 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-Bench: Benchmarking Self-Evolution with Knowledge Internalization
Feb 04, 2026True self-evolution requires agents to act as lifelong learners that internalize novel experiences to solve future problems. However, rigorously measuring this foundational capability is hindered by two obstacles: the entanglement of prior knowledge, where ``new'' knowledge may appear in pre-training data, and the entanglement of reasoning complexity, where failures may stem from problem difficulty rather than an inability to recall learned knowledge. We introduce SE-Bench, a diagnostic environment that obfuscates the NumPy library and its API doc into a pseudo-novel package with randomized identifiers. Agents are trained to internalize this package and evaluated on simple coding tasks without access to documentation, yielding a clean setting where tasks are trivial with the new API doc but impossible for base models without it. Our investigation reveals three insights: (1) the Open-Book Paradox, where training with reference documentation inhibits retention, requiring "Closed-Book Training" to force knowledge compression into weights; (2) the RL Gap, where standard RL fails to internalize new knowledge completely due to PPO clipping and negative gradients; and (3) the viability of Self-Play for internalization, proving models can learn from self-generated, noisy tasks when coupled with SFT, but not RL. Overall, SE-Bench establishes a rigorous diagnostic platform for self-evolution with knowledge internalization. Our code and dataset can be found at https://github.com/thunlp/SE-Bench.
CPMobius: Iterative Coach-Player Reasoning for Data-Free Reinforcement Learning
Feb 03, 2026Large Language Models (LLMs) have demonstrated strong potential in complex reasoning, yet their progress remains fundamentally constrained by reliance on massive high-quality human-curated tasks and labels, either through supervised fine-tuning (SFT) or reinforcement learning (RL) on reasoning-specific data. This dependence renders supervision-heavy training paradigms increasingly unsustainable, with signs of diminishing scalability already evident in practice. To overcome this limitation, we introduce CPMöbius (CPMobius), a collaborative Coach-Player paradigm for data-free reinforcement learning of reasoning models. Unlike traditional adversarial self-play, CPMöbius, inspired by real world human sports collaboration and multi-agent collaboration, treats the Coach and Player as independent but cooperative roles. The Coach proposes instructions targeted at the Player's capability and receives rewards based on changes in the Player's performance, while the Player is rewarded for solving the increasingly instructive tasks generated by the Coach. This cooperative optimization loop is designed to directly enhance the Player's mathematical reasoning ability. Remarkably, CPMöbius achieves substantial improvement without relying on any external training data, outperforming existing unsupervised approaches. For example, on Qwen2.5-Math-7B-Instruct, our method improves accuracy by an overall average of +4.9 and an out-of-distribution average of +5.4, exceeding RENT by +1.5 on overall accuracy and R-zero by +4.2 on OOD accuracy.
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
Dec 18, 2025Recent advances in reinforcement learning for large language models have converged on increasing complexity: multi-stage training pipelines, dynamic hyperparameter schedules, and curriculum learning strategies. This raises a fundamental question: \textbf{Is this complexity necessary?} We present \textbf{JustRL}, a minimal approach using single-stage training with fixed hyperparameters that achieves state-of-the-art performance on two 1.5B reasoning models (54.9\% and 64.3\% average accuracy across nine mathematical benchmarks) while using 2$\times$ less compute than sophisticated approaches. The same hyperparameters transfer across both models without tuning, and training exhibits smooth, monotonic improvement over 4,000+ steps without the collapses or plateaus that typically motivate interventions. Critically, ablations reveal that adding ``standard tricks'' like explicit length penalties and robust verifiers may degrade performance by collapsing exploration. These results suggest that the field may be adding complexity to solve problems that disappear with a stable, scaled-up baseline. We release our models and code to establish a simple, validated baseline for the community.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Cross-Task Experiential Learning on LLM-based Multi-Agent Collaboration
May 29, 2025Large Language Model-based multi-agent systems (MAS) have shown remarkable progress in solving complex tasks through collaborative reasoning and inter-agent critique. However, existing approaches typically treat each task in isolation, resulting in redundant computations and limited generalization across structurally similar tasks. To address this, we introduce multi-agent cross-task experiential learning (MAEL), a novel framework that endows LLM-driven agents with explicit cross-task learning and experience accumulation. We model the task-solving workflow on a graph-structured multi-agent collaboration network, where agents propagate information and coordinate via explicit connectivity. During the experiential learning phase, we quantify the quality for each step in the task-solving workflow and store the resulting rewards along with the corresponding inputs and outputs into each agent's individual experience pool. During inference, agents retrieve high-reward, task-relevant experiences as few-shot examples to enhance the effectiveness of each reasoning step, thereby enabling more accurate and efficient multi-agent collaboration. Experimental results on diverse datasets demonstrate that MAEL empowers agents to learn from prior task experiences effectively-achieving faster convergence and producing higher-quality solutions on current tasks.
Co-Saving: Resource Aware Multi-Agent Collaboration for Software Development
May 28, 2025Recent advancements in Large Language Models (LLMs) and autonomous agents have demonstrated remarkable capabilities across various domains. However, standalone agents frequently encounter limitations when handling complex tasks that demand extensive interactions and substantial computational resources. Although Multi-Agent Systems (MAS) alleviate some of these limitations through collaborative mechanisms like task decomposition, iterative communication, and role specialization, they typically remain resource-unaware, incurring significant inefficiencies due to high token consumption and excessive execution time. To address these limitations, we propose a resource-aware multi-agent system -- Co-Saving (meaning that multiple agents collaboratively engage in resource-saving activities), which leverages experiential knowledge to enhance operational efficiency and solution quality. Our key innovation is the introduction of "shortcuts" -- instructional transitions learned from historically successful trajectories -- which allows to bypass redundant reasoning agents and expedite the collective problem-solving process. Experiments for software development tasks demonstrate significant advantages over existing methods. Specifically, compared to the state-of-the-art MAS ChatDev, our method achieves an average reduction of 50.85% in token usage, and improves the overall code quality by 10.06%.
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
May 28, 2025



This paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
Multi-Agent Collaboration via Evolving Orchestration
May 26, 2025



Large language models (LLMs) have achieved remarkable results across diverse downstream tasks, but their monolithic nature restricts scalability and efficiency in complex problem-solving. While recent research explores multi-agent collaboration among LLMs, most approaches rely on static organizational structures that struggle to adapt as task complexity and agent numbers grow, resulting in coordination overhead and inefficiencies. To this end, we propose a puppeteer-style paradigm for LLM-based multi-agent collaboration, where a centralized orchestrator ("puppeteer") dynamically directs agents ("puppets") in response to evolving task states. This orchestrator is trained via reinforcement learning to adaptively sequence and prioritize agents, enabling flexible and evolvable collective reasoning. Experiments on closed- and open-domain scenarios show that this method achieves superior performance with reduced computational costs. Analyses further reveal that the key improvements consistently stem from the emergence of more compact, cyclic reasoning structures under the orchestrator's evolution.
The Overthinker's DIET: Cutting Token Calories with DIfficulty-AwarE Training
May 25, 2025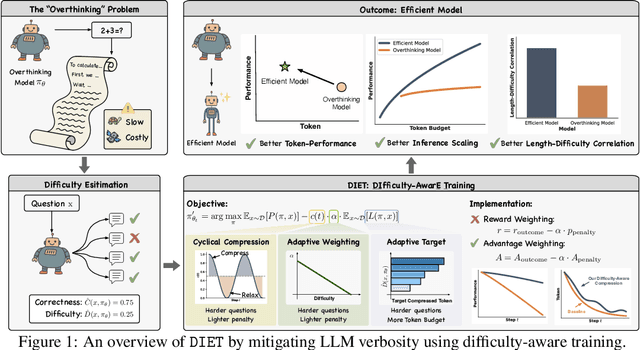



Recent large language models (LLMs) exhibit impressive reasoning but often over-think, generating excessively long responses that hinder efficiency. We introduce DIET ( DIfficulty-AwarE Training), a framework that systematically cuts these "token calories" by integrating on-the-fly problem difficulty into the reinforcement learning (RL) process. DIET dynamically adapts token compression strategies by modulating token penalty strength and conditioning target lengths on estimated task difficulty, to optimize the performance-efficiency trade-off. We also theoretically analyze the pitfalls of naive reward weighting in group-normalized RL algorithms like GRPO, and propose Advantage Weighting technique, which enables stable and effective implementation of these difficulty-aware objectives. Experimental results demonstrate that DIET significantly reduces token counts while simultaneously improving reasoning performance. Beyond raw token reduction, we show two crucial benefits largely overlooked by prior work: (1) DIET leads to superior inference scaling. By maintaining high per-sample quality with fewer tokens, it enables better scaling performance via majority voting with more samples under fixed computational budgets, an area where other methods falter. (2) DIET enhances the natural positive correlation between response length and problem difficulty, ensuring verbosity is appropriately allocated, unlike many existing compression methods that disrupt this relationship. Our analyses provide a principled and effective framework for developing more efficient, practical, and high-performing LLMs.
AgentRM: Enhancing Agent Generalization with Reward Modeling
Feb 25, 2025Existing LLM-based agents have achieved strong performance on held-in tasks, but their generalizability to unseen tasks remains poor. Hence, some recent work focus on fine-tuning the policy model with more diverse tasks to improve the generalizability. In this work, we find that finetuning a reward model to guide the policy model is more robust than directly finetuning the policy model. Based on this finding, we propose AgentRM, a generalizable reward model, to guide the policy model for effective test-time search. We comprehensively investigate three approaches to construct the reward model, including explicit reward modeling, implicit reward modeling and LLM-as-a-judge. We then use AgentRM to guide the answer generation with Best-of-N sampling and step-level beam search. On four types of nine agent tasks, AgentRM enhances the base policy model by $8.8$ points on average, surpassing the top general agent by $4.0$. Moreover, it demonstrates weak-to-strong generalization, yielding greater improvement of $12.6$ on LLaMA-3-70B policy model. As for the specializability, AgentRM can also boost a finetuned policy model and outperform the top specialized agent by $11.4$ on three held-in tasks. Further analysis verifies its effectiveness in test-time scaling. Codes will be released to facilitate the research in this area.