 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
FastMoE: A Fast Mixture-of-Expert Training System
Mar 24, 2021



Mixture-of-Expert (MoE) presents a strong potential in enlarging the size of language model to trillions of parameters. However, training trillion-scale MoE requires algorithm and system co-design for a well-tuned high performance distributed training system. Unfortunately, the only existing platform that meets the requirements strongly depends on Google's hardware (TPU) and software (Mesh Tensorflow) stack, and is not open and available to the public, especially GPU and PyTorch communities. In this paper, we present FastMoE, a distributed MoE training system based on PyTorch with common accelerators. The system provides a hierarchical interface for both flexible model design and easy adaption to different applications, such as Transformer-XL and Megatron-LM. Different from direct implementation of MoE models using PyTorch, the training speed is highly optimized in FastMoE by sophisticated high-performance acceleration skills. The system supports placing different experts on multiple GPUs across multiple nodes, enabling enlarging the number of experts linearly against the number of GPUs. The source of FastMoE is available at https://github.com/laekov/fastmoe under Apache-2 license.
Heterogeneity-Aware Asynchronous Decentralized Training
Sep 17, 2019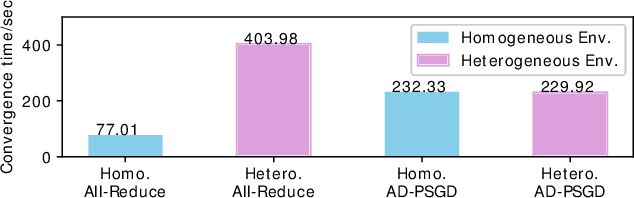
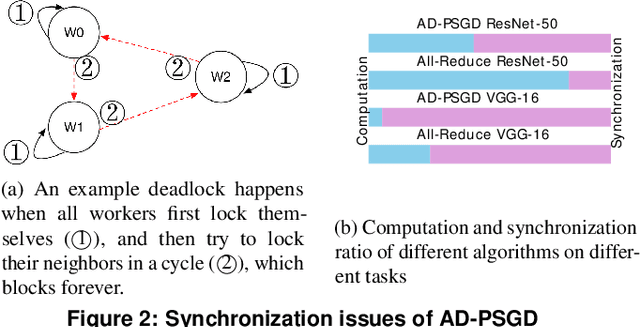
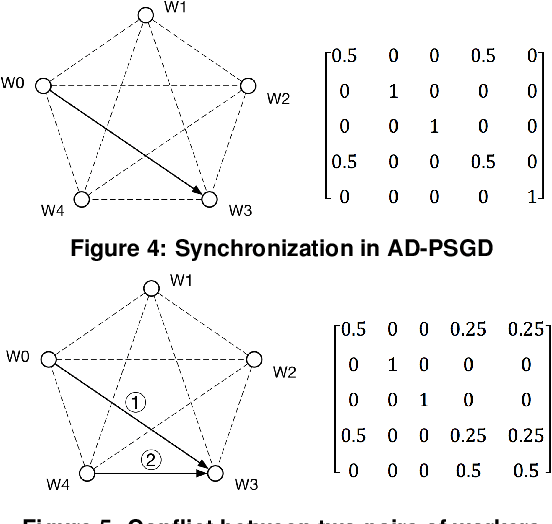
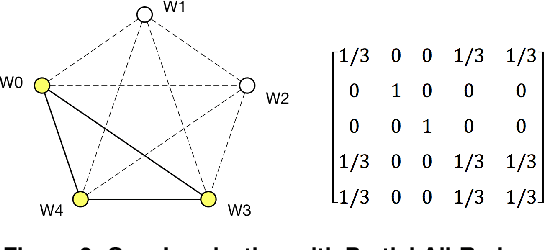
Distributed deep learning training usually adopts All-Reduce as the synchronization mechanism for data parallel algorithms due to its high performance in homogeneous environment. However, its performance is bounded by the slowest worker among all workers, and is significantly slower in heterogeneous situations. AD-PSGD, a newly proposed synchronization method which provides numerically fast convergence and heterogeneity tolerance, suffers from deadlock issues and high synchronization overhead. Is it possible to get the best of both worlds - designing a distributed training method that has both high performance as All-Reduce in homogeneous environment and good heterogeneity tolerance as AD-PSGD? In this paper, we propose Ripples, a high-performance heterogeneity-aware asynchronous decentralized training approach. We achieve the above goal with intensive synchronization optimization, emphasizing the interplay between algorithm and system implementation. To reduce synchronization cost, we propose a novel communication primitive Partial All-Reduce that allows a large group of workers to synchronize quickly. To reduce synchronization conflict, we propose static group scheduling in homogeneous environment and simple techniques (Group Buffer and Group Division) to avoid conflicts with slightly reduced randomness. Our experiments show that in homogeneous environment, Ripples is 1.1 times faster than the state-of-the-art implementation of All-Reduce, 5.1 times faster than Parameter Server and 4.3 times faster than AD-PSGD. In a heterogeneous setting, Ripples shows 2 times speedup over All-Reduce, and still obtains 3 times speedup over the Parameter Server baseline.