 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Apr 09, 2024

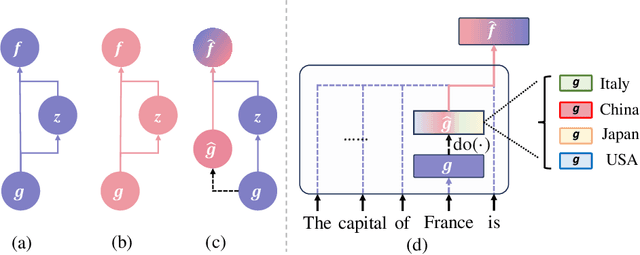

In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.
Dynamic Prompt Optimizing for Text-to-Image Generation
Apr 05, 2024



Text-to-image generative models, specifically those based on diffusion models like Imagen and Stable Diffusion, have made substantial advancements. Recently, there has been a surge of interest in the delicate refinement of text prompts. Users assign weights or alter the injection time steps of certain words in the text prompts to improve the quality of generated images. However, the success of fine-control prompts depends on the accuracy of the text prompts and the careful selection of weights and time steps, which requires significant manual intervention. To address this, we introduce the \textbf{P}rompt \textbf{A}uto-\textbf{E}diting (PAE) method. Besides refining the original prompts for image generation, we further employ an online reinforcement learning strategy to explore the weights and injection time steps of each word, leading to the dynamic fine-control prompts. The reward function during training encourages the model to consider aesthetic score, semantic consistency, and user preferences. Experimental results demonstrate that our proposed method effectively improves the original prompts, generating visually more appealing images while maintaining semantic alignment. Code is available at https://github.com/Mowenyii/PAE.
EulerFormer: Sequential User Behavior Modeling with Complex Vector Attention
Apr 04, 2024



To capture user preference, transformer models have been widely applied to model sequential user behavior data. The core of transformer architecture lies in the self-attention mechanism, which computes the pairwise attention scores in a sequence. Due to the permutation-equivariant nature, positional encoding is used to enhance the attention between token representations. In this setting, the pairwise attention scores can be derived by both semantic difference and positional difference. However, prior studies often model the two kinds of difference measurements in different ways, which potentially limits the expressive capacity of sequence modeling. To address this issue, this paper proposes a novel transformer variant with complex vector attention, named EulerFormer, which provides a unified theoretical framework to formulate both semantic difference and positional difference. The EulerFormer involves two key technical improvements. First, it employs a new transformation function for efficiently transforming the sequence tokens into polar-form complex vectors using Euler's formula, enabling the unified modeling of both semantic and positional information in a complex rotation form.Secondly, it develops a differential rotation mechanism, where the semantic rotation angles can be controlled by an adaptation function, enabling the adaptive integration of the semantic and positional information according to the semantic contexts.Furthermore, a phase contrastive learning task is proposed to improve the isotropy of contextual representations in EulerFormer. Our theoretical framework possesses a high degree of completeness and generality. It is more robust to semantic variations and possesses moresuperior theoretical properties in principle. Extensive experiments conducted on four public datasets demonstrate the effectiveness and efficiency of our approach.
Investigating the Robustness of Counterfactual Learning to Rank Models: A Reproducibility Study
Apr 04, 2024



Counterfactual learning to rank (CLTR) has attracted extensive attention in the IR community for its ability to leverage massive logged user interaction data to train ranking models. While the CLTR models can be theoretically unbiased when the user behavior assumption is correct and the propensity estimation is accurate, their effectiveness is usually empirically evaluated via simulation-based experiments due to a lack of widely-available, large-scale, real click logs. However, the mainstream simulation-based experiments are somewhat limited as they often feature a single, deterministic production ranker and simplified user simulation models to generate the synthetic click logs. As a result, the robustness of CLTR models in complex and diverse situations is largely unknown and needs further investigation. To address this problem, in this paper, we aim to investigate the robustness of existing CLTR models in a reproducibility study with extensive simulation-based experiments that (1) use both deterministic and stochastic production rankers, each with different ranking performance, and (2) leverage multiple user simulation models with different user behavior assumptions. We find that the DLA models and IPS-DCM show better robustness under various simulation settings than IPS-PBM and PRS with offline propensity estimation. Besides, the existing CLTR models often fail to outperform the naive click baselines when the production ranker has relatively high ranking performance or certain randomness, which suggests an urgent need for developing new CLTR algorithms that work for these settings.
Selecting Query-bag as Pseudo Relevance Feedback for Information-seeking Conversations
Mar 22, 2024



Information-seeking dialogue systems are widely used in e-commerce systems, with answers that must be tailored to fit the specific settings of the online system. Given the user query, the information-seeking dialogue systems first retrieve a subset of response candidates, then further select the best response from the candidate set through re-ranking. Current methods mainly retrieve response candidates based solely on the current query, however, incorporating similar questions could introduce more diverse content, potentially refining the representation and improving the matching process. Hence, in this paper, we proposed a Query-bag based Pseudo Relevance Feedback framework (QB-PRF), which constructs a query-bag with related queries to serve as pseudo signals to guide information-seeking conversations. Concretely, we first propose a Query-bag Selection module (QBS), which utilizes contrastive learning to train the selection of synonymous queries in an unsupervised manner by leveraging the representations learned from pre-trained VAE. Secondly, we come up with a Query-bag Fusion module (QBF) that fuses synonymous queries to enhance the semantic representation of the original query through multidimensional attention computation. We verify the effectiveness of the QB-PRF framework on two competitive pretrained backbone models, including BERT and GPT-2. Experimental results on two benchmark datasets show that our framework achieves superior performance over strong baselines.
ChainLM: Empowering Large Language Models with Improved Chain-of-Thought Prompting
Mar 21, 2024



Chain-of-Thought (CoT) prompting can enhance the reasoning capabilities of large language models (LLMs), establishing itself as a primary approach to solving complex reasoning tasks. Existing CoT synthesis approaches usually focus on simpler reasoning tasks and thus result in low-quality and inconsistent CoT prompts. In response to this challenge, we present an empirical investigation of CoT prompting and introduce CoTGenius, a novel framework designed for the automatic generation of superior CoT prompts. CoTGenius is developed based on three major evolution strategies, i.e., complicate, diversify, and specify-alongside two filtering mechanisms: evolutionary success judgement and correctness verification. We further employ CoTGenius to create an extensive CoT dataset, and subsequently fine-tune the Llama 2-Chat 7B and 13B models on this dataset. We call the resulting model ChainLM. To deal with the cumulative error issue in reasoning steps, we propose a step-level debating method, wherein multiple debaters discuss each reasoning step to arrive at the correct answer. Extensive experiments demonstrate that our ChainLM models exhibit enhanced proficiency in addressing a spectrum of complex reasoning problems compared to existing models. In addition, we conduct an in-depth analysis of the impact of data categories within CoTGenius on the model performance. We release our dataset and code at https://github.com/RUCAIBox/ChainLM.
Less is More: Data Value Estimation for Visual Instruction Tuning
Mar 21, 2024Visual instruction tuning is the key to building multimodal large language models (MLLMs), which greatly improves the reasoning capabilities of large language models (LLMs) in vision scenario. However, existing MLLMs mostly rely on a mixture of multiple highly diverse visual instruction datasets for training (even more than a million instructions), which may introduce data redundancy. To investigate this issue, we conduct a series of empirical studies, which reveal a significant redundancy within the visual instruction datasets, and show that greatly reducing the amount of several instruction dataset even do not affect the performance. Based on the findings, we propose a new data selection approach TIVE, to eliminate redundancy within visual instruction data. TIVE first estimates the task-level and instance-level value of the visual instructions based on computed gradients. Then, according to the estimated values, TIVE determines the task proportion within the visual instructions, and selects representative instances to compose a smaller visual instruction subset for training. Experiments on LLaVA-1.5 show that our approach using only about 7.5% data can achieve comparable performance as the full-data fine-tuned model across seven benchmarks, even surpassing it on four of the benchmarks. Our code and data will be publicly released.
An Analysis on Matching Mechanisms and Token Pruning for Late-interaction Models
Mar 20, 2024With the development of pre-trained language models, the dense retrieval models have become promising alternatives to the traditional retrieval models that rely on exact match and sparse bag-of-words representations. Different from most dense retrieval models using a bi-encoder to encode each query or document into a dense vector, the recently proposed late-interaction multi-vector models (i.e., ColBERT and COIL) achieve state-of-the-art retrieval effectiveness by using all token embeddings to represent documents and queries and modeling their relevance with a sum-of-max operation. However, these fine-grained representations may cause unacceptable storage overhead for practical search systems. In this study, we systematically analyze the matching mechanism of these late-interaction models and show that the sum-of-max operation heavily relies on the co-occurrence signals and some important words in the document. Based on these findings, we then propose several simple document pruning methods to reduce the storage overhead and compare the effectiveness of different pruning methods on different late-interaction models. We also leverage query pruning methods to further reduce the retrieval latency. We conduct extensive experiments on both in-domain and out-domain datasets and show that some of the used pruning methods can significantly improve the efficiency of these late-interaction models without substantially hurting their retrieval effectiveness.
A Large Language Model Enhanced Sequential Recommender for Joint Video and Comment Recommendation
Mar 20, 2024



In online video platforms, reading or writing comments on interesting videos has become an essential part of the video watching experience. However, existing video recommender systems mainly model users' interaction behaviors with videos, lacking consideration of comments in user behavior modeling. In this paper, we propose a novel recommendation approach called LSVCR by leveraging user interaction histories with both videos and comments, so as to jointly conduct personalized video and comment recommendation. Specifically, our approach consists of two key components, namely sequential recommendation (SR) model and supplemental large language model (LLM) recommender. The SR model serves as the primary recommendation backbone (retained in deployment) of our approach, allowing for efficient user preference modeling. Meanwhile, we leverage the LLM recommender as a supplemental component (discarded in deployment) to better capture underlying user preferences from heterogeneous interaction behaviors. In order to integrate the merits of the SR model and the supplemental LLM recommender, we design a twostage training paradigm. The first stage is personalized preference alignment, which aims to align the preference representations from both components, thereby enhancing the semantics of the SR model. The second stage is recommendation-oriented fine-tuning, in which the alignment-enhanced SR model is fine-tuned according to specific objectives. Extensive experiments in both video and comment recommendation tasks demonstrate the effectiveness of LSVCR. Additionally, online A/B testing on the KuaiShou platform verifies the actual benefits brought by our approach. In particular, we achieve a significant overall gain of 4.13% in comment watch time.
Images are Achilles' Heel of Alignment: Exploiting Visual Vulnerabilities for Jailbreaking Multimodal Large Language Models
Mar 14, 2024In this paper, we study the harmlessness alignment problem of multimodal large language models~(MLLMs). We conduct a systematic empirical analysis of the harmlessness performance of representative MLLMs and reveal that the image input poses the alignment vulnerability of MLLMs. Inspired by this, we propose a novel jailbreak method named HADES, which hides and amplifies the harmfulness of the malicious intent within the text input, using meticulously crafted images. Experimental results show that HADES can effectively jailbreak existing MLLMs, which achieves an average Attack Success Rate~(ASR) of 90.26% for LLaVA-1.5 and 71.60% for Gemini Pro Vision. Our code and data will be publicly released.