 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColBERT-Zero: To Pre-train Or Not To Pre-train ColBERT models
Feb 18, 2026Current state-of-the-art multi-vector models are obtained through a small Knowledge Distillation (KD) training step on top of strong single-vector models, leveraging the large-scale pre-training of these models. In this paper, we study the pre-training of multi-vector models and show that large-scale multi-vector pre-training yields much stronger multi-vector models. Notably, a fully ColBERT-pre-trained model, ColBERT-Zero, trained only on public data, outperforms GTE-ModernColBERT as well as its base model, GTE-ModernBERT, which leverages closed and much stronger data, setting new state-of-the-art for model this size. We also find that, although performing only a small KD step is not enough to achieve results close to full pre-training, adding a supervised step beforehand allows to achieve much closer performance while skipping the most costly unsupervised phase. Finally, we find that aligning the fine-tuning and pre-training setups is crucial when repurposing existing models. To enable exploration of our results, we release various checkpoints as well as code used to train them.
Seq vs Seq: An Open Suite of Paired Encoders and Decoders
Jul 15, 2025The large language model (LLM) community focuses almost exclusively on decoder-only language models, since they are easier to use for text generation. However, a large subset of the community still uses encoder-only models for tasks such as classification or retrieval. Previous work has attempted to compare these architectures, but is forced to make comparisons with models that have different numbers of parameters, training techniques, and datasets. We introduce the SOTA open-data Ettin suite of models: paired encoder-only and decoder-only models ranging from 17 million parameters to 1 billion, trained on up to 2 trillion tokens. Using the same recipe for both encoder-only and decoder-only models produces SOTA recipes in both categories for their respective sizes, beating ModernBERT as an encoder and Llama 3.2 and SmolLM2 as decoders. Like previous work, we find that encoder-only models excel at classification and retrieval tasks while decoders excel at generative tasks. However, we show that adapting a decoder model to encoder tasks (and vice versa) through continued training is subpar compared to using only the reverse objective (i.e. a 400M encoder outperforms a 1B decoder on MNLI, and vice versa for generative tasks). We open-source all artifacts of this study including training data, training order segmented by checkpoint, and 200+ checkpoints to allow future work to analyze or extend all aspects of training.
BioClinical ModernBERT: A State-of-the-Art Long-Context Encoder for Biomedical and Clinical NLP
Jun 12, 2025Encoder-based transformer models are central to biomedical and clinical Natural Language Processing (NLP), as their bidirectional self-attention makes them well-suited for efficiently extracting structured information from unstructured text through discriminative tasks. However, encoders have seen slower development compared to decoder models, leading to limited domain adaptation in biomedical and clinical settings. We introduce BioClinical ModernBERT, a domain-adapted encoder that builds on the recent ModernBERT release, incorporating long-context processing and substantial improvements in speed and performance for biomedical and clinical NLP. BioClinical ModernBERT is developed through continued pretraining on the largest biomedical and clinical corpus to date, with over 53.5 billion tokens, and addresses a key limitation of prior clinical encoders by leveraging 20 datasets from diverse institutions, domains, and geographic regions, rather than relying on data from a single source. It outperforms existing biomedical and clinical encoders on four downstream tasks spanning a broad range of use cases. We release both base (150M parameters) and large (396M parameters) versions of BioClinical ModernBERT, along with training checkpoints to support further research.
Reframing Image Difference Captioning with BLIP2IDC and Synthetic Augmentation
Dec 20, 2024



The rise of the generative models quality during the past years enabled the generation of edited variations of images at an important scale. To counter the harmful effects of such technology, the Image Difference Captioning (IDC) task aims to describe the differences between two images. While this task is successfully handled for simple 3D rendered images, it struggles on real-world images. The reason is twofold: the training data-scarcity, and the difficulty to capture fine-grained differences between complex images. To address those issues, we propose in this paper a simple yet effective framework to both adapt existing image captioning models to the IDC task and augment IDC datasets. We introduce BLIP2IDC, an adaptation of BLIP2 to the IDC task at low computational cost, and show it outperforms two-streams approaches by a significant margin on real-world IDC datasets. We also propose to use synthetic augmentation to improve the performance of IDC models in an agnostic fashion. We show that our synthetic augmentation strategy provides high quality data, leading to a challenging new dataset well-suited for IDC named Syned1.
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
Dec 19, 2024



Encoder-only transformer models such as BERT offer a great performance-size tradeoff for retrieval and classification tasks with respect to larger decoder-only models. Despite being the workhorse of numerous production pipelines, there have been limited Pareto improvements to BERT since its release. In this paper, we introduce ModernBERT, bringing modern model optimizations to encoder-only models and representing a major Pareto improvement over older encoders. Trained on 2 trillion tokens with a native 8192 sequence length, ModernBERT models exhibit state-of-the-art results on a large pool of evaluations encompassing diverse classification tasks and both single and multi-vector retrieval on different domains (including code). In addition to strong downstream performance, ModernBERT is also the most speed and memory efficient encoder and is designed for inference on common GPUs.
Distinctive Image Captioning: Leveraging Ground Truth Captions in CLIP Guided Reinforcement Learning
Feb 21, 2024


Training image captioning models using teacher forcing results in very generic samples, whereas more distinctive captions can be very useful in retrieval applications or to produce alternative texts describing images for accessibility. Reinforcement Learning (RL) allows to use cross-modal retrieval similarity score between the generated caption and the input image as reward to guide the training, leading to more distinctive captions. Recent studies show that pre-trained cross-modal retrieval models can be used to provide this reward, completely eliminating the need for reference captions. However, we argue in this paper that Ground Truth (GT) captions can still be useful in this RL framework. We propose a new image captioning model training strategy that makes use of GT captions in different ways. Firstly, they can be used to train a simple MLP discriminator that serves as a regularization to prevent reward hacking and ensures the fluency of generated captions, resulting in a textual GAN setup extended for multimodal inputs. Secondly, they can serve as additional trajectories in the RL strategy, resulting in a teacher forcing loss weighted by the similarity of the GT to the image. This objective acts as an additional learning signal grounded to the distribution of the GT captions. Thirdly, they can serve as strong baselines when added to the pool of captions used to compute the proposed contrastive reward to reduce the variance of gradient estimate. Experiments on MS-COCO demonstrate the interest of the proposed training strategy to produce highly distinctive captions while maintaining high writing quality.
"Honey, Tell Me What's Wrong", Global Explanation of Textual Discriminative Models through Cooperative Generation
Oct 27, 2023



The ubiquity of complex machine learning has raised the importance of model-agnostic explanation algorithms. These methods create artificial instances by slightly perturbing real instances, capturing shifts in model decisions. However, such methods rely on initial data and only provide explanations of the decision for these. To tackle these problems, we propose Therapy, the first global and model-agnostic explanation method adapted to text which requires no input dataset. Therapy generates texts following the distribution learned by a classifier through cooperative generation. Because it does not rely on initial samples, it allows to generate explanations even when data is absent (e.g., for confidentiality reasons). Moreover, conversely to existing methods that combine multiple local explanations into a global one, Therapy offers a global overview of the model behavior on the input space. Our experiments show that although using no input data to generate samples, Therapy provides insightful information about features used by the classifier that is competitive with the ones from methods relying on input samples and outperforms them when input samples are not specific to the studied model.
Three Bricks to Consolidate Watermarks for Large Language Models
Jul 26, 2023The task of discerning between generated and natural texts is increasingly challenging. In this context, watermarking emerges as a promising technique for ascribing generated text to a specific model. It alters the sampling generation process so as to leave an invisible trace in the generated output, facilitating later detection. This research consolidates watermarks for large language models based on three theoretical and empirical considerations. First, we introduce new statistical tests that offer robust theoretical guarantees which remain valid even at low false-positive rates (less than 10$^{\text{-6}}$). Second, we compare the effectiveness of watermarks using classical benchmarks in the field of natural language processing, gaining insights into their real-world applicability. Third, we develop advanced detection schemes for scenarios where access to the LLM is available, as well as multi-bit watermarking.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Which Discriminator for Cooperative Text Generation?
Apr 25, 2022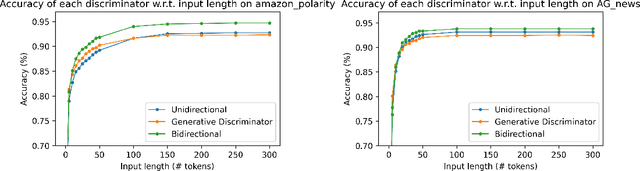

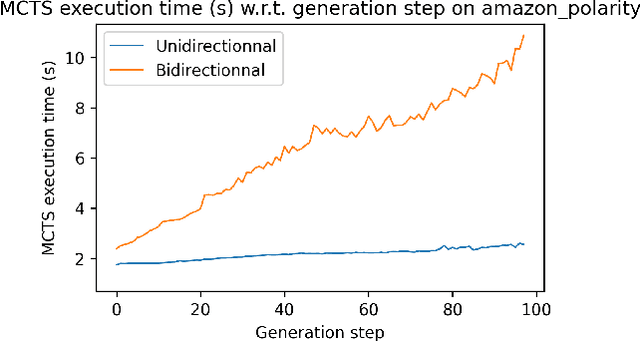
Language models generate texts by successively predicting probability distributions for next tokens given past ones. A growing field of interest tries to leverage external information in the decoding process so that the generated texts have desired properties, such as being more natural, non toxic, faithful, or having a specific writing style. A solution is to use a classifier at each generation step, resulting in a cooperative environment where the classifier guides the decoding of the language model distribution towards relevant texts for the task at hand. In this paper, we examine three families of (transformer-based) discriminators for this specific task of cooperative decoding: bidirectional, left-to-right and generative ones. We evaluate the pros and cons of these different types of discriminators for cooperative generation, exploring respective accuracy on classification tasks along with their impact on the resulting sample quality and computational performances. We also provide the code of a batched implementation of the powerful cooperative decoding strategy used for our experiments, the Monte Carlo Tree Search, working with each discriminator for Natural Language Generation.