 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Format: Towards Consistent Evaluation of In-Context Learning Improvements
Jan 22, 2024



Large language models demonstrate a remarkable capability for learning to solve new tasks from a few examples. The prompt template, or the way the input examples are formatted to obtain the prompt, is an important yet often overlooked aspect of in-context learning. In this work, we conduct a comprehensive study of the template format's influence on the in-context learning performance. We evaluate the impact of the prompt template across models (from 770M to 70B parameters) and 4 standard classification datasets. We show that a poor choice of the template can reduce the performance of the strongest models and inference methods to a random guess level. More importantly, the best templates do not transfer between different setups and even between models of the same family. Our findings show that the currently prevalent approach to evaluation, which ignores template selection, may give misleading results due to different templates in different works. As a first step towards mitigating this issue, we propose Template Ensembles that aggregate model predictions across several templates. This simple test-time augmentation boosts average performance while being robust to the choice of random set of templates.
Distributed Inference and Fine-tuning of Large Language Models Over The Internet
Dec 13, 2023



Large language models (LLMs) are useful in many NLP tasks and become more capable with size, with the best open-source models having over 50 billion parameters. However, using these 50B+ models requires high-end hardware, making them inaccessible to most researchers. In this work, we investigate methods for cost-efficient inference and fine-tuning of LLMs, comparing local and distributed strategies. We observe that a large enough model (50B+) can run efficiently even on geodistributed devices in a consumer-grade network. This could allow running LLM efficiently by pooling together idle compute resources of multiple research groups and volunteers. We address two open problems: (1) how to perform inference and fine-tuning reliably if any device can disconnect abruptly and (2) how to partition LLMs between devices with uneven hardware, joining and leaving at will. In order to do that, we develop special fault-tolerant inference algorithms and load-balancing protocols that automatically assign devices to maximize the total system throughput. We showcase these algorithms in Petals - a decentralized system that runs Llama 2 (70B) and BLOOM (176B) over the Internet up to 10x faster than offloading for interactive generation. We evaluate the performance of our system in simulated conditions and a real-world setup spanning two continents.
Hypernymy Understanding Evaluation of Text-to-Image Models via WordNet Hierarchy
Oct 13, 2023



Text-to-image synthesis has recently attracted widespread attention due to rapidly improving quality and numerous practical applications. However, the language understanding capabilities of text-to-image models are still poorly understood, which makes it difficult to reason about prompt formulations that a given model would understand well. In this work, we measure the capability of popular text-to-image models to understand $\textit{hypernymy}$, or the "is-a" relation between words. We design two automatic metrics based on the WordNet semantic hierarchy and existing image classifiers pretrained on ImageNet. These metrics both enable broad quantitative comparison of linguistic capabilities for text-to-image models and offer a way of finding fine-grained qualitative differences, such as words that are unknown to models and thus are difficult for them to draw. We comprehensively evaluate popular text-to-image models, including GLIDE, Latent Diffusion, and Stable Diffusion, showing how our metrics can provide a better understanding of the individual strengths and weaknesses of these models.
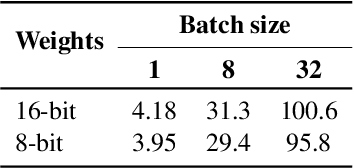
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023



The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen
Is This Loss Informative? Speeding Up Textual Inversion with Deterministic Objective Evaluation
Feb 09, 2023Text-to-image generation models represent the next step of evolution in image synthesis, offering natural means of flexible yet fine-grained control over the result. One emerging area of research is the rapid adaptation of large text-to-image models to smaller datasets or new visual concepts. However, the most efficient method of adaptation, called textual inversion, has a known limitation of long training time, which both restricts practical applications and increases the experiment time for research. In this work, we study the training dynamics of textual inversion, aiming to speed it up. We observe that most concepts are learned at early stages and do not improve in quality later, but standard model convergence metrics fail to indicate that. Instead, we propose a simple early stopping criterion that only requires computing the textual inversion loss on the same inputs for all training iterations. Our experiments on both Latent Diffusion and Stable Diffusion models for 93 concepts demonstrate the competitive performance of our method, speeding adaptation up to 15 times with no significant drops in quality.
SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient
Jan 27, 2023



Many deep learning applications benefit from using large models with billions of parameters. Training these models is notoriously expensive due to the need for specialized HPC clusters. In this work, we consider alternative setups for training large models: using cheap "preemptible" instances or pooling existing resources from multiple regions. We analyze the performance of existing model-parallel algorithms in these conditions and find configurations where training larger models becomes less communication-intensive. Based on these findings, we propose SWARM parallelism, a model-parallel training algorithm designed for poorly connected, heterogeneous and unreliable devices. SWARM creates temporary randomized pipelines between nodes that are rebalanced in case of failure. We empirically validate our findings and compare SWARM parallelism with existing large-scale training approaches. Finally, we combine our insights with compression strategies to train a large Transformer language model with 1B shared parameters (approximately 13B before sharing) on preemptible T4 GPUs with less than 200Mb/s network.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
RuCoLA: Russian Corpus of Linguistic Acceptability
Oct 23, 2022



Linguistic acceptability (LA) attracts the attention of the research community due to its many uses, such as testing the grammatical knowledge of language models and filtering implausible texts with acceptability classifiers. However, the application scope of LA in languages other than English is limited due to the lack of high-quality resources. To this end, we introduce the Russian Corpus of Linguistic Acceptability (RuCoLA), built from the ground up under the well-established binary LA approach. RuCoLA consists of $9.8$k in-domain sentences from linguistic publications and $3.6$k out-of-domain sentences produced by generative models. The out-of-domain set is created to facilitate the practical use of acceptability for improving language generation. Our paper describes the data collection protocol and presents a fine-grained analysis of acceptability classification experiments with a range of baseline approaches. In particular, we demonstrate that the most widely used language models still fall behind humans by a large margin, especially when detecting morphological and semantic errors. We release RuCoLA, the code of experiments, and a public leaderboard (rucola-benchmark.com) to assess the linguistic competence of language models for Russian.
Petals: Collaborative Inference and Fine-tuning of Large Models
Sep 02, 2022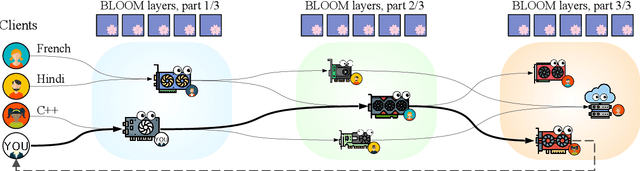


Many NLP tasks benefit from using large language models (LLMs) that often have more than 100 billion parameters. With the release of BLOOM-176B and OPT-175B, everyone can download pretrained models of this scale. Still, using these models requires high-end hardware unavailable to many researchers. In some cases, LLMs can be used more affordably via RAM offloading or hosted APIs. However, these techniques have innate limitations: offloading is too slow for interactive inference, while APIs are not flexible enough for research. In this work, we propose Petals $-$ a system for inference and fine-tuning of large models collaboratively by joining the resources of multiple parties trusted to process client's data. We demonstrate that this strategy significantly outperforms offloading for very large models, running inference of BLOOM-176B on consumer GPUs with $\approx$ 1 step per second. Unlike most inference APIs, Petals also natively exposes the hidden states of served models, allowing its users to train and share custom model extensions based on efficient fine-tuning methods.
Training Transformers Together
Jul 07, 2022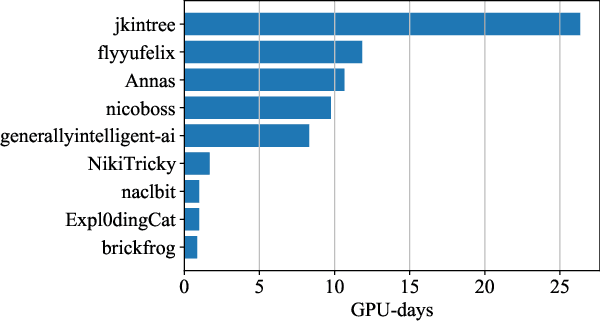

The infrastructure necessary for training state-of-the-art models is becoming overly expensive, which makes training such models affordable only to large corporations and institutions. Recent work proposes several methods for training such models collaboratively, i.e., by pooling together hardware from many independent parties and training a shared model over the Internet. In this demonstration, we collaboratively trained a text-to-image transformer similar to OpenAI DALL-E. We invited the viewers to join the ongoing training run, showing them instructions on how to contribute using the available hardware. We explained how to address the engineering challenges associated with such a training run (slow communication, limited memory, uneven performance between devices, and security concerns) and discussed how the viewers can set up collaborative training runs themselves. Finally, we show that the resulting model generates images of reasonable quality on a number of prompts.