 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
Commonsense Reasoning in Arab Culture
Feb 18, 2025



Despite progress in Arabic large language models, such as Jais and AceGPT, their evaluation on commonsense reasoning has largely relied on machine-translated datasets, which lack cultural depth and may introduce Anglocentric biases. Commonsense reasoning is shaped by geographical and cultural contexts, and existing English datasets fail to capture the diversity of the Arab world. To address this, we introduce \datasetname, a commonsense reasoning dataset in Modern Standard Arabic (MSA), covering cultures of 13 countries across the Gulf, Levant, North Africa, and the Nile Valley. The dataset was built from scratch by engaging native speakers to write and validate culturally relevant questions for their respective countries. \datasetname spans 12 daily life domains with 54 fine-grained subtopics, reflecting various aspects of social norms, traditions, and everyday experiences. Zero-shot evaluations show that open-weight language models with up to 32B parameters struggle to comprehend diverse Arab cultures, with performance varying across regions. These findings highlight the need for more culturally aware models and datasets tailored to the Arabic-speaking world.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
ArabicMMLU: Assessing Massive Multitask Language Understanding in Arabic
Feb 20, 2024



The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availability of relevant datasets. To bridge this gap, we present ArabicMMLU, the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA), and is carefully constructed by collaborating with native speakers in the region. Our comprehensive evaluations of 35 models reveal substantial room for improvement, particularly among the best open-source models. Notably, BLOOMZ, mT0, LLama2, and Falcon struggle to achieve a score of 50%, while even the top-performing Arabic-centric model only achieves a score of 62.3%.
CIDAR: Culturally Relevant Instruction Dataset For Arabic
Feb 05, 2024



Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions. However, current instruction datasets predominantly cater to English or are derived from English-dominated LLMs, resulting in inherent biases toward Western culture. This bias significantly impacts the linguistic structures of non-English languages such as Arabic, which has a distinct grammar reflective of the diverse cultures across the Arab region. This paper addresses this limitation by introducing CIDAR: https://hf.co/datasets/arbml/CIDAR, the first open Arabic instruction-tuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction and output pairs that represent the Arab region. We discuss the cultural relevance of CIDAR via the analysis and comparison to other models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich research efforts in aligning LLMs with the Arabic culture. All the code is available at https://github.com/ARBML/CIDAR.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023



As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting
Dec 19, 2022



The BLOOM model is a large open-source multilingual language model capable of zero-shot learning, but its pretraining was limited to 46 languages. To improve its zero-shot performance on unseen languages, it is desirable to adapt BLOOM, but previous works have only explored adapting small language models. In this work, we apply existing language adaptation strategies to BLOOM and benchmark its zero-shot prompting performance on eight new languages. We find language adaptation to be effective at improving zero-shot performance in new languages. Surprisingly, adapter-based finetuning is more effective than continued pretraining for large models. In addition, we discover that prompting performance is not significantly affected by language specifics, such as the writing system. It is primarily determined by the size of the language adaptation data. We also add new languages to BLOOMZ, which is a multitask finetuned version of BLOOM capable of following task instructions zero-shot. We find including a new language in the multitask fine-tuning mixture to be the most effective method to teach BLOOMZ a new language. We conclude that with sufficient training data language adaptation can generalize well to diverse languages. Our code is available at \url{https://github.com/bigscience-workshop/multilingual-modeling/}.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Crosslingual Generalization through Multitask Finetuning
Nov 03, 2022Multitask prompted finetuning (MTF) has been shown to help large language models generalize to new tasks in a zero-shot setting, but so far explorations of MTF have focused on English data and models. We apply MTF to the pretrained multilingual BLOOM and mT5 model families to produce finetuned variants called BLOOMZ and mT0. We find finetuning large multilingual language models on English tasks with English prompts allows for task generalization to non-English languages that appear only in the pretraining corpus. Finetuning on multilingual tasks with English prompts further improves performance on English and non-English tasks leading to various state-of-the-art zero-shot results. We also investigate finetuning on multilingual tasks with prompts that have been machine-translated from English to match the language of each dataset. We find training on these machine-translated prompts leads to better performance on human-written prompts in the respective languages. Surprisingly, we find models are capable of zero-shot generalization to tasks in languages they have never intentionally seen. We conjecture that the models are learning higher-level capabilities that are both task- and language-agnostic. In addition, we introduce xP3, a composite of supervised datasets in 46 languages with English and machine-translated prompts. Our code, datasets and models are publicly available at https://github.com/bigscience-workshop/xmtf.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
Feb 02, 2022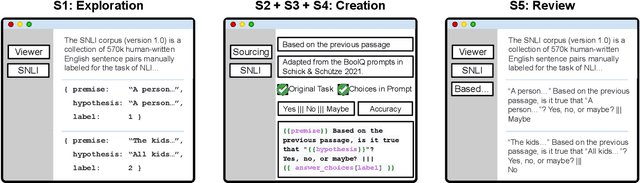
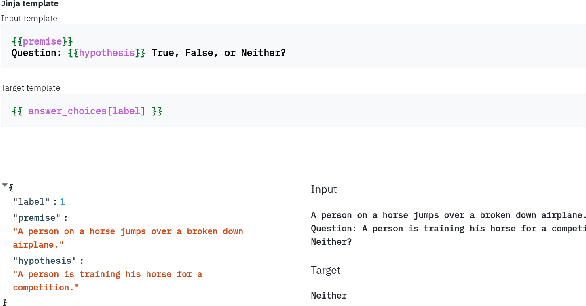

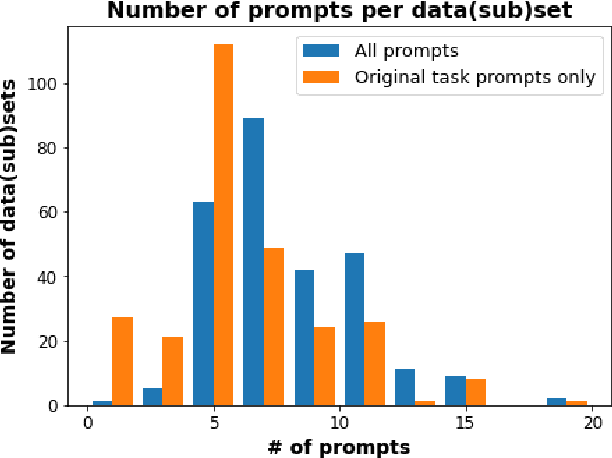
PromptSource is a system for creating, sharing, and using natural language prompts. Prompts are functions that map an example from a dataset to a natural language input and target output. Using prompts to train and query language models is an emerging area in NLP that requires new tools that let users develop and refine these prompts collaboratively. PromptSource addresses the emergent challenges in this new setting with (1) a templating language for defining data-linked prompts, (2) an interface that lets users quickly iterate on prompt development by observing outputs of their prompts on many examples, and (3) a community-driven set of guidelines for contributing new prompts to a common pool. Over 2,000 prompts for roughly 170 datasets are already available in PromptSource. PromptSource is available at https://github.com/bigscience-workshop/promptsource.