 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvocable APIs derived from NL2SQL datasets for LLM Tool-Calling Evaluation
Jun 12, 2025Large language models (LLMs) are routinely deployed as agentic systems, with access to tools that interact with live environments to accomplish tasks. In enterprise deployments these systems need to interact with API collections that can be extremely large and complex, often backed by databases. In order to create datasets with such characteristics, we explore how existing NL2SQL (Natural Language to SQL query) datasets can be used to automatically create NL2API datasets. Specifically, this work describes a novel data generation pipeline that exploits the syntax of SQL queries to construct a functionally equivalent sequence of API calls. We apply this pipeline to one of the largest NL2SQL datasets, BIRD-SQL to create a collection of over 2500 APIs that can be served as invocable tools or REST-endpoints. We pair natural language queries from BIRD-SQL to ground-truth API sequences based on this API pool. We use this collection to study the performance of 10 public LLMs and find that all models struggle to determine the right set of tools (consisting of tasks of intent detection, sequencing with nested function calls, and slot-filling). We find that models have extremely low task completion rates (7-47 percent - depending on the dataset) which marginally improves to 50 percent when models are employed as ReACT agents that interact with the live API environment. The best task completion rates are far below what may be required for effective general-use tool-calling agents, suggesting substantial scope for improvement in current state-of-the-art tool-calling LLMs. We also conduct detailed ablation studies, such as assessing the impact of the number of tools available as well as the impact of tool and slot-name obfuscation. We compare the performance of models on the original SQL generation tasks and find that current models are sometimes able to exploit SQL better than APIs.
New Tools are Needed for Tracking Adherence to AI Model Behavioral Use Clauses
May 28, 2025



Foundation models have had a transformative impact on AI. A combination of large investments in research and development, growing sources of digital data for training, and architectures that scale with data and compute has led to models with powerful capabilities. Releasing assets is fundamental to scientific advancement and commercial enterprise. However, concerns over negligent or malicious uses of AI have led to the design of mechanisms to limit the risks of the technology. The result has been a proliferation of licenses with behavioral-use clauses and acceptable-use-policies that are increasingly being adopted by commonly used families of models (Llama, Gemma, Deepseek) and a myriad of smaller projects. We created and deployed a custom AI licenses generator to facilitate license creation and have quantitatively and qualitatively analyzed over 300 customized licenses created with this tool. Alongside this we analyzed 1.7 million models licenses on the HuggingFace model hub. Our results show increasing adoption of these licenses, interest in tools that support their creation and a convergence on common clause configurations. In this paper we take the position that tools for tracking adoption of, and adherence to, these licenses is the natural next step and urgently needed in order to ensure they have the desired impact of ensuring responsible use.
Training with Pseudo-Code for Instruction Following
May 23, 2025Despite the rapid progress in the capabilities of Large Language Models (LLMs), they continue to have difficulty following relatively simple, unambiguous instructions, especially when compositions are involved. In this paper, we take inspiration from recent work that suggests that models may follow instructions better when they are expressed in pseudo-code. However, writing pseudo-code programs can be tedious and using few-shot demonstrations to craft code representations for use in inference can be unnatural for non-expert users of LLMs. To overcome these limitations, we propose fine-tuning LLMs with instruction-tuning data that additionally includes instructions re-expressed in pseudo-code along with the final response. We evaluate models trained using our method on $11$ publicly available benchmarks comprising of tasks related to instruction-following, mathematics, and common-sense reasoning. We conduct rigorous experiments with $5$ different models and find that not only do models follow instructions better when trained with pseudo-code, they also retain their capabilities on the other tasks related to mathematical and common sense reasoning. Specifically, we observe a relative gain of $3$--$19$% on instruction-following benchmark, and an average gain of upto 14% across all tasks.
Spotlight Your Instructions: Instruction-following with Dynamic Attention Steering
May 17, 2025



In many real-world applications, users rely on natural language instructions to guide large language models (LLMs) across a wide range of tasks. These instructions are often complex, diverse, and subject to frequent change. However, LLMs do not always attend to these instructions reliably, and users lack simple mechanisms to emphasize their importance beyond modifying prompt wording or structure. To address this, we present an inference-time method that enables users to emphasize specific parts of their prompt by steering the model's attention toward them, aligning the model's perceived importance of different prompt tokens with user intent. Unlike prior approaches that are limited to static instructions, require significant offline profiling, or rely on fixed biases, we dynamically update the proportion of model attention given to the user-specified parts--ensuring improved instruction following without performance degradation. We demonstrate that our approach improves instruction following across a variety of tasks involving multiple instructions and generalizes across models of varying scales.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
Reducing the Scope of Language Models with Circuit Breakers
Oct 28, 2024Language models are now deployed in a wide variety of user-facing applications, often for specific purposes like answering questions about documentation or acting as coding assistants. As these models are intended for particular purposes, they should not be able to answer irrelevant queries like requests for poetry or questions about physics, or even worse, queries that can only be answered by humans like sensitive company policies. Instead we would like them to only answer queries corresponding to desired behavior and refuse all other requests, which we refer to as scoping. We find that, despite the use of system prompts, two representative language models can be poorly scoped and respond to queries they should not be addressing. We then conduct a comprehensive empirical evaluation of methods which could be used for scoping the behavior of language models. Among many other results, we show that a recently-proposed method for general alignment, Circuit Breakers (CB), can be adapted to scope language models to very specific tasks like sentiment analysis or summarization or even tasks with finer-grained scoping (e.g. summarizing only news articles). When compared to standard methods like fine-tuning or preference learning, CB is more robust both for out of distribution tasks, and to adversarial prompting techniques. We also show that layering SFT and CB together often results in the best of both worlds: improved performance only on relevant queries, while rejecting irrelevant ones.
Evaluating the Instruction-following Abilities of Language Models using Knowledge Tasks
Oct 16, 2024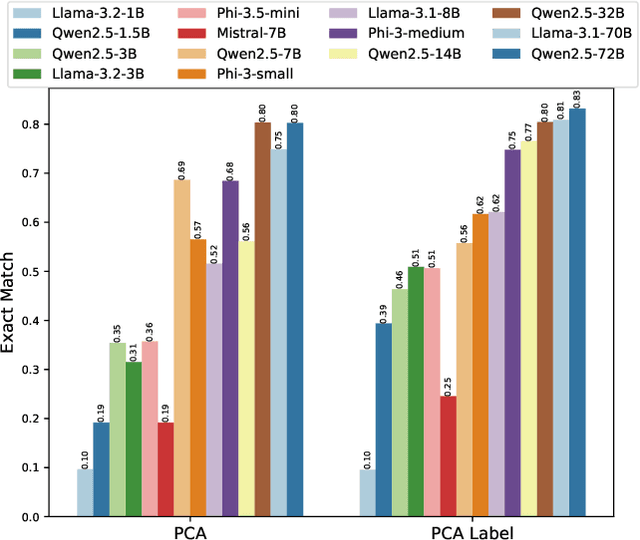
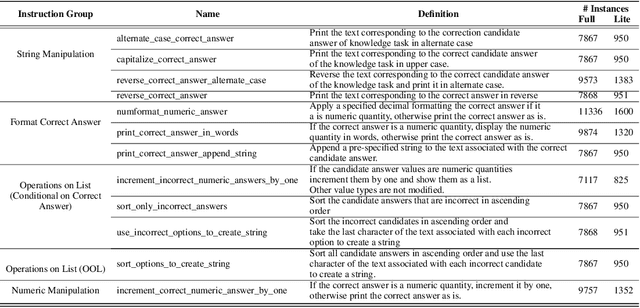
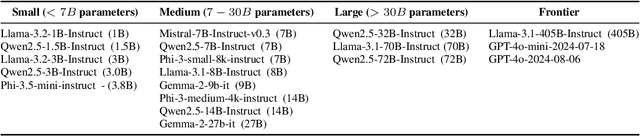
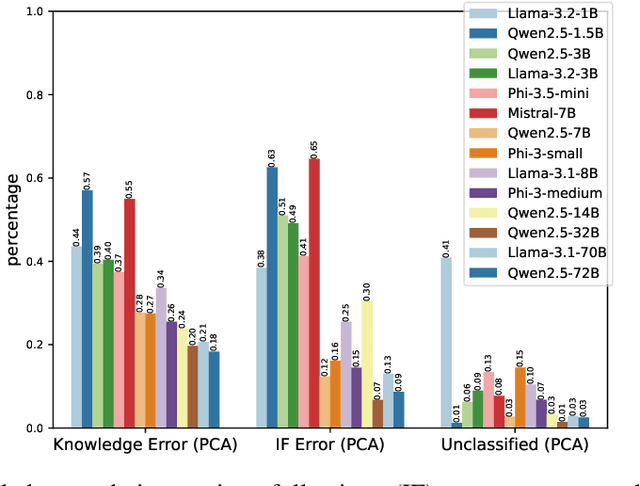
In this work, we focus our attention on developing a benchmark for instruction-following where it is easy to verify both task performance as well as instruction-following capabilities. We adapt existing knowledge benchmarks and augment them with instructions that are a) conditional on correctly answering the knowledge task or b) use the space of candidate options in multiple-choice knowledge-answering tasks. This allows us to study model characteristics, such as their change in performance on the knowledge tasks in the presence of answer-modifying instructions and distractor instructions. In contrast to existing benchmarks for instruction following, we not only measure instruction-following capabilities but also use LLM-free methods to study task performance. We study a series of openly available large language models of varying parameter sizes (1B-405B) and closed source models namely GPT-4o-mini, GPT-4o. We find that even large-scale instruction-tuned LLMs fail to follow simple instructions in zero-shot settings. We release our dataset, the benchmark, code, and results for future work.
Multi-Document Grounded Multi-Turn Synthetic Dialog Generation
Sep 17, 2024



We introduce a technique for multi-document grounded multi-turn synthetic dialog generation that incorporates three main ideas. First, we control the overall dialog flow using taxonomy-driven user queries that are generated with Chain-of-Thought (CoT) prompting. Second, we support the generation of multi-document grounded dialogs by mimicking real-world use of retrievers to update the grounding documents after every user-turn in the dialog. Third, we apply LLM-as-a-Judge to filter out queries with incorrect answers. Human evaluation of the synthetic dialog data suggests that the data is diverse, coherent, and includes mostly correct answers. Both human and automatic evaluations of answerable queries indicate that models fine-tuned on synthetic dialogs consistently out-perform those fine-tuned on existing human generated training data across four publicly available multi-turn document grounded benchmark test sets.
On the Standardization of Behavioral Use Clauses and Their Adoption for Responsible Licensing of AI
Feb 07, 2024Growing concerns over negligent or malicious uses of AI have increased the appetite for tools that help manage the risks of the technology. In 2018, licenses with behaviorial-use clauses (commonly referred to as Responsible AI Licenses) were proposed to give developers a framework for releasing AI assets while specifying their users to mitigate negative applications. As of the end of 2023, on the order of 40,000 software and model repositories have adopted responsible AI licenses licenses. Notable models licensed with behavioral use clauses include BLOOM (language) and LLaMA2 (language), Stable Diffusion (image), and GRID (robotics). This paper explores why and how these licenses have been adopted, and why and how they have been adapted to fit particular use cases. We use a mixed-methods methodology of qualitative interviews, clustering of license clauses, and quantitative analysis of license adoption. Based on this evidence we take the position that responsible AI licenses need standardization to avoid confusing users or diluting their impact. At the same time, customization of behavioral restrictions is also appropriate in some contexts (e.g., medical domains). We advocate for ``standardized customization'' that can meet users' needs and can be supported via tooling.
Prompting with Pseudo-Code Instructions
May 22, 2023



Prompting with natural language instructions has recently emerged as a popular method of harnessing the capabilities of large language models. Given the inherent ambiguity present in natural language, it is intuitive to consider the possible advantages of prompting with less ambiguous prompt styles, such as the use of pseudo-code. In this paper we explore if prompting via pseudo-code instructions helps improve the performance of pre-trained language models. We manually create a dataset of pseudo-code prompts for 132 different tasks spanning classification, QA and generative language tasks, sourced from the Super-NaturalInstructions dataset. Using these prompts along with their counterparts in natural language, we study their performance on two LLM families - BLOOM and CodeGen. Our experiments show that using pseudo-code instructions leads to better results, with an average increase (absolute) of 7-16 points in F1 scores for classification tasks and an improvement (relative) of 12-38% in aggregate ROUGE-L scores across all tasks. We include detailed ablation studies which indicate that code comments, docstrings, and the structural clues encoded in pseudo-code all contribute towards the improvement in performance. To the best of our knowledge our work is the first to demonstrate how pseudo-code prompts can be helpful in improving the performance of pre-trained LMs.