 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Jun 03, 2026Rubric-based reinforcement learning (RL) uses an LLM-as-a-Judge (LaaJ) to score model outputs according to rubrics as rewards. However, policy models may exploit latent biases in the judge, leading to reward hacking and ineffective or unsafe training outcomes. In real-world rubric-based RL, such hacking behaviors are often subtle and entangled with multiple judge biases, making them difficult to analyze, detect, and mitigate. In this paper, we introduce CHERRL, a controllable hacking environment for rubric-based RL. By injecting known biases into LaaJ, CHERRL enables stable reproduction of reward hacking, explicit observation of reward divergence, and precise identification of hacking onset. This provides a clean experimental testbed for studying the mechanisms and mitigations of reward hacking in rubric-based RL. To demonstrate its utility, we analyze different judge biases from the perspectives of discoverability and exploitability, and explore an agent-based system for automatically detecting reward hacking onset from training logs. The code and environment are publicly available at https://github.com/THUAIS-Lab/CHERRL.
Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders
May 26, 2026Model internals encode rich information about how a large language model (LLM) processes its training data; however, post-training data engineering largely relies on external signals and ignores rich intrinsic signals lying in model internals. We propose SAERL, a data engineering framework for LLM reinforcement learning (RL). It models three intrinsic data properties: diversity, difficulty, and quality, using model internals extracted with Sparse Autoencoder (SAE), an advanced mechanistic interpretability tool. Each property grounds a concrete data engineering operation: SAE-space clustering with moderate batch mixing for batch diversity control, a difficulty proxy for easy-to-hard curriculum ordering, and a quality probe for data filtering. SAERL improves average accuracy by 3.00% over vanilla GRPO and reaches target accuracy with 20% fewer training steps on Qwen2.5-Math-1.5B, with consistent gains across model scales and RL algorithms. Experiments show that SAE transfers effectively across model families and scales, serving as a lightweight and reusable data engineering tool. These results demonstrate that model internals are a powerful and practical source of signals for post-training data engineering.
StoryAlign: Evaluating and Training Reward Models for Story Generation
May 06, 2026Story generation aims to automatically produce coherent, structured, and engaging narratives. Although large language models (LLMs) have significantly advanced text generation, stories generated by LLMs still diverge from human-authored works regarding complex narrative structure and human-aligned preferences. A key reason is the absence of effective modeling of human story preferences, which are inherently subjective and under-explored. In this work, we systematically evaluate the modeling of human story preferences and introduce StoryRMB, the first benchmark for assessing reward models on story preferences. StoryRMB contains $1,133$ high-quality, human-verified instances, each consisting of a prompt, one chosen story, and three rejected stories. We find existing reward models struggle to select human-preferred stories, with the best model achieving only $66.3\%$ accuracy. To address this limitation, we construct roughly $100,000$ high-quality story preference pairs across diverse domains and develop StoryReward, an advanced reward model for story preference trained on this dataset. StoryReward achieves state-of-the-art (SoTA) performance on StoryRMB, outperforming much larger models. We also adopt StoryReward in downstream test-time scaling applications for best-of-n (BoN) story selection and find that it generally chooses stories better aligned with human preferences. We will release our dataset, model, and code to facilitate future research. Related code and data are available at https://github.com/THU-KEG/StoryReward.
WildReward: Learning Reward Models from In-the-Wild Human Interactions
Feb 09, 2026Reward models (RMs) are crucial for the training of large language models (LLMs), yet they typically rely on large-scale human-annotated preference pairs. With the widespread deployment of LLMs, in-the-wild interactions have emerged as a rich source of implicit reward signals. This raises the question: Can we develop reward models directly from in-the-wild interactions? In this work, we explore this possibility by adopting WildChat as an interaction source and proposing a pipeline to extract reliable human feedback, yielding 186k high-quality instances for training WildReward via ordinal regression directly on user feedback without preference pairs. Extensive experiments demonstrate that WildReward achieves comparable or even superior performance compared to conventional reward models, with improved calibration and cross-sample consistency. We also observe that WildReward benefits directly from user diversity, where more users yield stronger reward models. Finally, we apply WildReward to online DPO training and observe significant improvements across various tasks. Code and data are released at https://github.com/THU-KEG/WildReward.
On the Paradoxical Interference between Instruction-Following and Task Solving
Jan 29, 2026Instruction following aims to align Large Language Models (LLMs) with human intent by specifying explicit constraints on how tasks should be performed. However, we reveal a counterintuitive phenomenon: instruction following can paradoxically interfere with LLMs' task-solving capability. We propose a metric, SUSTAINSCORE, to quantify the interference of instruction following with task solving. It measures task performance drop after inserting into the instruction a self-evident constraint, which is naturally met by the original successful model output and extracted from it. Experiments on current LLMs in mathematics, multi-hop QA, and code generation show that adding the self-evident constraints leads to substantial performance drops, even for advanced models such as Claude-Sonnet-4.5. We validate the generality of the interference across constraint types and scales. Furthermore, we identify common failure patterns, and by investigating the mechanisms of interference, we observe that failed cases allocate significantly more attention to constraints compared to successful ones. Finally, we use SUSTAINSCORE to conduct an initial investigation into how distinct post-training paradigms affect the interference, presenting empirical observations on current alignment strategies. We will release our code and data to facilitate further research
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
Jun 11, 2025Reinforcement learning with verifiable rewards (RLVR) has become a key technique for enhancing large language models (LLMs), with verification engineering playing a central role. However, best practices for RL in instruction following remain underexplored. In this work, we explore the verification challenge in RL for instruction following and propose VerIF, a verification method that combines rule-based code verification with LLM-based verification from a large reasoning model (e.g., QwQ-32B). To support this approach, we construct a high-quality instruction-following dataset, VerInstruct, containing approximately 22,000 instances with associated verification signals. We apply RL training with VerIF to two models, achieving significant improvements across several representative instruction-following benchmarks. The trained models reach state-of-the-art performance among models of comparable size and generalize well to unseen constraints. We further observe that their general capabilities remain unaffected, suggesting that RL with VerIF can be integrated into existing RL recipes to enhance overall model performance. We have released our datasets, codes, and models to facilitate future research at https://github.com/THU-KEG/VerIF.
AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios
May 22, 2025Large Language Models (LLMs) have demonstrated advanced capabilities in real-world agentic applications. Growing research efforts aim to develop LLM-based agents to address practical demands, introducing a new challenge: agentic scenarios often involve lengthy instructions with complex constraints, such as extended system prompts and detailed tool specifications. While adherence to such instructions is crucial for agentic applications, whether LLMs can reliably follow them remains underexplored. In this paper, we introduce AgentIF, the first benchmark for systematically evaluating LLM instruction following ability in agentic scenarios. AgentIF features three key characteristics: (1) Realistic, constructed from 50 real-world agentic applications. (2) Long, averaging 1,723 words with a maximum of 15,630 words. (3) Complex, averaging 11.9 constraints per instruction, covering diverse constraint types, such as tool specifications and condition constraints. To construct AgentIF, we collect 707 human-annotated instructions across 50 agentic tasks from industrial application agents and open-source agentic systems. For each instruction, we annotate the associated constraints and corresponding evaluation metrics, including code-based evaluation, LLM-based evaluation, and hybrid code-LLM evaluation. We use AgentIF to systematically evaluate existing advanced LLMs. We observe that current models generally perform poorly, especially in handling complex constraint structures and tool specifications. We further conduct error analysis and analytical experiments on instruction length and meta constraints, providing some findings about the failure modes of existing LLMs. We have released the code and data to facilitate future research.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025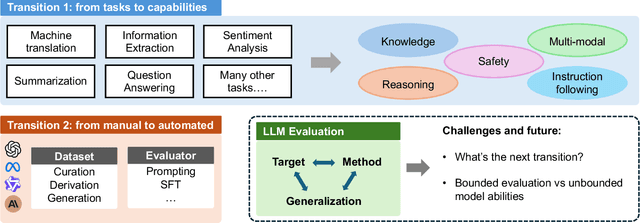
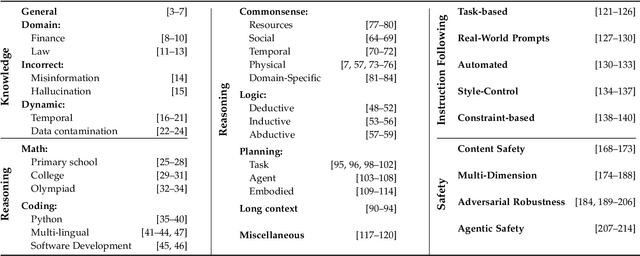
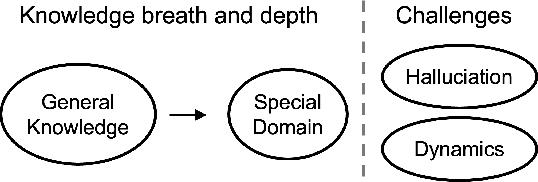
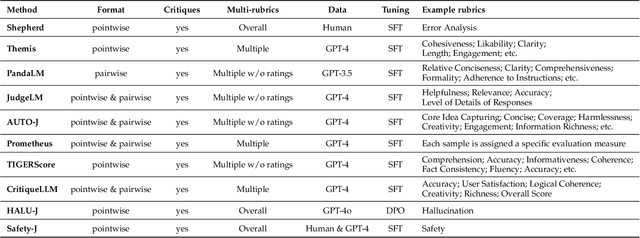
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
Precise Localization of Memories: A Fine-grained Neuron-level Knowledge Editing Technique for LLMs
Mar 03, 2025



Knowledge editing aims to update outdated information in Large Language Models (LLMs). A representative line of study is locate-then-edit methods, which typically employ causal tracing to identify the modules responsible for recalling factual knowledge about entities. However, we find these methods are often sensitive only to changes in the subject entity, leaving them less effective at adapting to changes in relations. This limitation results in poor editing locality, which can lead to the persistence of irrelevant or inaccurate facts, ultimately compromising the reliability of LLMs. We believe this issue arises from the insufficient precision of knowledge localization. To address this, we propose a Fine-grained Neuron-level Knowledge Editing (FiNE) method that enhances editing locality without affecting overall success rates. By precisely identifying and modifying specific neurons within feed-forward networks, FiNE significantly improves knowledge localization and editing. Quantitative experiments demonstrate that FiNE efficiently achieves better overall performance compared to existing techniques, providing new insights into the localization and modification of knowledge within LLMs.
Sparse Auto-Encoder Interprets Linguistic Features in Large Language Models
Feb 27, 2025Large language models (LLMs) excel in tasks that require complex linguistic abilities, such as reference disambiguation and metaphor recognition/generation. Although LLMs possess impressive capabilities, their internal mechanisms for processing and representing linguistic knowledge remain largely opaque. Previous work on linguistic mechanisms has been limited by coarse granularity, insufficient causal analysis, and a narrow focus. In this study, we present a systematic and comprehensive causal investigation using sparse auto-encoders (SAEs). We extract a wide range of linguistic features from six dimensions: phonetics, phonology, morphology, syntax, semantics, and pragmatics. We extract, evaluate, and intervene on these features by constructing minimal contrast datasets and counterfactual sentence datasets. We introduce two indices-Feature Representation Confidence (FRC) and Feature Intervention Confidence (FIC)-to measure the ability of linguistic features to capture and control linguistic phenomena. Our results reveal inherent representations of linguistic knowledge in LLMs and demonstrate the potential for controlling model outputs. This work provides strong evidence that LLMs possess genuine linguistic knowledge and lays the foundation for more interpretable and controllable language modeling in future research.