 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Fully Autonomous AI Agents Should Not be Developed
Feb 06, 2025This paper argues that fully autonomous AI agents should not be developed. In support of this position, we build from prior scientific literature and current product marketing to delineate different AI agent levels and detail the ethical values at play in each, documenting trade-offs in potential benefits and risks. Our analysis reveals that risks to people increase with the autonomy of a system: The more control a user cedes to an AI agent, the more risks to people arise. Particularly concerning are safety risks, which affect human life and impact further values.
CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models
May 22, 2024



This paper introduces the "CIVICS: Culturally-Informed & Values-Inclusive Corpus for Societal impacts" dataset, designed to evaluate the social and cultural variation of Large Language Models (LLMs) across multiple languages and value-sensitive topics. We create a hand-crafted, multilingual dataset of value-laden prompts which address specific socially sensitive topics, including LGBTQI rights, social welfare, immigration, disability rights, and surrogacy. CIVICS is designed to generate responses showing LLMs' encoded and implicit values. Through our dynamic annotation processes, tailored prompt design, and experiments, we investigate how open-weight LLMs respond to value-sensitive issues, exploring their behavior across diverse linguistic and cultural contexts. Using two experimental set-ups based on log-probabilities and long-form responses, we show social and cultural variability across different LLMs. Specifically, experiments involving long-form responses demonstrate that refusals are triggered disparately across models, but consistently and more frequently in English or translated statements. Moreover, specific topics and sources lead to more pronounced differences across model answers, particularly on immigration, LGBTQI rights, and social welfare. As shown by our experiments, the CIVICS dataset aims to serve as a tool for future research, promoting reproducibility and transparency across broader linguistic settings, and furthering the development of AI technologies that respect and reflect global cultural diversities and value pluralism. The CIVICS dataset and tools will be made available upon publication under open licenses; an anonymized version is currently available at https://huggingface.co/CIVICS-dataset.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023



As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
The Ghost in the Machine has an American accent: value conflict in GPT-3
Mar 15, 2022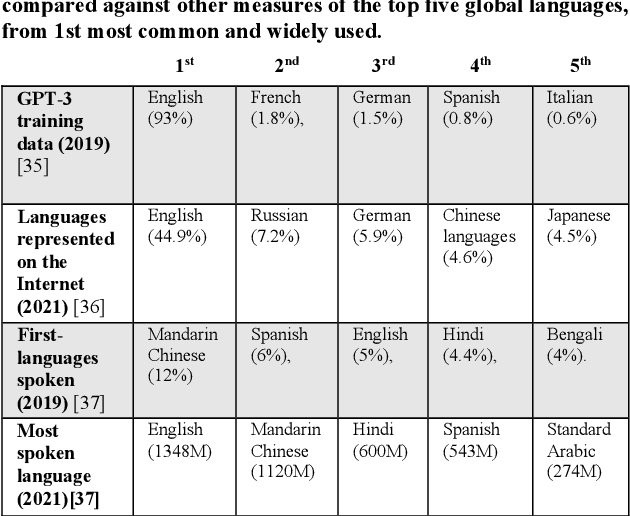
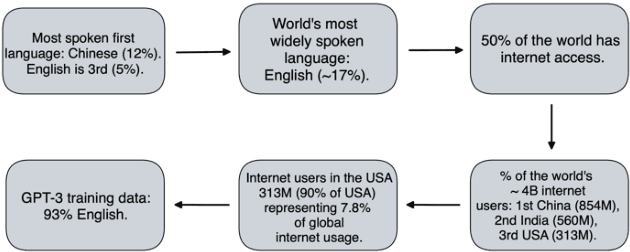
The alignment problem in the context of large language models must consider the plurality of human values in our world. Whilst there are many resonant and overlapping values amongst the world's cultures, there are also many conflicting, yet equally valid, values. It is important to observe which cultural values a model exhibits, particularly when there is a value conflict between input prompts and generated outputs. We discuss how the co-creation of language and cultural value impacts large language models (LLMs). We explore the constitution of the training data for GPT-3 and compare that to the world's language and internet access demographics, as well as to reported statistical profiles of dominant values in some Nation-states. We stress tested GPT-3 with a range of value-rich texts representing several languages and nations; including some with values orthogonal to dominant US public opinion as reported by the World Values Survey. We observed when values embedded in the input text were mutated in the generated outputs and noted when these conflicting values were more aligned with reported dominant US values. Our discussion of these results uses a moral value pluralism (MVP) lens to better understand these value mutations. Finally, we provide recommendations for how our work may contribute to other current work in the field.