 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Domain Automatic Short Answer Grading through an Explainable Neuro-Symbolic Pipeline
Mar 04, 2024Grading short answer questions automatically with interpretable reasoning behind the grading decision is a challenging goal for current transformer approaches. Justification cue detection, in combination with logical reasoners, has shown a promising direction for neuro-symbolic architectures in ASAG. But, one of the main challenges is the requirement of annotated justification cues in the students' responses, which only exist for a few ASAG datasets. To overcome this challenge, we contribute (1) a weakly supervised annotation procedure for justification cues in ASAG datasets, and (2) a neuro-symbolic model for explainable ASAG based on justification cues. Our approach improves upon the RMSE by 0.24 to 0.3 compared to the state-of-the-art on the Short Answer Feedback dataset in a bilingual, multi-domain, and multi-question training setup. This result shows that our approach provides a promising direction for generating high-quality grades and accompanying explanations for future research in ASAG and educational NLP.
JWSign: A Highly Multilingual Corpus of Bible Translations for more Diversity in Sign Language Processing
Nov 16, 2023



Advancements in sign language processing have been hindered by a lack of sufficient data, impeding progress in recognition, translation, and production tasks. The absence of comprehensive sign language datasets across the world's sign languages has widened the gap in this field, resulting in a few sign languages being studied more than others, making this research area extremely skewed mostly towards sign languages from high-income countries. In this work we introduce a new large and highly multilingual dataset for sign language translation: JWSign. The dataset consists of 2,530 hours of Bible translations in 98 sign languages, featuring more than 1,500 individual signers. On this dataset, we report neural machine translation experiments. Apart from bilingual baseline systems, we also train multilingual systems, including some that take into account the typological relatedness of signed or spoken languages. Our experiments highlight that multilingual systems are superior to bilingual baselines, and that in higher-resource scenarios, clustering language pairs that are related improves translation quality.
The eBible Corpus: Data and Model Benchmarks for Bible Translation for Low-Resource Languages
Apr 19, 2023



Efficiently and accurately translating a corpus into a low-resource language remains a challenge, regardless of the strategies employed, whether manual, automated, or a combination of the two. Many Christian organizations are dedicated to the task of translating the Holy Bible into languages that lack a modern translation. Bible translation (BT) work is currently underway for over 3000 extremely low resource languages. We introduce the eBible corpus: a dataset containing 1009 translations of portions of the Bible with data in 833 different languages across 75 language families. In addition to a BT benchmarking dataset, we introduce model performance benchmarks built on the No Language Left Behind (NLLB) neural machine translation (NMT) models. Finally, we describe several problems specific to the domain of BT and consider how the established data and model benchmarks might be used for future translation efforts. For a BT task trained with NLLB, Austronesian and Trans-New Guinea language families achieve 35.1 and 31.6 BLEU scores respectively, which spurs future innovations for NMT for low-resource languages in Papua New Guinea.
Adapting to the Low-Resource Double-Bind: Investigating Low-Compute Methods on Low-Resource African Languages
Mar 29, 2023

Many natural language processing (NLP) tasks make use of massively pre-trained language models, which are computationally expensive. However, access to high computational resources added to the issue of data scarcity of African languages constitutes a real barrier to research experiments on these languages. In this work, we explore the applicability of low-compute approaches such as language adapters in the context of this low-resource double-bind. We intend to answer the following question: do language adapters allow those who are doubly bound by data and compute to practically build useful models? Through fine-tuning experiments on African languages, we evaluate their effectiveness as cost-effective approaches to low-resource African NLP. Using solely free compute resources, our results show that language adapters achieve comparable performances to massive pre-trained language models which are heavy on computational resources. This opens the door to further experimentation and exploration on full-extent of language adapters capacities.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Bloom Library: Multimodal Datasets in 300+ Languages for a Variety of Downstream Tasks
Oct 26, 2022



We present Bloom Library, a linguistically diverse set of multimodal and multilingual datasets for language modeling, image captioning, visual storytelling, and speech synthesis/recognition. These datasets represent either the most, or among the most, multilingual datasets for each of the included downstream tasks. In total, the initial release of the Bloom Library datasets covers 363 languages across 32 language families. We train downstream task models for various languages represented in the data, showing the viability of the data for future work in low-resource, multimodal NLP and establishing the first known baselines for these downstream tasks in certain languages (e.g., Bisu [bzi], with an estimated population of 700 users). Some of these first-of-their-kind baselines are comparable to state-of-the-art performance for higher-resourced languages. The Bloom Library datasets are released under Creative Commons licenses on the Hugging Face datasets hub to catalyze more linguistically diverse research in the included downstream tasks.
* 14 pages, 1 figure, 3 tables, accepted to and presented at EMNLP 2022
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022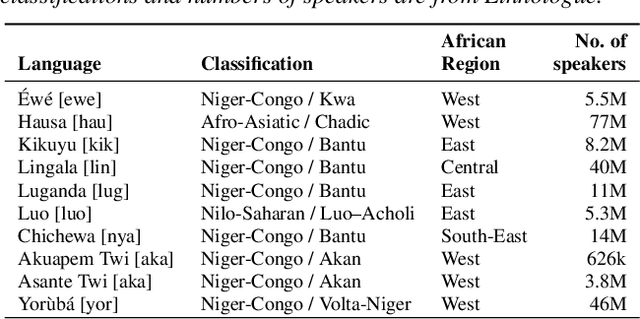
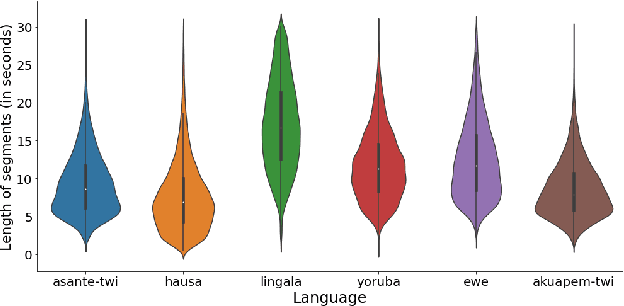
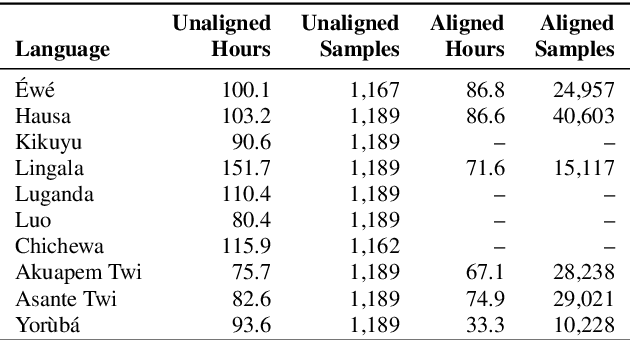
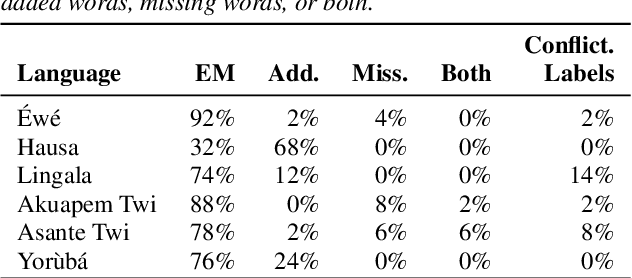
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022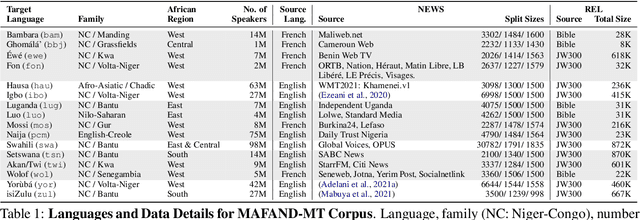
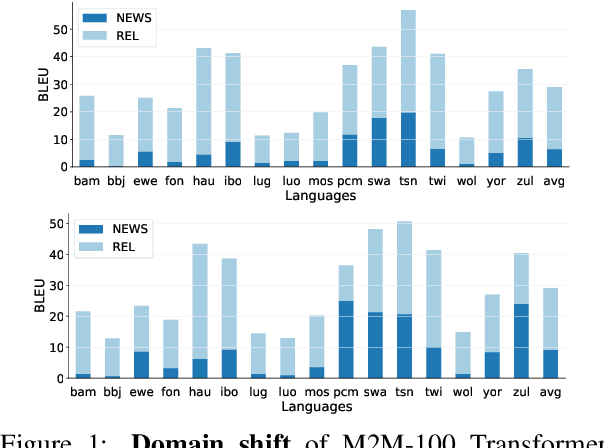

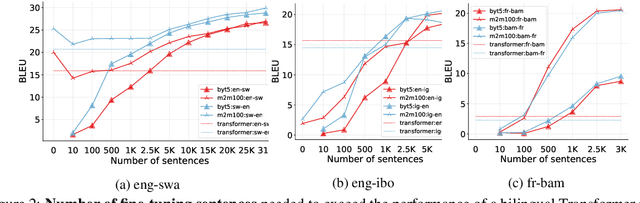
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
Documenting Geographically and Contextually Diverse Data Sources: The BigScience Catalogue of Language Data and Resources
Jan 25, 2022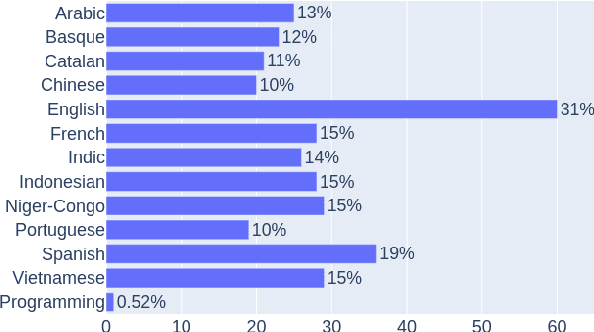
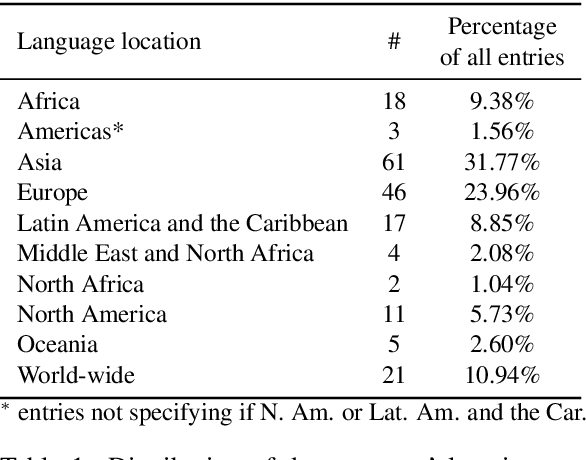
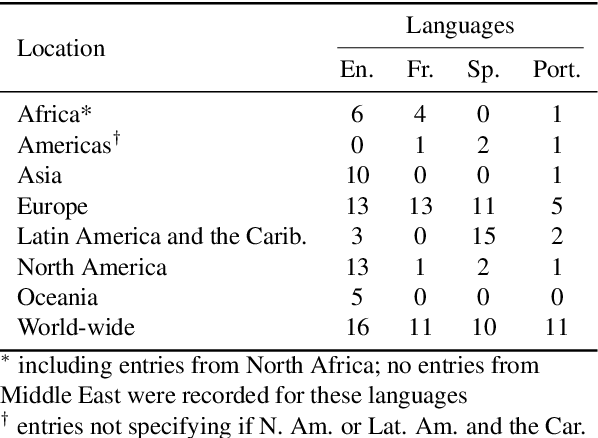
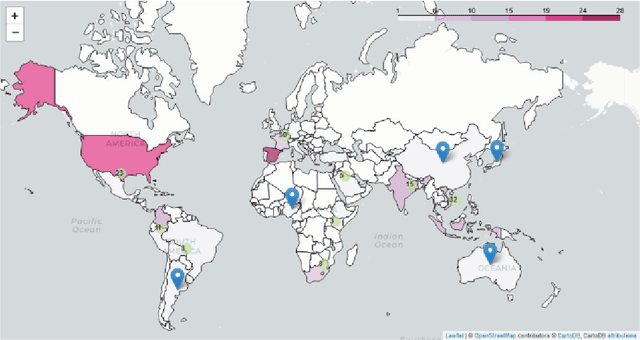
In recent years, large-scale data collection efforts have prioritized the amount of data collected in order to improve the modeling capabilities of large language models. This prioritization, however, has resulted in concerns with respect to the rights of data subjects represented in data collections, particularly when considering the difficulty in interrogating these collections due to insufficient documentation and tools for analysis. Mindful of these pitfalls, we present our methodology for a documentation-first, human-centered data collection project as part of the BigScience initiative. We identified a geographically diverse set of target language groups (Arabic, Basque, Chinese, Catalan, English, French, Indic languages, Indonesian, Niger-Congo languages, Portuguese, Spanish, and Vietnamese, as well as programming languages) for which to collect metadata on potential data sources. To structure this effort, we developed our online catalogue as a supporting tool for gathering metadata through organized public hackathons. We present our development process; analyses of the resulting resource metadata, including distributions over languages, regions, and resource types; and our lessons learned in this endeavor.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
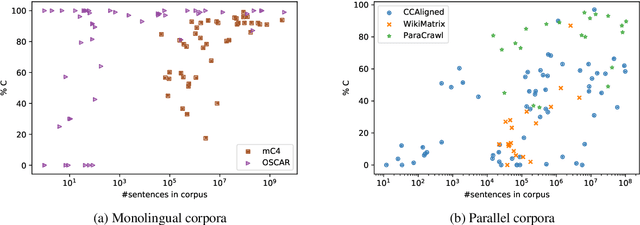

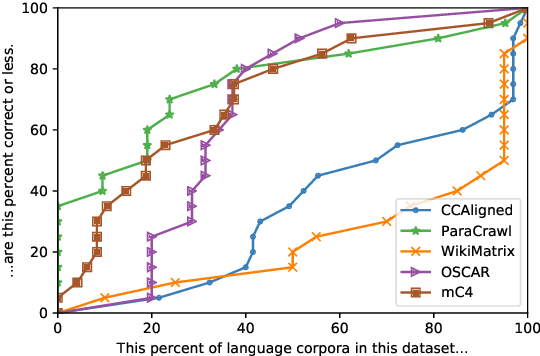
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.