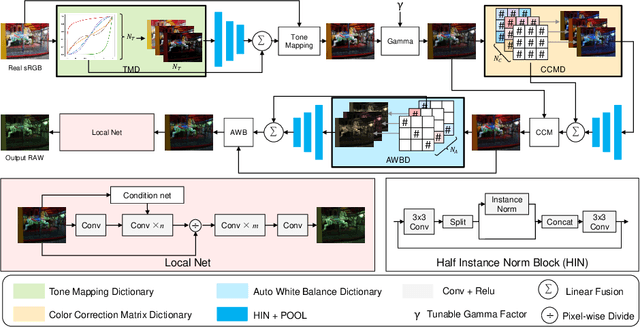
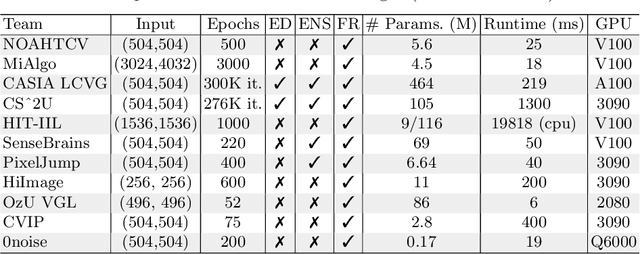
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.