 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoGain-RAG: Boosting Retrieval-Augmented Generation via Document Information Gain-based Reranking and Filtering
Sep 16, 2025



Retrieval-Augmented Generation (RAG) has emerged as a promising approach to address key limitations of Large Language Models (LLMs), such as hallucination, outdated knowledge, and lacking reference. However, current RAG frameworks often struggle with identifying whether retrieved documents meaningfully contribute to answer generation. This shortcoming makes it difficult to filter out irrelevant or even misleading content, which notably impacts the final performance. In this paper, we propose Document Information Gain (DIG), a novel metric designed to quantify the contribution of retrieved documents to correct answer generation. DIG measures a document's value by computing the difference of LLM's generation confidence with and without the document augmented. Further, we introduce InfoGain-RAG, a framework that leverages DIG scores to train a specialized reranker, which prioritizes each retrieved document from exact distinguishing and accurate sorting perspectives. This approach can effectively filter out irrelevant documents and select the most valuable ones for better answer generation. Extensive experiments across various models and benchmarks demonstrate that InfoGain-RAG can significantly outperform existing approaches, on both single and multiple retrievers paradigm. Specifically on NaturalQA, it achieves the improvements of 17.9%, 4.5%, 12.5% in exact match accuracy against naive RAG, self-reflective RAG and modern ranking-based RAG respectively, and even an average of 15.3% increment on advanced proprietary model GPT-4o across all datasets. These results demonstrate the feasibility of InfoGain-RAG as it can offer a reliable solution for RAG in multiple applications.
TriSampler: A Better Negative Sampling Principle for Dense Retrieval
Feb 19, 2024



Negative sampling stands as a pivotal technique in dense retrieval, essential for training effective retrieval models and significantly impacting retrieval performance. While existing negative sampling methods have made commendable progress by leveraging hard negatives, a comprehensive guiding principle for constructing negative candidates and designing negative sampling distributions is still lacking. To bridge this gap, we embark on a theoretical analysis of negative sampling in dense retrieval. This exploration culminates in the unveiling of the quasi-triangular principle, a novel framework that elucidates the triangular-like interplay between query, positive document, and negative document. Fueled by this guiding principle, we introduce TriSampler, a straightforward yet highly effective negative sampling method. The keypoint of TriSampler lies in its ability to selectively sample more informative negatives within a prescribed constrained region. Experimental evaluation show that TriSampler consistently attains superior retrieval performance across a diverse of representative retrieval models.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
A New Adaptive Gradient Method with Gradient Decomposition
Jul 18, 2021
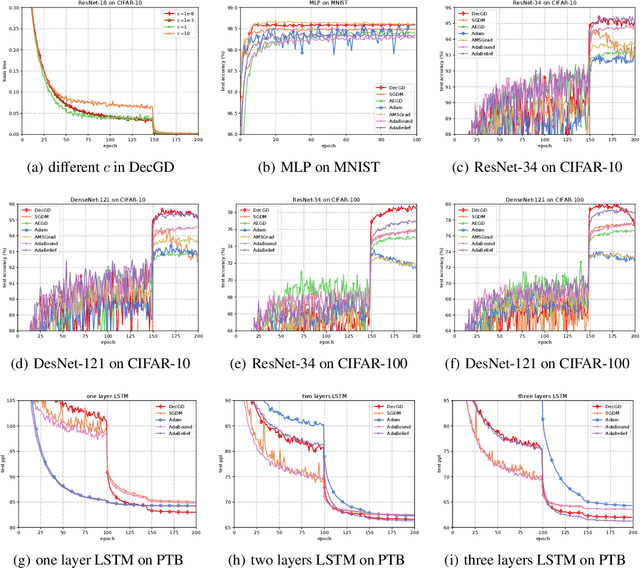

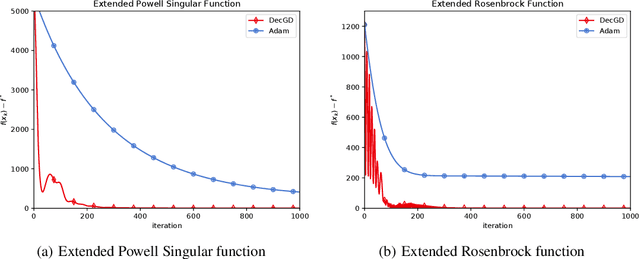
Adaptive gradient methods, especially Adam-type methods (such as Adam, AMSGrad, and AdaBound), have been proposed to speed up the training process with an element-wise scaling term on learning rates. However, they often generalize poorly compared with stochastic gradient descent (SGD) and its accelerated schemes such as SGD with momentum (SGDM). In this paper, we propose a new adaptive method called DecGD, which simultaneously achieves good generalization like SGDM and obtain rapid convergence like Adam-type methods. In particular, DecGD decomposes the current gradient into the product of two terms including a surrogate gradient and a loss based vector. Our method adjusts the learning rates adaptively according to the current loss based vector instead of the squared gradients used in Adam-type methods. The intuition for adaptive learning rates of DecGD is that a good optimizer, in general cases, needs to decrease the learning rates as the loss decreases, which is similar to the learning rates decay scheduling technique. Therefore, DecGD gets a rapid convergence in the early phases of training and controls the effective learning rates according to the loss based vectors which help lead to a better generalization. Convergence analysis is discussed in both convex and non-convex situations. Finally, empirical results on widely-used tasks and models demonstrate that DecGD shows better generalization performance than SGDM and rapid convergence like Adam-type methods.
Turing Award elites revisited: patterns of productivity, collaboration, authorship and impact
Jun 22, 2021

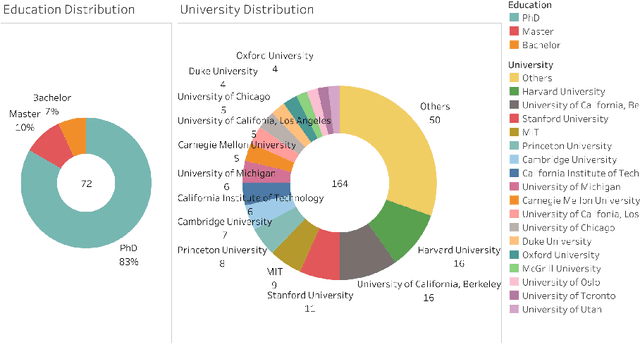

The Turing Award is recognized as the most influential and prestigious award in the field of computer science(CS). With the rise of the science of science (SciSci), a large amount of bibliographic data has been analyzed in an attempt to understand the hidden mechanism of scientific evolution. These include the analysis of the Nobel Prize, including physics, chemistry, medicine, etc. In this article, we extract and analyze the data of 72 Turing Award laureates from the complete bibliographic data, fill the gap in the lack of Turing Award analysis, and discover the development characteristics of computer science as an independent discipline. First, we show most Turing Award laureates have long-term and high-quality educational backgrounds, and more than 61% of them have a degree in mathematics, which indicates that mathematics has played a significant role in the development of computer science. Secondly, the data shows that not all scholars have high productivity and high h-index; that is, the number of publications and h-index is not the leading indicator for evaluating the Turing Award. Third, the average age of awardees has increased from 40 to around 70 in recent years. This may be because new breakthroughs take longer, and some new technologies need time to prove their influence. Besides, we have also found that in the past ten years, international collaboration has experienced explosive growth, showing a new paradigm in the form of collaboration. It is also worth noting that in recent years, the emergence of female winners has also been eye-catching. Finally, by analyzing the personal publication records, we find that many people are more likely to publish high-impact articles during their high-yield periods.
CogView: Mastering Text-to-Image Generation via Transformers
May 28, 2021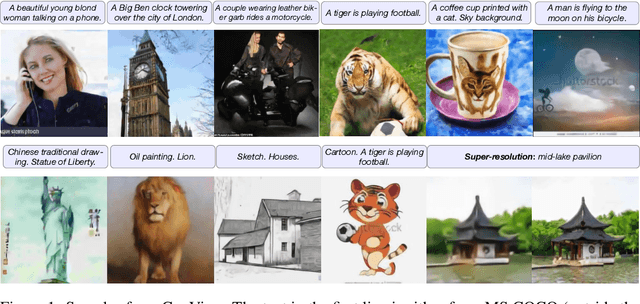
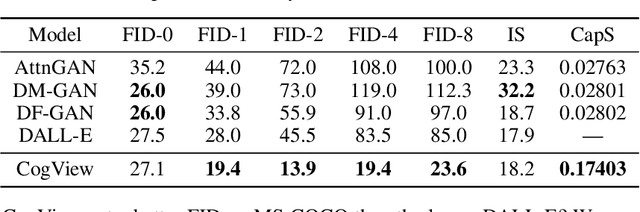
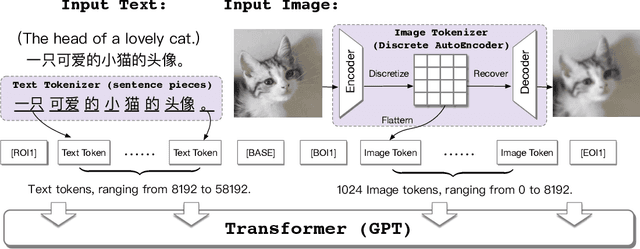
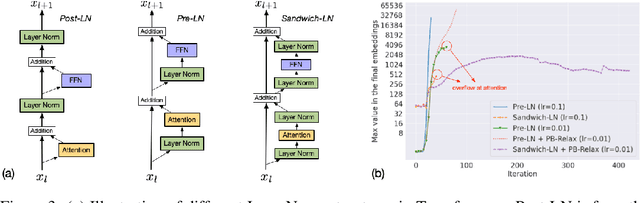
Text-to-Image generation in the general domain has long been an open problem, which requires both a powerful generative model and cross-modal understanding. We propose CogView, a 4-billion-parameter Transformer with VQ-VAE tokenizer to advance this problem. We also demonstrate the finetuning strategies for various downstream tasks, e.g. style learning, super-resolution, text-image ranking and fashion design, and methods to stabilize pretraining, e.g. eliminating NaN losses. CogView (zero-shot) achieves a new state-of-the-art FID on blurred MS COCO, outperforms previous GAN-based models and a recent similar work DALL-E.
Attention: to Better Stand on the Shoulders of Giants
May 27, 2020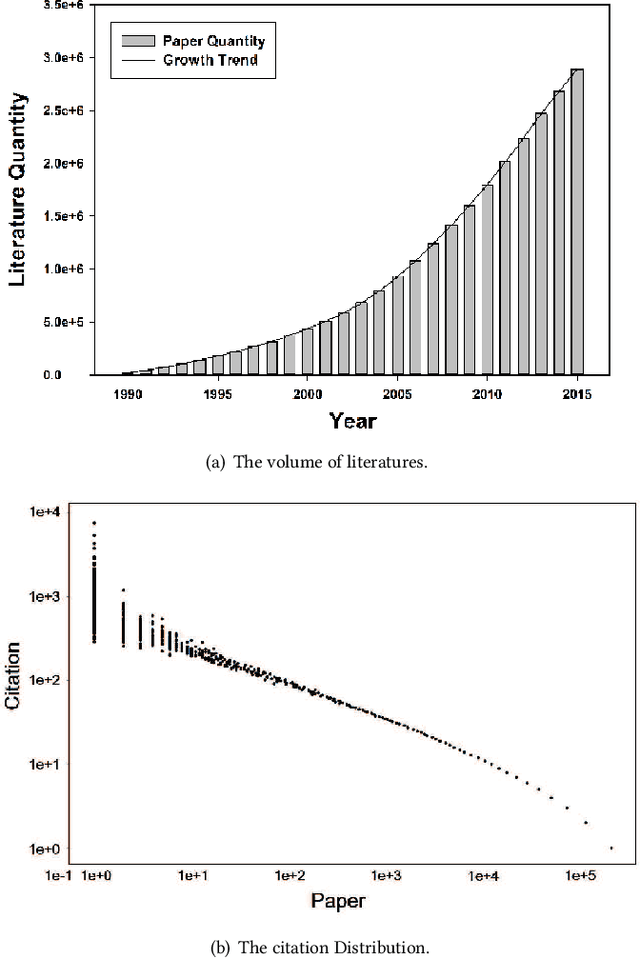
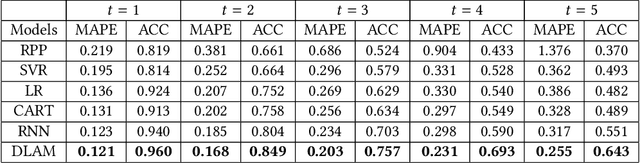

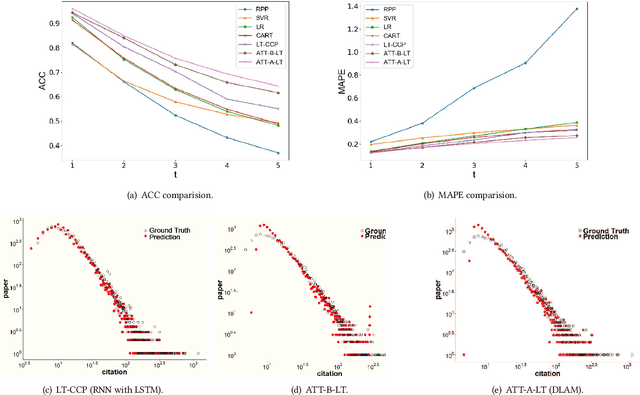
Science of science (SciSci) is an emerging discipline wherein science is used to study the structure and evolution of science itself using large data sets. The increasing availability of digital data on scholarly outcomes offers unprecedented opportunities to explore SciSci. In the progress of science, the previously discovered knowledge principally inspires new scientific ideas, and citation is a reasonably good reflection of this cumulative nature of scientific research. The researches that choose potentially influential references will have a lead over the emerging publications. Although the peer review process is the mainly reliable way of predicting a paper's future impact, the ability to foresee the lasting impact based on citation records is increasingly essential in the scientific impact analysis in the era of big data. This paper develops an attention mechanism for the long-term scientific impact prediction and validates the method based on a real large-scale citation data set. The results break conventional thinking. Instead of accurately simulating the original power-law distribution, emphasizing the limited attention can better stand on the shoulders of giants.