 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolycubeNet: A Dual-latent Diffusion Model for Polycube-Based Hexahedral Mesh Generation
May 19, 2026Hexahedral meshes are widely used in simulation pipelines, yet automatic generation remains challenging for complex CAD geometries. Polycube-based hexahedral meshing is a representative approach due to its regular, parameterization-friendly structure, but existing polycube construction methods often rely on intricate surface segmentation and local heuristics, which can produce artifacts or fail on difficult shapes. In this paper, we propose an end-to-end framework for polycube generation based on conditional diffusion models. Given an input geometry represented as a point cloud, our method directly produces a corresponding polycube point cloud, eliminating the need for explicit surface segmentation or predefined polycube templates. At the core of our approach is a dual-latent conditional diffusion architecture that confines computationally expensive self-attention operations to a fixed-capacity, low-dimensional latent space. This design effectively decouples computational complexity from the resolution of both the input geometry and the output polycube, thereby avoiding the quadratic cost typical of point cloud self-attention mechanisms while supporting flexible input and output resolutions. To obtain a hexahedral mesh, the generated polycube is aligned to the input shape via rigid and non-rigid point cloud registration to establish surface correspondence, followed by a polycube-to-hex pipeline. We additionally create and release a paired dataset of CAD meshes and their corresponding polycube meshes, together with the core implementation of our model. Experiments show that PolycubeNet generalizes to complex CAD models with arbitrary genus and produces high-quality polycube structures within seconds, improving robustness and efficiency over prior learning-based approaches.
TREX: Automating LLM Fine-tuning via Agent-Driven Tree-based Exploration
Apr 15, 2026While Large Language Models (LLMs) have empowered AI research agents to perform isolated scientific tasks, automating complex, real-world workflows, such as LLM training, remains a significant challenge. In this paper, we introduce TREX, a multi-agent system that automates the entire LLM training life-cycle. By orchestrating collaboration between two core modules-the Researcher and the Executor-the system seamlessly performs requirement analysis, open-domain literature and data research, formulation of training strategies, preparation of data recipes, and model training and evaluation. The multi-round experimental process is modeled as a search tree, enabling the system to efficiently plan exploration paths, reuse historical results, and distill high-level insights from iterative trials. To evaluate the capability of automated LLM training, we construct FT-Bench, a benchmark comprising 10 tasks derived from real-world scenarios, ranging from optimizing fundamental model capabilities to enhancing performance on domain-specific tasks. Experimental results demonstrate that the TREX agent consistently optimizes model performance on target tasks.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Calculating Question Similarity is Enough:A New Method for KBQA Tasks
Nov 15, 2021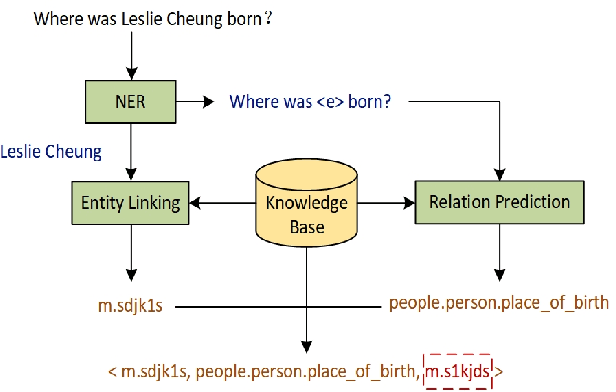
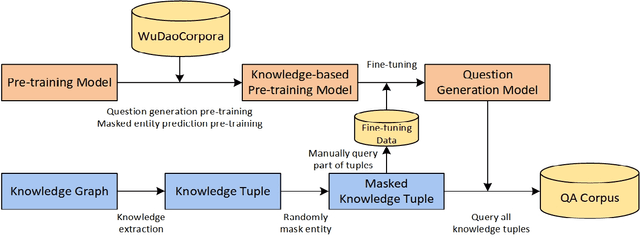

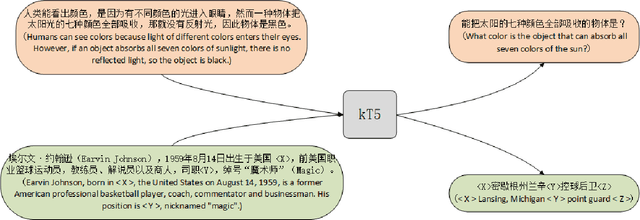
Knowledge Base Question Answering (KBQA) aims to answer natural language questions with the help of an external knowledge base. The core idea is to find the link between the internal knowledge behind questions and known triples of the knowledge base. The KBQA task pipeline contains several steps, including entity recognition, relationship extraction, and entity linking. This kind of pipeline method means that errors in any procedure will inevitably propagate to the final prediction. In order to solve the above problem, this paper proposes a Corpus Generation - Retrieve Method (CGRM) with Pre-training Language Model (PLM) and Knowledge Graph (KG). Firstly, based on the mT5 model, we designed two new pre-training tasks: knowledge masked language modeling and question generation based on the paragraph to obtain the knowledge enhanced T5 (kT5) model. Secondly, after preprocessing triples of knowledge graph with a series of heuristic rules, the kT5 model generates natural language QA pairs based on processed triples. Finally, we directly solve the QA by retrieving the synthetic dataset. We test our method on NLPCC-ICCPOL 2016 KBQA dataset, and the results show that our framework improves the performance of KBQA and the out straight-forward method is competitive with the state-of-the-art.