 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAT: Unified Audio-Text Diffusion for Audio Generation, Editing, and Captioning
Jun 03, 2026Audio generation and audio-to-text understanding remain largely separate, with diffusion models dominating high-fidelity synthesis and autoregressive (AR) language models driving captioning and semantic prediction. Existing unified approaches typically rely on either heterogeneous modules or AR-centric modeling, which can hinder joint optimization and limit acoustic fidelity. We present UAT, to our knowledge, the first diffusion-centric framework that supports unified audio generation, editing, and captioning. UAT couples continuous latent diffusion for audio with masked discrete diffusion for text, enabling bidirectional audio-text modeling within a shared dual-stream backbone. Experiments show that UAT preserves strong audio generation and editing capabilities while achieving competitive captioning performance, demonstrating a favorable balance between acoustic synthesis and semantic prediction. Demo samples are available at https://UAT-demo.github.io.
Separate First, Fuse Later: Mitigating Cross-Modal Interference in Audio-Visual LLMs Reasoning with Modality-Specific Chain-of-Thought
May 11, 2026Audio and vision provide complementary evidence for audio-visual question answering, yet current audio-visual large language models may suffer from cross-modal interference: information from one modality misguides the interpretation of another, thereby inducing hallucinations. We attribute this issue to uncontrolled cross-modal interactions during intermediate reasoning. To mitigate this, we propose Separate First, Fuse Later (SFFL), an audio-visual reasoning framework designed to reduce cross-modal interference. SFFL enforces modality-specific chain-of-thought reasoning, producing separate audio and visual reasoning traces and integrating evidence for answering. We construct modality-preference labels via a data pipeline under different modality input settings. We use these labels as an auxiliary reward in reinforcement learning to encourage a instance-dependent preference for modality cues when answering. We further introduce a modality-specific reasoning mechanism that preserves modality isolation during the separated reasoning stage while enabling full access to cross-modal information at the evidence fusion stage. Experiments demonstrate consistent improvements in both accuracy and robustness, yielding an average relative gain of 5.16\% on general AVQA benchmarks and 11.17\% on a cross-modal hallucination benchmark.
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Jan 06, 2026Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
AUV: Teaching Audio Universal Vector Quantization with Single Nested Codebook
Sep 26, 2025We propose AUV, a unified neural audio codec with a single codebook, which enables a favourable reconstruction of speech and further extends to general audio, including vocal, music, and sound. AUV is capable of tackling any 16 kHz mixed-domain audio segment at bit rates around 700 bps. To accomplish this, we guide the matryoshka codebook with nested domain-specific partitions, assigned with corresponding teacher models to perform distillation, all in a single-stage training. A conformer-style encoder-decoder architecture with STFT features as audio representation is employed, yielding better audio quality. Comprehensive evaluations demonstrate that AUV exhibits comparable audio reconstruction ability to state-of-the-art domain-specific single-layer quantizer codecs, showcasing the potential of audio universal vector quantization with a single codebook. The pre-trained model and demo samples are available at https://swivid.github.io/AUV/.
BadDepth: Backdoor Attacks Against Monocular Depth Estimation in the Physical World
May 22, 2025In recent years, deep learning-based Monocular Depth Estimation (MDE) models have been widely applied in fields such as autonomous driving and robotics. However, their vulnerability to backdoor attacks remains unexplored. To fill the gap in this area, we conduct a comprehensive investigation of backdoor attacks against MDE models. Typically, existing backdoor attack methods can not be applied to MDE models. This is because the label used in MDE is in the form of a depth map. To address this, we propose BadDepth, the first backdoor attack targeting MDE models. BadDepth overcomes this limitation by selectively manipulating the target object's depth using an image segmentation model and restoring the surrounding areas via depth completion, thereby generating poisoned datasets for object-level backdoor attacks. To improve robustness in physical world scenarios, we further introduce digital-to-physical augmentation to adapt to the domain gap between the physical world and the digital domain. Extensive experiments on multiple models validate the effectiveness of BadDepth in both the digital domain and the physical world, without being affected by environmental factors.
UNEM: UNrolled Generalized EM for Transductive Few-Shot Learning
Dec 21, 2024



Transductive few-shot learning has recently triggered wide attention in computer vision. Yet, current methods introduce key hyper-parameters, which control the prediction statistics of the test batches, such as the level of class balance, affecting performances significantly. Such hyper-parameters are empirically grid-searched over validation data, and their configurations may vary substantially with the target dataset and pre-training model, making such empirical searches both sub-optimal and computationally intractable. In this work, we advocate and introduce the unrolling paradigm, also referred to as "learning to optimize", in the context of few-shot learning, thereby learning efficiently and effectively a set of optimized hyper-parameters. Specifically, we unroll a generalization of the ubiquitous Expectation-Maximization (EM) optimizer into a neural network architecture, mapping each of its iterates to a layer and learning a set of key hyper-parameters over validation data. Our unrolling approach covers various statistical feature distributions and pre-training paradigms, including recent foundational vision-language models and standard vision-only classifiers. We report comprehensive experiments, which cover a breadth of fine-grained downstream image classification tasks, showing significant gains brought by the proposed unrolled EM algorithm over iterative variants. The achieved improvements reach up to 10% and 7.5% on vision-only and vision-language benchmarks, respectively.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024



Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
ARLON: Boosting Diffusion Transformers with Autoregressive Models for Long Video Generation
Oct 27, 2024



Text-to-video models have recently undergone rapid and substantial advancements. Nevertheless, due to limitations in data and computational resources, achieving efficient generation of long videos with rich motion dynamics remains a significant challenge. To generate high-quality, dynamic, and temporally consistent long videos, this paper presents ARLON, a novel framework that boosts diffusion Transformers with autoregressive models for long video generation, by integrating the coarse spatial and long-range temporal information provided by the AR model to guide the DiT model. Specifically, ARLON incorporates several key innovations: 1) A latent Vector Quantized Variational Autoencoder (VQ-VAE) compresses the input latent space of the DiT model into compact visual tokens, bridging the AR and DiT models and balancing the learning complexity and information density; 2) An adaptive norm-based semantic injection module integrates the coarse discrete visual units from the AR model into the DiT model, ensuring effective guidance during video generation; 3) To enhance the tolerance capability of noise introduced from the AR inference, the DiT model is trained with coarser visual latent tokens incorporated with an uncertainty sampling module. Experimental results demonstrate that ARLON significantly outperforms the baseline OpenSora-V1.2 on eight out of eleven metrics selected from VBench, with notable improvements in dynamic degree and aesthetic quality, while delivering competitive results on the remaining three and simultaneously accelerating the generation process. In addition, ARLON achieves state-of-the-art performance in long video generation. Detailed analyses of the improvements in inference efficiency are presented, alongside a practical application that demonstrates the generation of long videos using progressive text prompts. See demos of ARLON at \url{http://aka.ms/arlon}.
Investigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024



Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
Autoregressive Speech Synthesis without Vector Quantization
Jul 11, 2024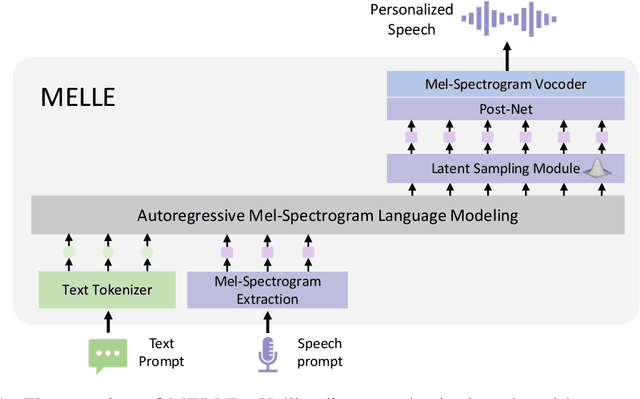



We present MELLE, a novel continuous-valued tokens based language modeling approach for text to speech synthesis (TTS). MELLE autoregressively generates continuous mel-spectrogram frames directly from text condition, bypassing the need for vector quantization, which are originally designed for audio compression and sacrifice fidelity compared to mel-spectrograms. Specifically, (i) instead of cross-entropy loss, we apply regression loss with a proposed spectrogram flux loss function to model the probability distribution of the continuous-valued tokens. (ii) we have incorporated variational inference into MELLE to facilitate sampling mechanisms, thereby enhancing the output diversity and model robustness. Experiments demonstrate that, compared to the two-stage codec language models VALL-E and its variants, the single-stage MELLE mitigates robustness issues by avoiding the inherent flaws of sampling discrete codes, achieves superior performance across multiple metrics, and, most importantly, offers a more streamlined paradigm. See https://aka.ms/melle for demos of our work.