 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciCore-Mol: Augmenting Large Language Models with Pluggable Molecular Cognition Modules
May 21, 2026Large Language Models (LLMs) are central to the one-for-all intelligent paradigm, but they face a fundamental challenge when dealing with heterogeneous scientific data such as molecules: the inherent gap between discrete linguistic symbols and topological molecular or continuous reaction data leads to significant information loss and semantic noise in text-based reasoning. We propose SciCore-Mol, a modular framework that bridges this gap through three deeply integrated pluggable cognitive modules: a topology-aware perception module, a latent diffusion-based molecular generation module, and a reaction-aware reasoning module. Each module is coupled to the LLM backbone through learned representation interfaces, enabling richer information exchange than is possible with text-only tool feedback. Our experiments on diverse chemical tasks demonstrate that SciCore-Mol achieves strong comprehensive performance across molecular understanding, generation, reaction prediction, and general chemistry knowledge, with an 8B-parameter open-source system that is competitive with and in several dimensions surpasses proprietary large models. This work provides a systematic blueprint for equipping LLMs with scientific expertise through decoupled, pluggable, and flexibly orchestrated modules, with direct implications for drug design, chemical synthesis, and broader scientific discovery.
NaviRAG: Towards Active Knowledge Navigation for Retrieval-Augmented Generation
Apr 14, 2026Retrieval-augmented generation (RAG) typically relies on a flat retrieval paradigm that maps queries directly to static, isolated text segments. This approach struggles with more complex tasks that require the conditional retrieval and dynamic synthesis of information across different levels of granularity (e.g., from broad concepts to specific evidence). To bridge this gap, we introduce NaviRAG, a novel framework that shifts from passive segment retrieval to active knowledge navigation. NaviRAG first structures the knowledge documents into a hierarchical form, preserving semantic relationships from coarse-grained topics to fine-grained details. Leveraging this reorganized knowledge records, a large language model (LLM) agent actively navigates the records, iteratively identifying information gaps and retrieving relevant content from the most appropriate granularity level. Extensive experiments on long-document QA benchmarks show that NaviRAG consistently improves both retrieval recall and end-to-end answer performance over conventional RAG baselines. Ablation studies confirm performance gains stem from our method's capacity for multi-granular evidence localization and dynamic retrieval planning. We further discuss efficiency, applicable scenario, and future directions of our method, hoping to make RAG systems more intelligent and autonomous.
Scientific Knowledge-driven Decoding Constraints Improving the Reliability of LLMs
Apr 08, 2026Large language models (LLMs) have shown strong knowledge reserves and task-solving capabilities, but still face the challenge of severe hallucination, hindering their practical application. Though scientific theories and rules can efficiently direct the behaviors of human manipulators, LLMs still do not utilize these highly-condensed knowledge sufficiently through training or prompting. To address this issue, we propose \textbf{SciDC}, an LLM generation method that integrate subject-specific knowledge with strong constraints. By adopting strong LLMs to automatically convert flexible knowledge into multi-layered, standardized rules, we build an extensible framework to effectively constrain the model generation on domain tasks. Experiments on scientific tasks including industrial formulation design, clinical tumor diagnosis and retrosynthesis planning, consistently demonstrate the effectiveness of our method, achieving a 12\% accuracy improvement on average compared with vanilla generation. We further discuss the potential of LLMs in automatically inductively summarizing highly-condensed knowledge, looking ahead to practical solutions for accelerating the overall scientific research process. All the code of this paper can be obtained (https://github.com/Maotian-Ma/SciDC).
DrugR: Optimizing Molecular Drugs through LLM-based Explicit Reasoning
Feb 09, 2026Molecule generation and optimization is a fundamental task in chemical domain. The rapid development of intelligent tools, especially large language models (LLMs) with powerful knowledge reserves and interactive capabilities, has provided new paradigms for it. Nevertheless, the intrinsic challenge for LLMs lies in the complex implicit relationship between molecular structure and pharmacological properties and the lack of corresponding labeled data. To bridge this gap, we propose DrugR, an LLM-based method that introduces explicit, step-by-step pharmacological reasoning into the optimization process. Our approach integrates domain-specific continual pretraining, supervised fine-tuning via reverse data engineering, and self-balanced multi-granular reinforcement learning. This framework enables DrugR to effectively improve key ADMET properties while preserving the original molecule's core efficacy. Experimental results demonstrate that DrugR achieves comprehensive enhancement across multiple properties without compromising structural similarity or target binding affinity. Importantly, its explicit reasoning process provides clear, interpretable rationales for each optimization step, yielding actionable design insights and advancing toward automated, knowledge-driven scientific discovery. Our code and model checkpoints are open-sourced to foster future research.
Graph-Anchored Knowledge Indexing for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-Augmented Generation (RAG) has emerged as a dominant paradigm for mitigating hallucinations in Large Language Models (LLMs) by incorporating external knowledge. Nevertheless, effectively integrating and interpreting key evidence scattered across noisy documents remains a critical challenge for existing RAG systems. In this paper, we propose GraphAnchor, a novel Graph-Anchored Knowledge Indexing approach that reconceptualizes graph structures from static knowledge representations into active, evolving knowledge indices. GraphAnchor incrementally updates a graph during iterative retrieval to anchor salient entities and relations, yielding a structured index that guides the LLM in evaluating knowledge sufficiency and formulating subsequent subqueries. The final answer is generated by jointly leveraging all retrieved documents and the final evolved graph. Experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of GraphAnchor, and reveal that GraphAnchor modulates the LLM's attention to more effectively associate key information distributed in retrieved documents. All code and data are available at https://github.com/NEUIR/GraphAnchor.
Structured Knowledge Representation through Contextual Pages for Retrieval-Augmented Generation
Jan 14, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge. Recently, some works have incorporated iterative knowledge accumulation processes into RAG models to progressively accumulate and refine query-related knowledge, thereby constructing more comprehensive knowledge representations. However, these iterative processes often lack a coherent organizational structure, which limits the construction of more comprehensive and cohesive knowledge representations. To address this, we propose PAGER, a page-driven autonomous knowledge representation framework for RAG. PAGER first prompts an LLM to construct a structured cognitive outline for a given question, which consists of multiple slots representing a distinct knowledge aspect. Then, PAGER iteratively retrieves and refines relevant documents to populate each slot, ultimately constructing a coherent page that serves as contextual input for guiding answer generation. Experiments on multiple knowledge-intensive benchmarks and backbone models show that PAGER consistently outperforms all RAG baselines. Further analyses demonstrate that PAGER constructs higher-quality and information-dense knowledge representations, better mitigates knowledge conflicts, and enables LLMs to leverage external knowledge more effectively. All code is available at https://github.com/OpenBMB/PAGER.
Judge as A Judge: Improving the Evaluation of Retrieval-Augmented Generation through the Judge-Consistency of Large Language Models
Feb 26, 2025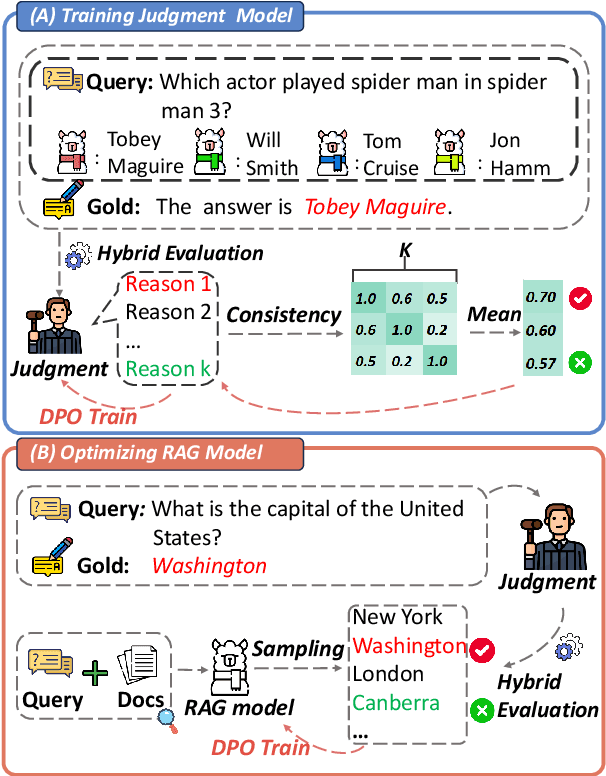
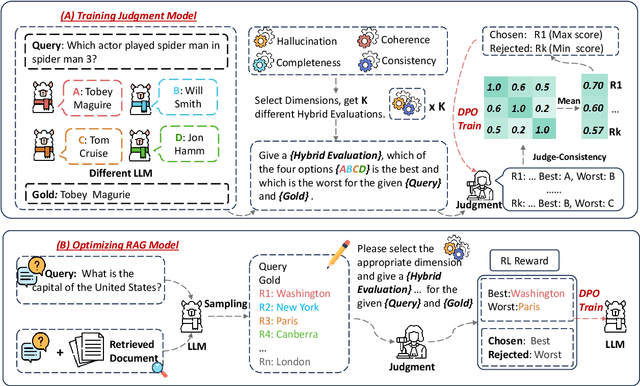
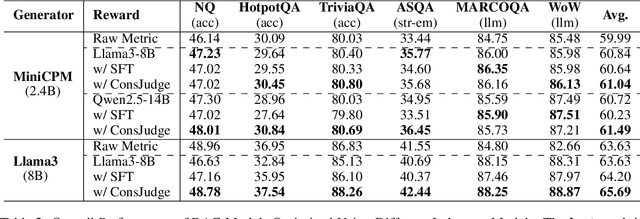
Retrieval-Augmented Generation (RAG) has proven its effectiveness in alleviating hallucinations for Large Language Models (LLMs). However, existing automated evaluation metrics cannot fairly evaluate the outputs generated by RAG models during training and evaluation. LLM-based judgment models provide the potential to produce high-quality judgments, but they are highly sensitive to evaluation prompts, leading to inconsistencies when judging the output of RAG models. This paper introduces the Judge-Consistency (ConsJudge) method, which aims to enhance LLMs to generate more accurate evaluations for RAG models. Specifically, ConsJudge prompts LLMs to generate different judgments based on various combinations of judgment dimensions, utilize the judge-consistency to evaluate these judgments and select the accepted and rejected judgments for DPO training. Our experiments show that ConsJudge can effectively provide more accurate judgments for optimizing RAG models across various RAG models and datasets. Further analysis reveals that judgments generated by ConsJudge have a high agreement with the superior LLM. All codes are available at https://github.com/OpenBMB/ConsJudge.
RankCoT: Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts
Feb 25, 2025Retrieval-Augmented Generation (RAG) enhances the performance of Large Language Models (LLMs) by incorporating external knowledge. However, LLMs still encounter challenges in effectively utilizing the knowledge from retrieved documents, often being misled by irrelevant or noisy information. To address this issue, we introduce RankCoT, a knowledge refinement method that incorporates reranking signals in generating CoT-based summarization for knowledge refinement based on given query and all retrieval documents. During training, RankCoT prompts the LLM to generate Chain-of-Thought (CoT) candidates based on the query and individual documents. It then fine-tunes the LLM to directly reproduce the best CoT from these candidate outputs based on all retrieved documents, which requires LLM to filter out irrelevant documents during generating CoT-style summarization. Additionally, RankCoT incorporates a self-reflection mechanism that further refines the CoT outputs, resulting in higher-quality training data. Our experiments demonstrate the effectiveness of RankCoT, showing its superior performance over other knowledge refinement models. Further analysis reveals that RankCoT can provide shorter but effective refinement results, enabling the generator to produce more accurate answers. All code and data are available at https://github.com/NEUIR/RankCoT.
KBAlign: Efficient Self Adaptation on Specific Knowledge Bases
Nov 25, 2024



Humans can utilize techniques to quickly acquire knowledge from specific materials in advance, such as creating self-assessment questions, enabling us to achieving related tasks more efficiently. In contrast, large language models (LLMs) usually relies on retrieval-augmented generation to exploit knowledge materials in an instant manner, or requires external signals such as human preference data and stronger LLM annotations to conduct knowledge adaptation. To unleash the self-learning potential of LLMs, we propose KBAlign, an approach designed for efficient adaptation to downstream tasks involving knowledge bases. Our method utilizes iterative training with self-annotated data such as Q&A pairs and revision suggestions, enabling the model to grasp the knowledge content efficiently. Experimental results on multiple datasets demonstrate the effectiveness of our approach, significantly boosting model performance in downstream tasks that require specific knowledge at a low cost. Notably, our approach achieves over 90% of the performance improvement that can be obtained by using GPT-4-turbo annotation, while relying entirely on self-supervision. We release our experimental data, models, and process analyses to the community for further exploration (https://github.com/thunlp/KBAlign).
RAG-DDR: Optimizing Retrieval-Augmented Generation Using Differentiable Data Rewards
Oct 17, 2024



Retrieval-Augmented Generation (RAG) has proven its effectiveness in mitigating hallucinations in Large Language Models (LLMs) by retrieving knowledge from external resources. To adapt LLMs for RAG pipelines, current approaches use instruction tuning to optimize LLMs, improving their ability to utilize retrieved knowledge. This supervised fine-tuning (SFT) approach focuses on equipping LLMs to handle diverse RAG tasks using different instructions. However, it trains RAG modules to overfit training signals and overlooks the varying data preferences among agents within the RAG system. In this paper, we propose a Differentiable Data Rewards (DDR) method, which end-to-end trains RAG systems by aligning data preferences between different RAG modules. DDR works by collecting the rewards to optimize each agent with a rollout method. This method prompts agents to sample some potential responses as perturbations, evaluates the impact of these perturbations on the whole RAG system, and subsequently optimizes the agent to produce outputs that improve the performance of the RAG system. Our experiments on various knowledge-intensive tasks demonstrate that DDR significantly outperforms the SFT method, particularly for LLMs with smaller-scale parameters that depend more on the retrieved knowledge. Additionally, DDR exhibits a stronger capability to align the data preference between RAG modules. The DDR method makes generation module more effective in extracting key information from documents and mitigating conflicts between parametric memory and external knowledge. All codes are available at https://github.com/OpenMatch/RAG-DDR.