 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Mixture-of-Experts Architecture for Pre-trained Language Models
Paper and Code
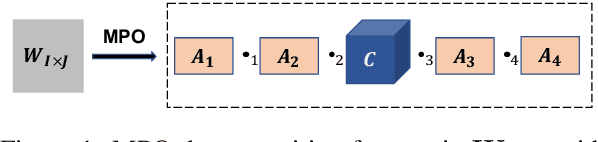
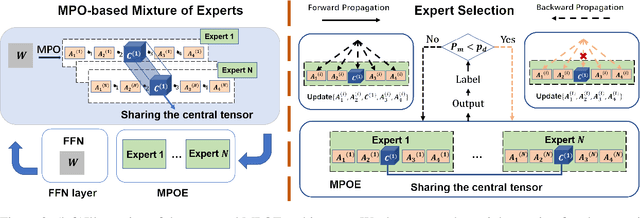
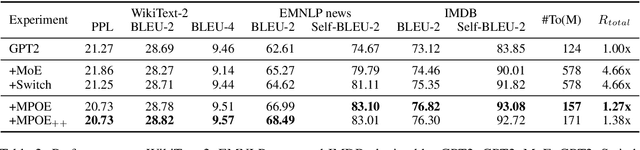
The state-of-the-art Mixture-of-Experts (short as MoE) architecture has achieved several remarkable successes in terms of increasing model capacity. However, MoE has been hindered widespread adoption due to complexity, communication costs, and training instability. Here we present a novel MoE architecture based on matrix product operators (MPO) from quantum many-body physics. It can decompose an original matrix into central tensors (containing the core information) and auxiliary tensors (with only a small proportion of parameters). With the decomposed MPO structure, we can reduce the parameters of the original MoE architecture by sharing a global central tensor across experts and keeping expert-specific auxiliary tensors. We also design the gradient mask strategy for the tensor structure of MPO to alleviate the overfitting problem. Experiments on the three well-known downstream natural language datasets based on GPT2 show improved performance and efficiency in increasing model capacity (7.26x fewer parameters with the same amount of experts). We additionally demonstrate an improvement in the positive transfer effects of our approach for multi-task learning.