 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes a Strong Model? A Unified Spectral Analysis of Knowledge Transfer over High-dimensional Linear Regression
May 31, 2026Teacher-Student Knowledge Transfer (KT) is ubiquitous in modern machine learning, ranging from classical model compression via Knowledge Distillation (KD) to the emergent phenomenon of Weak-to-Strong (W2S) generalization. While existing studies offer isolated insights, a unified theoretical framework explaining the efficacy of KT across these disparate regimes remains lacking. In this work, we establish a unified spectral analysis of SGD dynamics in high-dimensional linear regression, elucidating the efficiency of KT across seemingly disparate regimes. We characterize KT efficiency through two distinct mechanisms: \emph{Spectral Horizon Expansion} in KD, which enables the capture of statistically inaccessible high-frequency signals, and \emph{Spectral Denoising} in W2S, where the student acts as a filter for optimization noise. Our framework unifies these phenomena, revealing that the efficacy of transfer is governed by the interplay between implicit regularization and heterogeneous spectral learning speeds over the spectrum.
SPHERE: Mitigating the Loss of Spectral Plasticity in Mixture-of-Experts for Deep Reinforcement Learning
May 06, 2026In deep reinforcement learning (DRL), an agent is trained from a stream of experience. In a continual learning setting, such agents can suffer from plasticity loss: their ability to learn new skills from new experiences diminishes over training. Recently, Mixture-of-Experts (MoE) networks have been reported to enable scaling laws and facilitate the learning of diverse skills. However, in continual reinforcement learning settings, their performance can degenerate as learning proceeds, indicating a loss of plasticity. To address this, building on Neural Tangent Kernel (NTK) theory, we formalize the plasticity loss in MoE policies as a loss of spectral plasticity. We then derive a tractable proxy for spectral plasticity, one expressible in terms of individual expert feature matrices. Leveraging this proxy, we introduce SPHERE, a practical Parseval penalty tailored for MoE-based policies that alleviates the loss of spectral plasticity. On MetaWorld and HumanoidBench, SPHERE improves average success under continual RL by 133% and 50% over an unregularized MoE baseline, while maintaining higher spectral plasticity throughout training.
Mild Over-Parameterization Benefits Asymmetric Tensor PCA
Apr 11, 2026Asymmetric Tensor PCA (ATPCA) is a prototypical model for studying the trade-offs between sample complexity, computation, and memory. Existing algorithms for this problem typically require at least $d^{\left\lceil\overline{k}/2\right\rceil}$ state memory cost to recover the signal, where $d$ is the vector dimension and $\overline{k}$ is the tensor order. We focus on the setting where $\overline{k} \geq 4$ is even and consider (stochastic) gradient descent-based algorithms under a limited memory budget, which permits only mild over-parameterization of the model. We propose a matrix-parameterized method (in $d^{2}$ state memory cost) using a novel three-phase alternating-update algorithm to address the problem and demonstrate how mild over-parameterization facilitates learning in two key aspects: (i) it improves sample efficiency, allowing our method to achieve \emph{near-optimal} $d^{\overline{k}-2}$ sample complexity in our limited memory setting; and (ii) it enhances adaptivity to problem structure, a previously unrecognized phenomenon, where the required sample size naturally decreases as consecutive vectors become more aligned, and in the symmetric limit attains $d^{\overline{k}/2}$, matching the \emph{best} known polynomial-time complexity. To our knowledge, this is the \emph{first} tractable algorithm for ATPCA with $d^{\overline{k}}$-independent memory costs.
MVR: Multi-view Video Reward Shaping for Reinforcement Learning
Mar 02, 2026Reward design is of great importance for solving complex tasks with reinforcement learning. Recent studies have explored using image-text similarity produced by vision-language models (VLMs) to augment rewards of a task with visual feedback. A common practice linearly adds VLM scores to task or success rewards without explicit shaping, potentially altering the optimal policy. Moreover, such approaches, often relying on single static images, struggle with tasks whose desired behavior involves complex, dynamic motions spanning multiple visually different states. Furthermore, single viewpoints can occlude critical aspects of an agent's behavior. To address these issues, this paper presents Multi-View Video Reward Shaping (MVR), a framework that models the relevance of states regarding the target task using videos captured from multiple viewpoints. MVR leverages video-text similarity from a frozen pre-trained VLM to learn a state relevance function that mitigates the bias towards specific static poses inherent in image-based methods. Additionally, we introduce a state-dependent reward shaping formulation that integrates task-specific rewards and VLM-based guidance, automatically reducing the influence of VLM guidance once the desired motion pattern is achieved. We confirm the efficacy of the proposed framework with extensive experiments on challenging humanoid locomotion tasks from HumanoidBench and manipulation tasks from MetaWorld, verifying the design choices through ablation studies.
Accelerating Single-Pass SGD for Generalized Linear Prediction
Mar 02, 2026We study generalized linear prediction under a streaming setting, where each iteration uses only one fresh data point for a gradient-level update. While momentum is well-established in deterministic optimization, a fundamental open question is whether it can accelerate such single-pass non-quadratic stochastic optimization. We propose the first algorithm that successfully incorporates momentum via a novel data-dependent proximal method, achieving dual-momentum acceleration. Our derived excess risk bound decomposes into three components: an improved optimization error, a minimax optimal statistical error, and a higher-order model-misspecification error. The proof handles mis-specification via a fine-grained stationary analysis of inner updates, while localizing statistical error through a two-phase outer-loop analysis. As a result, we resolve the open problem posed by Jain et al. [2018a] and demonstrate that momentum acceleration is more effective than variance reduction for generalized linear prediction in the streaming setting.
PRAC: Principal-Random Subspace for LLM Activation Compression and Memory-Efficient Training
Feb 26, 2026Activations have become the primary memory bottleneck in large-batch LLM training. However, existing compression methods fail to exploit the spectral structure of activations, resulting in slow convergence or limited compression. To address this, we bridge the relationship between the algorithm's fast convergence and the requirements for subspace projection, and show that an effective compression should yield an unbiased estimate of the original activation with low variance. We propose Principal-Random Subspace for LLM Activation Compression (PRAC), which novelly decomposes activations into two components: a principal subspace captured via SVD to retain dominant information, and a random subspace sampled from the orthogonal complement to approximate the tail. By introducing a precise scaling factor, we prove that PRAC yields an unbiased gradient estimator with minimum variance under certain conditions. Extensive experiments on pre-training and fine-tuning tasks demonstrate that PRAC achieves up to 36% total memory reduction with negligible performance degradation and minimal computational cost.
Partial Feedback Online Learning
Jan 29, 2026We study partial-feedback online learning, where each instance admits a set of correct labels, but the learner only observes one correct label per round; any prediction within the correct set is counted as correct. This model captures settings such as language generation, where multiple responses may be valid but data provide only a single reference. We give a near-complete characterization of minimax regret for both deterministic and randomized learners in the set-realizable regime, i.e., in the regime where sublinear regret is generally attainable. For deterministic learners, we introduce the Partial-Feedback Littlestone dimension (PFLdim) and show it precisely governs learnability and minimax regret; technically, PFLdim cannot be defined via the standard version space, requiring a new collection version space viewpoint and an auxiliary dimension used only in the proof. We further develop the Partial-Feedback Measure Shattering dimension (PMSdim) to obtain tight bounds for randomized learners. We identify broad conditions ensuring inseparability between deterministic and randomized learnability (e.g., finite Helly number or nested-inclusion label structure), and extend the argument to set-valued online learning, resolving an open question of Raman et al. [2024b]. Finally, we show a sharp separation from weaker realistic and agnostic variants: outside set realizability, the problem can become information-theoretically intractable, with linear regret possible even for $|H|=2$. This highlights the need for fundamentally new, noise-sensitive complexity measures to meaningfully characterize learnability beyond set realizability.
Learning Curves of Stochastic Gradient Descent in Kernel Regression
May 28, 2025

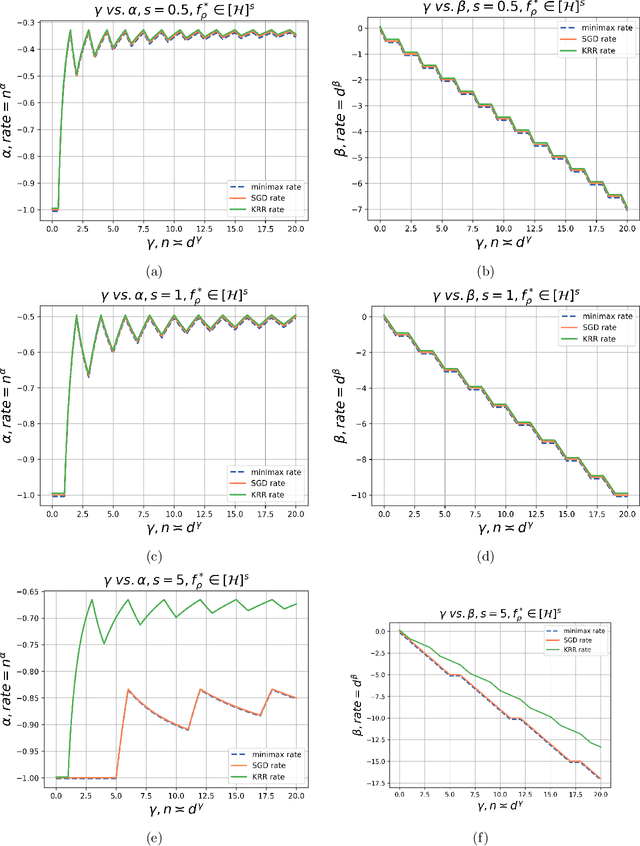
This paper considers a canonical problem in kernel regression: how good are the model performances when it is trained by the popular online first-order algorithms, compared to the offline ones, such as ridge and ridgeless regression? In this paper, we analyze the foundational single-pass Stochastic Gradient Descent (SGD) in kernel regression under source condition where the optimal predictor can even not belong to the RKHS, i.e. the model is misspecified. Specifically, we focus on the inner product kernel over the sphere and characterize the exact orders of the excess risk curves under different scales of sample sizes $n$ concerning the input dimension $d$. Surprisingly, we show that SGD achieves min-max optimal rates up to constants among all the scales, without suffering the saturation, a prevalent phenomenon observed in (ridge) regression, except when the model is highly misspecified and the learning is in a final stage where $n\gg d^{\gamma}$ with any constant $\gamma >0$. The main reason for SGD to overcome the curse of saturation is the exponentially decaying step size schedule, a common practice in deep neural network training. As a byproduct, we provide the \emph{first} provable advantage of the scheme over the iterative averaging method in the common setting.
Optimal Algorithms in Linear Regression under Covariate Shift: On the Importance of Precondition
Feb 13, 2025A common pursuit in modern statistical learning is to attain satisfactory generalization out of the source data distribution (OOD). In theory, the challenge remains unsolved even under the canonical setting of covariate shift for the linear model. This paper studies the foundational (high-dimensional) linear regression where the ground truth variables are confined to an ellipse-shape constraint and addresses two fundamental questions in this regime: (i) given the target covariate matrix, what is the min-max \emph{optimal} algorithm under covariate shift? (ii) for what kinds of target classes, the commonly-used SGD-type algorithms achieve optimality? Our analysis starts with establishing a tight lower generalization bound via a Bayesian Cramer-Rao inequality. For (i), we prove that the optimal estimator can be simply a certain linear transformation of the best estimator for the source distribution. Given the source and target matrices, we show that the transformation can be efficiently computed via a convex program. The min-max optimal analysis for SGD leverages the idea that we recognize both the accumulated updates of the applied algorithms and the ideal transformation as preconditions on the learning variables. We provide sufficient conditions when SGD with its acceleration variants attain optimality.
Scaling Law for Stochastic Gradient Descent in Quadratically Parameterized Linear Regression
Feb 13, 2025

In machine learning, the scaling law describes how the model performance improves with the model and data size scaling up. From a learning theory perspective, this class of results establishes upper and lower generalization bounds for a specific learning algorithm. Here, the exact algorithm running using a specific model parameterization often offers a crucial implicit regularization effect, leading to good generalization. To characterize the scaling law, previous theoretical studies mainly focus on linear models, whereas, feature learning, a notable process that contributes to the remarkable empirical success of neural networks, is regretfully vacant. This paper studies the scaling law over a linear regression with the model being quadratically parameterized. We consider infinitely dimensional data and slope ground truth, both signals exhibiting certain power-law decay rates. We study convergence rates for Stochastic Gradient Descent and demonstrate the learning rates for variables will automatically adapt to the ground truth. As a result, in the canonical linear regression, we provide explicit separations for generalization curves between SGD with and without feature learning, and the information-theoretical lower bound that is agnostic to parametrization method and the algorithm. Our analysis for decaying ground truth provides a new characterization for the learning dynamic of the model.