 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Experiential Learning for Language Models
Mar 17, 2026The prevailing paradigm for improving large language models relies on offline training with human annotations or simulated environments, leaving the rich experience accumulated during real-world deployment entirely unexploited. We propose Online Experiential Learning (OEL), a framework that enables language models to continuously improve from their own deployment experience. OEL operates in two stages: first, transferable experiential knowledge is extracted and accumulated from interaction trajectories collected on the user side; second, this knowledge is consolidated into model parameters via on-policy context distillation, requiring no access to the user-side environment. The two stages are iterated to form an online learning loop, where the improved model collects higher-quality trajectories that yield richer experiential knowledge for subsequent rounds. We evaluate OEL on text-based game environments across multiple model scales and both thinking and non-thinking variants. OEL achieves consistent improvements over successive iterations, enhancing both task accuracy and token efficiency while preserving out-of-distribution performance. Our analysis further shows that extracted experiential knowledge is significantly more effective than raw trajectories, and that on-policy consistency between the knowledge source and the policy model is critical for effective learning.
Decoding in Geometry: Alleviating Embedding-Space Crowding for Complex Reasoning
Jan 30, 2026Sampling-based decoding underlies complex reasoning in large language models (LLMs), where decoding strategies critically shape model behavior. Temperature- and truncation-based methods reshape the next-token distribution through global probability reweighting or thresholding to balance the quality-diversity tradeoff. However, they operate solely on token probabilities, ignoring fine-grained relationships among tokens in the embedding space. We uncover a novel phenomenon, embedding-space crowding, where the next-token distribution concentrates its probability mass on geometrically close tokens in the embedding space. We quantify crowding at multiple granularities and find a statistical association with reasoning success in mathematical problem solving. Motivated by this finding, we propose CraEG, a plug-and-play sampling method that mitigates crowding through geometry-guided reweighting. CraEG is training-free, single-pass, and compatible with standard sampling strategies. Experiments on multiple models and benchmarks demonstrate improved generation performance, with gains in robustness and diversity metrics.
Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge
Jan 13, 2026Large language models often solve complex reasoning tasks more effectively with Chain-of-Thought (CoT), but at the cost of long, low-bandwidth token sequences. Humans, by contrast, often reason softly by maintaining a distribution over plausible next steps. Motivated by this, we propose Multiplex Thinking, a stochastic soft reasoning mechanism that, at each thinking step, samples K candidate tokens and aggregates their embeddings into a single continuous multiplex token. This preserves the vocabulary embedding prior and the sampling dynamics of standard discrete generation, while inducing a tractable probability distribution over multiplex rollouts. Consequently, multiplex trajectories can be directly optimized with on-policy reinforcement learning (RL). Importantly, Multiplex Thinking is self-adaptive: when the model is confident, the multiplex token is nearly discrete and behaves like standard CoT; when it is uncertain, it compactly represents multiple plausible next steps without increasing sequence length. Across challenging math reasoning benchmarks, Multiplex Thinking consistently outperforms strong discrete CoT and RL baselines from Pass@1 through Pass@1024, while producing shorter sequences. The code and checkpoints are available at https://github.com/GMLR-Penn/Multiplex-Thinking.
The Era of Agentic Organization: Learning to Organize with Language Models
Oct 30, 2025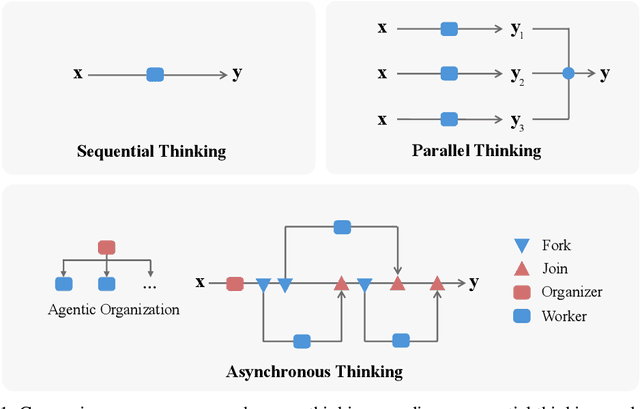

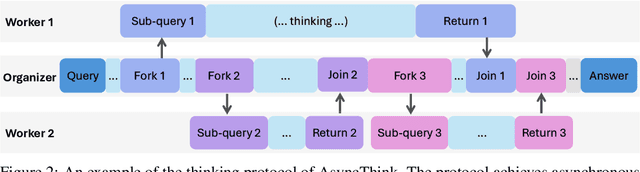
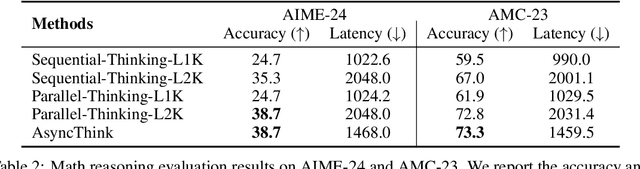
We envision a new era of AI, termed agentic organization, where agents solve complex problems by working collaboratively and concurrently, enabling outcomes beyond individual intelligence. To realize this vision, we introduce asynchronous thinking (AsyncThink) as a new paradigm of reasoning with large language models, which organizes the internal thinking process into concurrently executable structures. Specifically, we propose a thinking protocol where an organizer dynamically assigns sub-queries to workers, merges intermediate knowledge, and produces coherent solutions. More importantly, the thinking structure in this protocol can be further optimized through reinforcement learning. Experiments demonstrate that AsyncThink achieves 28% lower inference latency compared to parallel thinking while improving accuracy on mathematical reasoning. Moreover, AsyncThink generalizes its learned asynchronous thinking capabilities, effectively tackling unseen tasks without additional training.
Reinforcement Pre-Training
Jun 09, 2025



In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a reasoning task trained using RL, where it receives verifiable rewards for correctly predicting the next token for a given context. RPT offers a scalable method to leverage vast amounts of text data for general-purpose RL, rather than relying on domain-specific annotated answers. By incentivizing the capability of next-token reasoning, RPT significantly improves the language modeling accuracy of predicting the next tokens. Moreover, RPT provides a strong pre-trained foundation for further reinforcement fine-tuning. The scaling curves show that increased training compute consistently improves the next-token prediction accuracy. The results position RPT as an effective and promising scaling paradigm to advance language model pre-training.
Think Only When You Need with Large Hybrid-Reasoning Models
May 21, 2025Recent Large Reasoning Models (LRMs) have shown substantially improved reasoning capabilities over traditional Large Language Models (LLMs) by incorporating extended thinking processes prior to producing final responses. However, excessively lengthy thinking introduces substantial overhead in terms of token consumption and latency, which is particularly unnecessary for simple queries. In this work, we introduce Large Hybrid-Reasoning Models (LHRMs), the first kind of model capable of adaptively determining whether to perform thinking based on the contextual information of user queries. To achieve this, we propose a two-stage training pipeline comprising Hybrid Fine-Tuning (HFT) as a cold start, followed by online reinforcement learning with the proposed Hybrid Group Policy Optimization (HGPO) to implicitly learn to select the appropriate thinking mode. Furthermore, we introduce a metric called Hybrid Accuracy to quantitatively assess the model's capability for hybrid thinking. Extensive experimental results show that LHRMs can adaptively perform hybrid thinking on queries of varying difficulty and type. It outperforms existing LRMs and LLMs in reasoning and general capabilities while significantly improving efficiency. Together, our work advocates for a reconsideration of the appropriate use of extended thinking processes and provides a solid starting point for building hybrid thinking systems.
Reward Reasoning Model
May 20, 2025



Reward models play a critical role in guiding large language models toward outputs that align with human expectations. However, an open challenge remains in effectively utilizing test-time compute to enhance reward model performance. In this work, we introduce Reward Reasoning Models (RRMs), which are specifically designed to execute a deliberate reasoning process before generating final rewards. Through chain-of-thought reasoning, RRMs leverage additional test-time compute for complex queries where appropriate rewards are not immediately apparent. To develop RRMs, we implement a reinforcement learning framework that fosters self-evolved reward reasoning capabilities without requiring explicit reasoning traces as training data. Experimental results demonstrate that RRMs achieve superior performance on reward modeling benchmarks across diverse domains. Notably, we show that RRMs can adaptively exploit test-time compute to further improve reward accuracy. The pretrained reward reasoning models are available at https://huggingface.co/Reward-Reasoning.
RICo: Refined In-Context Contribution for Automatic Instruction-Tuning Data Selection
May 18, 2025



Data selection for instruction tuning is crucial for improving the performance of large language models (LLMs) while reducing training costs. In this paper, we propose Refined Contribution Measurement with In-Context Learning (RICo), a novel gradient-free method that quantifies the fine-grained contribution of individual samples to both task-level and global-level model performance. RICo enables more accurate identification of high-contribution data, leading to better instruction tuning. We further introduce a lightweight selection paradigm trained on RICo scores, enabling scalable data selection with a strictly linear inference complexity. Extensive experiments on three LLMs across 12 benchmarks and 5 pairwise evaluation sets demonstrate the effectiveness of RICo. Remarkably, on LLaMA3.1-8B, models trained on 15% of RICo-selected data outperform full datasets by 5.42% points and exceed the best performance of widely used selection methods by 2.06% points. We further analyze high-contribution samples selected by RICo, which show both diverse tasks and appropriate difficulty levels, rather than just the hardest ones.
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
May 16, 2025



Recently, large reasoning models demonstrate exceptional performance on various tasks. However, reasoning models inefficiently over-process both trivial and complex queries, leading to resource waste and prolonged user latency. To address this challenge, we propose SelfBudgeter - a self-adaptive controllable reasoning strategy for efficient reasoning. Our approach adopts a dual-phase training paradigm: first, the model learns to pre-estimate the reasoning cost based on the difficulty of the query. Then, we introduce budget-guided GPRO for reinforcement learning, which effectively maintains accuracy while reducing output length. SelfBudgeter allows users to anticipate generation time and make informed decisions about continuing or interrupting the process. Furthermore, our method enables direct manipulation of reasoning length via pre-filling token budget. Experimental results demonstrate that SelfBudgeter can rationally allocate budgets according to problem complexity, achieving up to 74.47% response length compression on the MATH benchmark while maintaining nearly undiminished accuracy.
ICon: In-Context Contribution for Automatic Data Selection
May 08, 2025Data selection for instruction tuning is essential for improving the performance of Large Language Models (LLMs) and reducing training cost. However, existing automated selection methods either depend on computationally expensive gradient-based measures or manually designed heuristics, which may fail to fully exploit the intrinsic attributes of data. In this paper, we propose In-context Learning for Contribution Measurement (ICon), a novel gradient-free method that takes advantage of the implicit fine-tuning nature of in-context learning (ICL) to measure sample contribution without gradient computation or manual indicators engineering. ICon offers a computationally efficient alternative to gradient-based methods and reduces human inductive bias inherent in heuristic-based approaches. ICon comprises three components and identifies high-contribution data by assessing performance shifts under implicit learning through ICL. Extensive experiments on three LLMs across 12 benchmarks and 5 pairwise evaluation sets demonstrate the effectiveness of ICon. Remarkably, on LLaMA3.1-8B, models trained on 15% of ICon-selected data outperform full datasets by 5.42% points and exceed the best performance of widely used selection methods by 2.06% points. We further analyze high-contribution samples selected by ICon, which show both diverse tasks and appropriate difficulty levels, rather than just the hardest ones.