 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025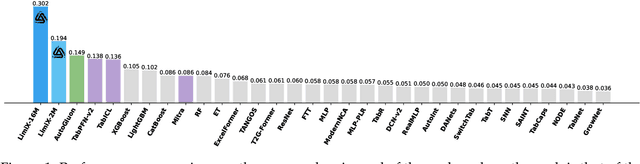
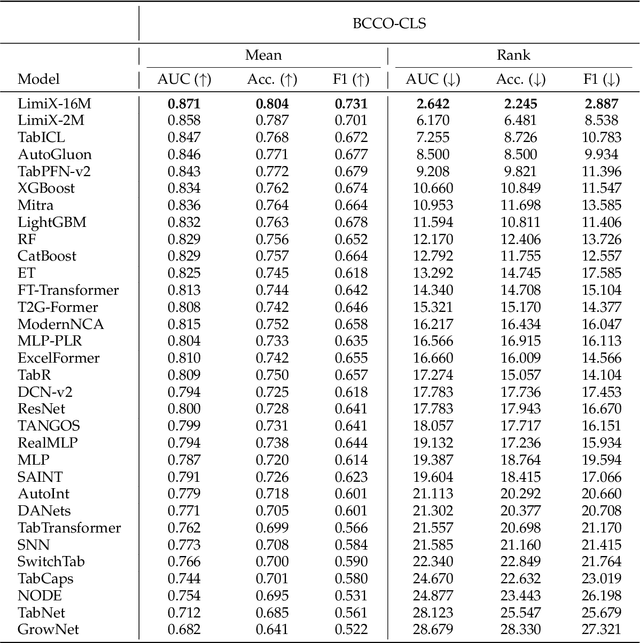
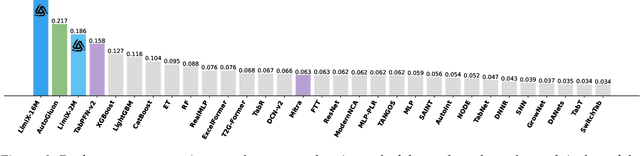
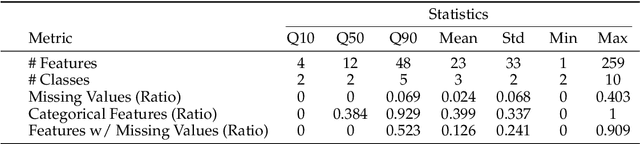
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Sequential Recommendation with Causal Behavior Discovery
Apr 01, 2022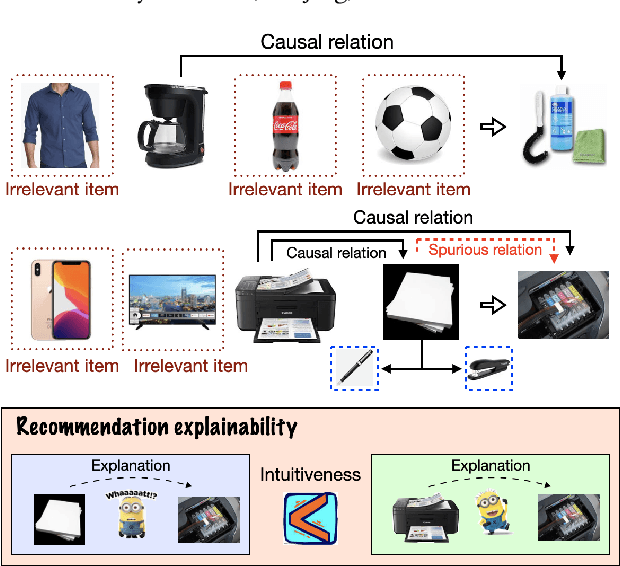
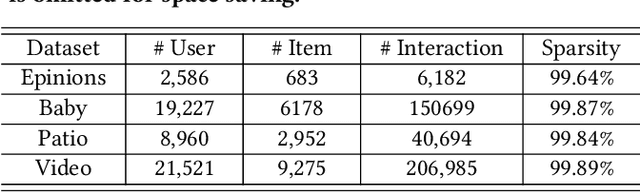
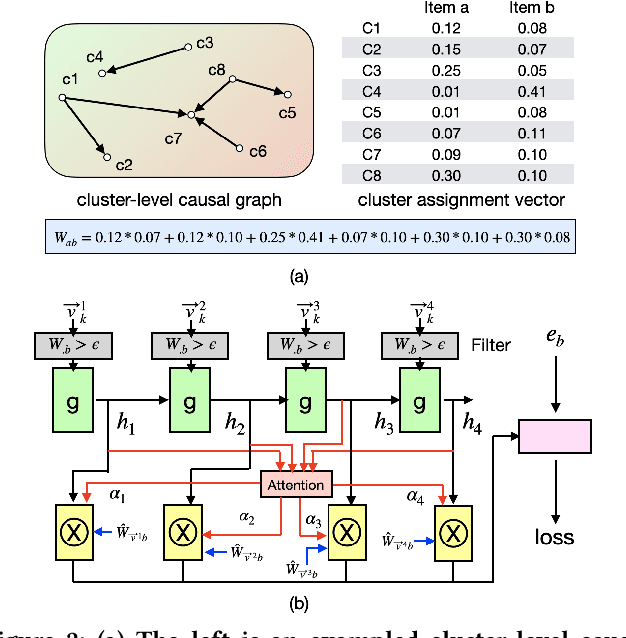
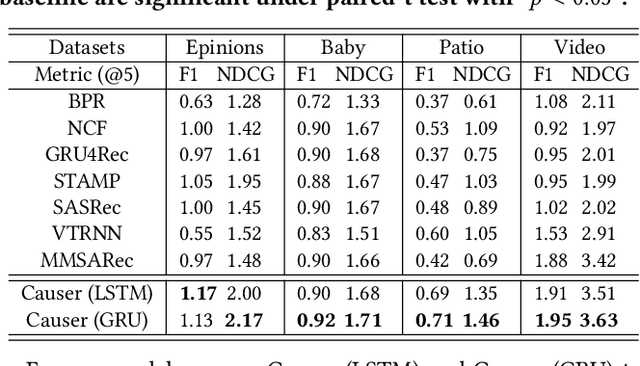
The key of sequential recommendation lies in the accurate item correlation modeling. Previous models infer such information based on item co-occurrences, which may fail to capture the real causal relations, and impact the recommendation performance and explainability. In this paper, we equip sequential recommendation with a novel causal discovery module to capture causalities among user behaviors. Our general idea is firstly assuming a causal graph underlying item correlations, and then we learn the causal graph jointly with the sequential recommender model by fitting the real user behavior data. More specifically, in order to satisfy the causality requirement, the causal graph is regularized by a differentiable directed acyclic constraint. Considering that the number of items in recommender systems can be very large, we represent different items with a unified set of latent clusters, and the causal graph is defined on the cluster level, which enhances the model scalability and robustness. In addition, we provide theoretical analysis on the identifiability of the learned causal graph. To the best of our knowledge, this paper makes a first step towards combining sequential recommendation with causal discovery. For evaluating the recommendation performance, we implement our framework with different neural sequential architectures, and compare them with many state-of-the-art methods based on real-world datasets. Empirical studies manifest that our model can on average improve the performance by about 7% and 11% on f1 and NDCG, respectively. To evaluate the model explainability, we build a new dataset with human labeled explanations for both quantitative and qualitative analysis.